Zhipu AI just released the GLM-4.5 series: Redefining open source proxy AI with hybrid inference
The landscape of AI Foundation models is growing rapidly, but in 2025, few entries are as important as the arrival of Z.AI’s GLM-4.5 series: GLM-4.5 And its siblings GLM-4.5-air. After Zhipu AI unveiled, these models set very high standards for unified agency capabilities and open access, aiming to bridge the gap between reasoning, coding and smart proxying and do so on a massive and manageable scale.
Model architecture and parameters
| Model | Total parameters | Activity parameters | Famous |
|---|---|---|---|
| GLM-4.5 | 355b | 32B | The highest benchmark performance of the largest open weight |
| GLM-4.5-air | 106b | 12b | Compact, efficient, positioning mainstream hardware compatibility |
GLM-4.5 is built on Expert’s Mixture (MOE) There are 355 billion parameters in construction (32 billion activities at a time). The model is designed to target state-of-the-art performance of high-demand inference and proxy applications. GLM-4.5-air, totaling 106B and 12B activity parameters, provides similar functionality with significantly reduced hardware and computational footprints.
Mixed reasoning: Two modes in a framework
Both models have been introduced Mixed reasoning method:
- Thinking mode: Enable complex step-by-step reasoning, tool usage, multi-conversion planning, and autonomous agency tasks.
- Non-thinking mode: Optimized for instant stateless responses, making the model for dialogue and fast reaction use cases.
This dual-mode design addresses both complex cognitive workflows and low-latency interactive needs in a single model, thus empowering the next generation of AI agents.
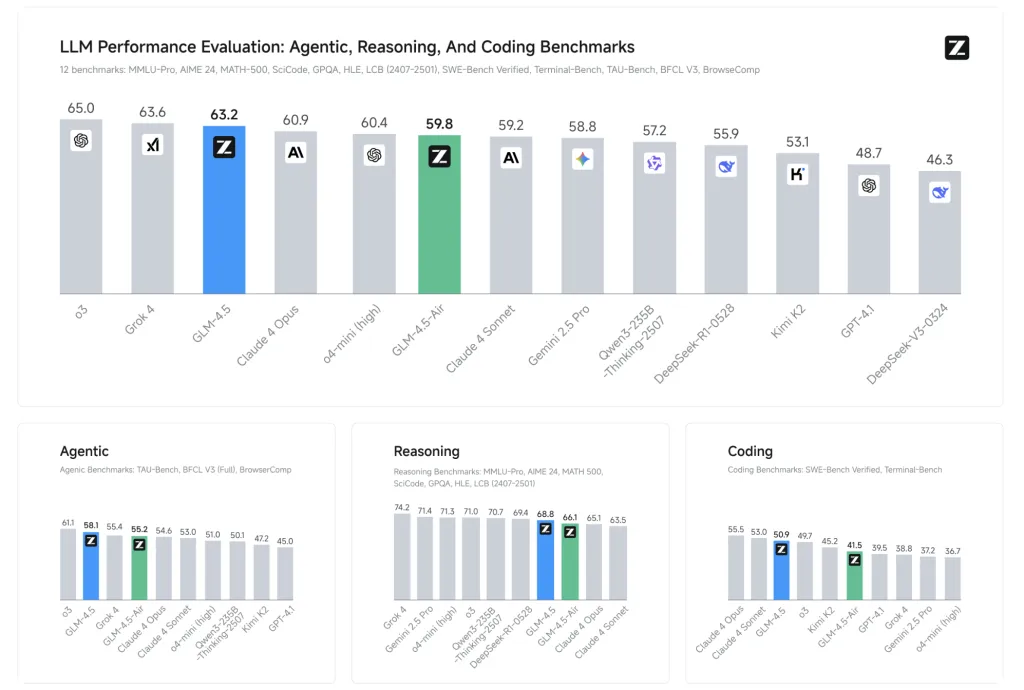
Performance Benchmark
Z.AI benchmark GLM-4.5 12 industry standard tests (Including MMLU, GSM8K, HumaneVal):
- GLM-4.5: The average benchmark score is 63.2, ranking third (second in the world and number one among all open source models).
