Why context matters: Conversion AI model evaluation using context query
Language model users often ask questions without sufficient details, so it is difficult to understand what they want. For example, a question “What book should I read next?” depends largely on personal taste. At the same time, “How does antibiotics work?” should be answered in different ways based on the user’s background knowledge. Current evaluation methods often ignore this missing context, resulting in inconsistent judgments. For example, the response to complimenting coffee seems good, but it is useless or even harmful to people with health conditions. It is difficult to fairly evaluate the response quality of the model without knowing the user’s intentions or needs.
Previous research focused on generating clarification questions to resolve ambiguity or missing information in tasks such as question and answer, dialogue systems, and information retrieval. These approaches are designed to improve understanding of user intentions. Similarly, studies on follow-up teaching and personalization highlight the importance of responses to user attributes such as expertise, age, or style preferences. Some works also examine how models adapt to various environments and proposed training methods to enhance this adaptability. Furthermore, language model-based evaluators gain appeal due to efficiency, although they may be biased, prompting efforts to improve equity through clearer criteria for evaluation.
Researchers at the University of Pennsylvania, the Allen AI Institute and University of Maryland Park have proposed contextualized assessments. This method adds a comprehensive context (form of subsequent question pairs) to clarify queries specified during language model evaluation. Their research shows that including context can significantly affect assessment results, sometimes even reverse model rankings, while also improving consistency among evaluators. It reduces dependence on superficial traits, such as style, and finds potential biases in default model responses, especially against weird (Western, educated, industrialized, affluent, democratic) environments. This work also shows that the model exhibits different sensitivity to different user environments.
The researchers developed a simple framework to evaluate the performance of language models when giving clearer, contextualized queries. First, they selected unspecified queries from the popular benchmark dataset and enriched them by adding follow-up questions that simulated user-specific context-specific – answers. They then gathered responses from different language models. They have responses from human and model-based evaluators in two settings: one with only the original query and the other with additional context. This allows them to measure how context affects model rankings, evaluator protocols, and the criteria used for judgment. Their setup provides a practical way to test how the model handles real-world ambiguity.
Adding contexts, such as user intentions or audiences, greatly improves model evaluation, in some cases increase ratings consistency by 3-10%, and can even reverse model rankings. For example, GPT-4 is better than Gemini-1.5-Flash when providing context only. Without it, the assessment focuses on tone or fluency, while the context shifts attention to accuracy and help. The default generation usually reflects Western, formal and general biases, thus making them less effective against diverse users. Current benchmarks that ignore context risks can produce unreliable results. To ensure fairness and real-world relevance, the assessment must match context-rich hints with matching ratings that reflect the actual needs of the user.
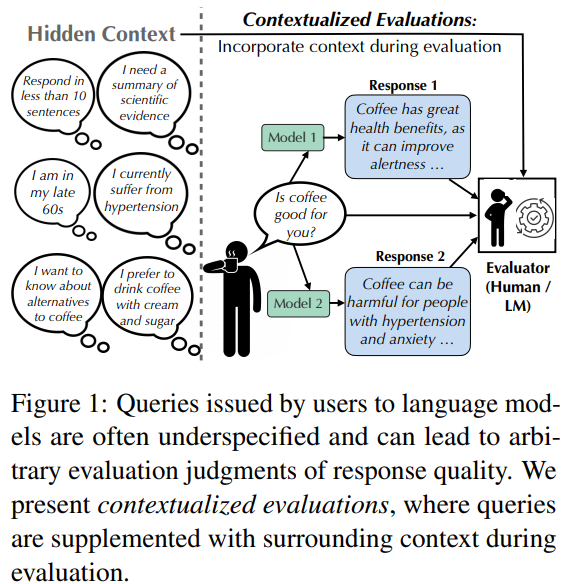
In short, many user queries to language models are vague and lack critical contexts such as user intentions or expertise. This makes the assessment subjective and unreliable. To address this problem, the study proposes a contextual assessment where queries enrich the relevant follow-up questions and answers. This increased context helps shift focus from surface-level features to meaningful criteria, such as useful criteria, and even reverse model rankings. It also reveals potential bias; models usually default to the weird (Western, educated, industrialized, affluent, democratic) assumption. Although the study uses limited context types and relies in part on automatic scoring, it provides a powerful case for context-aware assessments in future work.
Check Paper,,,,, Code,,,,, Dataset and blog. All credits for this study are to the researchers on the project. Subscribe now To our AI newsletter
Sana Hassan, a consulting intern at Marktechpost and a dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. He is very interested in solving practical problems, and he brings a new perspective to the intersection of AI and real-life solutions.