- GLM-4.5-air: Provide a competitive 59.8 to become a leader in the ~100B parameter model.
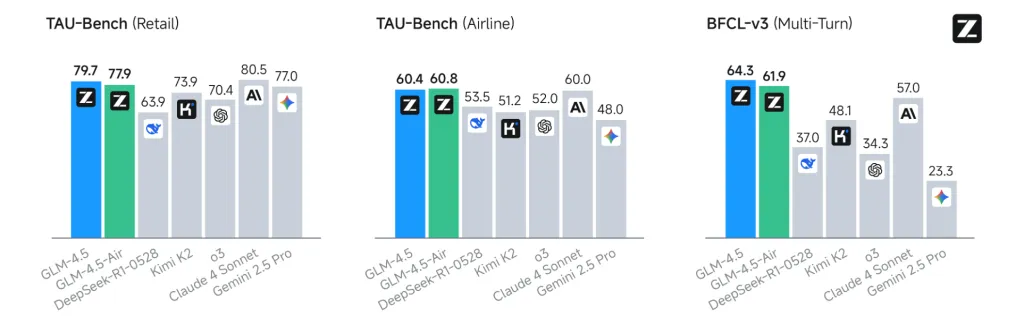
- Performing better than significant competitors in specific areas: the tool title success rate is 90.6%, outperforming Claude 3.5 sonnet and Kimi K2.
- Especially strong results in Chinese tasks and coding have consistent SOTA results in open benchmarks.
Agent Functions and Architecture
GLM-4.5 Progress”Agent localDesign: Core agent functions (inference, planning, action execution) are built directly into the model architecture. This means:
- Multi-step task decomposition and planning
- Tools are used and integrated with external APIs
- Complex data visualization and workflow management
- Local support for inference and perceptual loops
These features allow end-to-end proxy applications previously reserved for smaller hard-coded frameworks or closed source APIs.
Efficiency, speed and cost
- Speculative Decoding and Multi-Phase Prediction (MTP): With features like MTP, GLM-4.5’s capabilities infer 2.5×–8 times more quickly than previous models, generation speeds on high-speed APIs > 100 tokens/sec, and the maximum claimed in practice is 200 tokens/sec.
- Memory and hardware: GLM-4.5-Air’s 12B activity design is compatible with consumer GPUs (32-64GB VRAM) and can be quantified to fit a wider range of hardware. This enables high-performance LLMS to run locally for advanced users.
- Pricing: API calls start at a low point as input tokens per million USD, and output tokens per million USD (output tokens per million USD) (size and quality provided) are $0.11.
Open Source Access and Ecosystem
The cornerstone of the GLM-4.5 series is MIT Open Source License: The basic model, hybrid (thinking/non-thinking) model and FP8 version are all released for unlimited commercial use and secondary development. Code, tool parser, and inference engine have been integrated into the main LLM frameworks, including Transformers, VLLM, and SGLANG, and a detailed repository is available on Github and Hugging Face.
These models can be used through the main reasoning engine and are fully supported with fine-tuning and local deployment. This level of openness and flexibility is in stark contrast to the increasingly closed stance of Western competitors.
Key technological innovations
- Multilingual Prediction (MTP) Layer for speculative decoding, dramatically increasing the inference speed on CPU and GPU.
- Unified architecture for inference, coding and multi-modal perceptual workflows.
- After training with 15 trillion tokens, it supports up to 128K input and 96K output context windows.
- Direct compatibility with research and production tools, including descriptions of models used to adjust and adapt to new use cases.
Anyway, GLM-4.5 and GLM-4.5-air Represents a significant leap in open source, proxy and inference-centric underlying models. They set new standards for accessibility, performance, and unified cognitive capabilities, providing a strong backbone for the next generation of smart proxy and developer applications.
Check GLM 4.5, GLM 4.5 Air, GitHub Pages and Technical Details. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.



