What is Olmoasr, how does it compare to Openai’s whisper in speech recognition?
Allen AI Institute (AI2) has been released Olmoasran open set Automatic speech recognition (ASR) A model that competes with closed source systems such as Openai’s Whisper. In addition to publishing model weights, AI2 also releases training data identifiers, filtering steps, training recipes and benchmark scripts, which is an unusually transparent move in the ASR field. This makes Olmoasr one of the most popular and extensive platforms for speech recognition research.
Why open automatic speech recognition ASR?
Most of the speech recognition models available today, whether from OpenAI, Google, or Microsoft, are accessible via the API. Although these services provide high performance, they are Black box: The training dataset is opaque, the filtering method is undocumented, and the evaluation protocol is not always consistent with the research criteria.
This lack of transparency presents challenges for repeatability and scientific advancement. Researchers cannot verify claims without rebuilding the large dataset itself, test changes or adjust the model to new areas. Olmoasr solves this problem by opening the entire pipeline. This version involves not only practical transcription, but also Pushing ASR to a more open scientific foundation.
Model architecture and scaling
Olmoasr uses a Transformer Encoder – Secondary Architecturethe main paradigm in modern ASR.
- this Encoder Take in audio waveforms and produce hidden representations.
- this Decoder Generates a text token for conditional conditions on the encoder output.
This design is similar to a whisper, but Olmoasr makes the implementation completely open.
The model family covers six sizes, all of which are trained in English:
- Tiny.en – 39 million parameters, designed for lightweight reasoning
- base.en – 74 million parameters
- Small – 244m parameter
- medium – 769m parameter
- Large EN-V1 – 1.5B parameters, after 440k hours of training
- Large EN-V2 – 1.5B parameters, after 680k hours of training
This scope allows developers to trade off between inference cost and accuracy. Smaller models are suitable for embedded devices or real-time transcription, while larger models maximize the accuracy of research or batch workloads.
Data: From network scratches to selected mixes
One of Olmoasr’s core contributions is Open release of training datasetsnot just a model.
Olmoasr-Pool (~3m hours)
This huge collection contains weakly supervised voice and pairs transcripts scraped off the web. It includes the surrounding 3 million hours of audio and 17 million text transcripts. Just like Whisper’s original dataset, it’s noisy and contains misaligned subtitles, duplicates, and transcription errors.
Olmoasr-mix (~1m hours)
In order to solve the quality problem, AI2 has been applied Strict filtering:
- Consistency heuristics Make sure the audio and transcript match
- Fuzzy deletion Examples of removing duplicates or low diversity
- Cleaning rules Eliminate duplicate lines and mismatched text
turn out High-quality 1m-hour dataset This improves Zero elastic summary– It is crucial for practical tasks where data may be different from training distribution.
This two-layer data strategy is reflected in a large-scale language model: scaled with a huge noisy corpus and then filtered subsets to improve for quality.
Performance Benchmark
The AI2 benchmark Olmoasr opposes whispering in short form and long term voice tasks, using such Librispeech, Ted-Lium3, Swendboard, AMI and Voxpopuli.
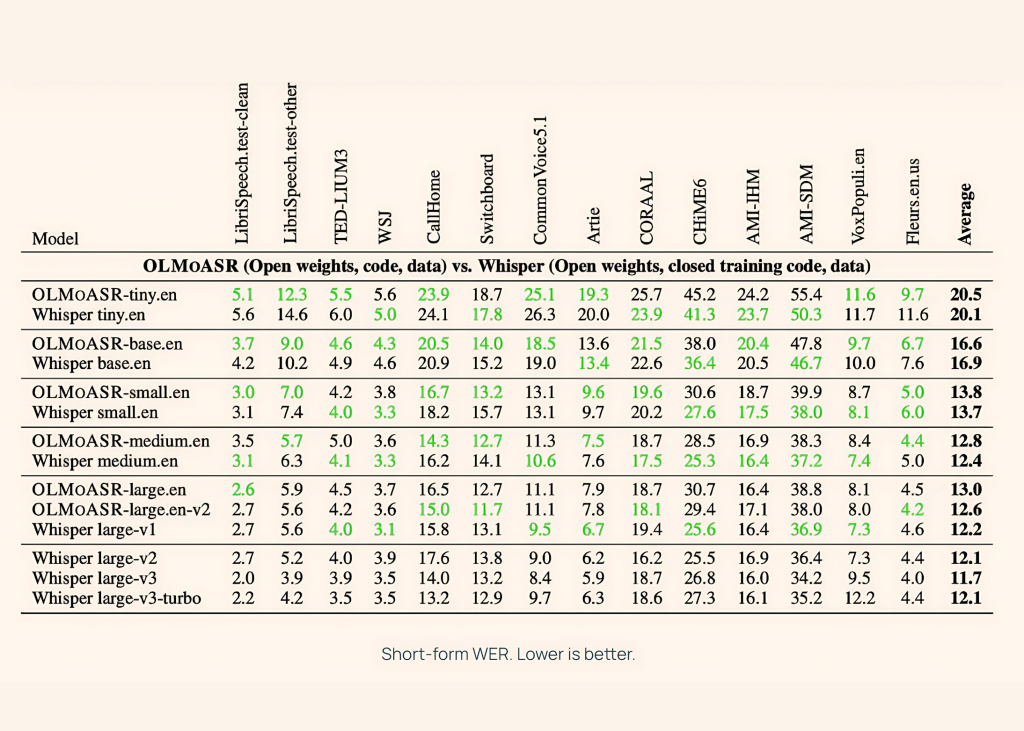
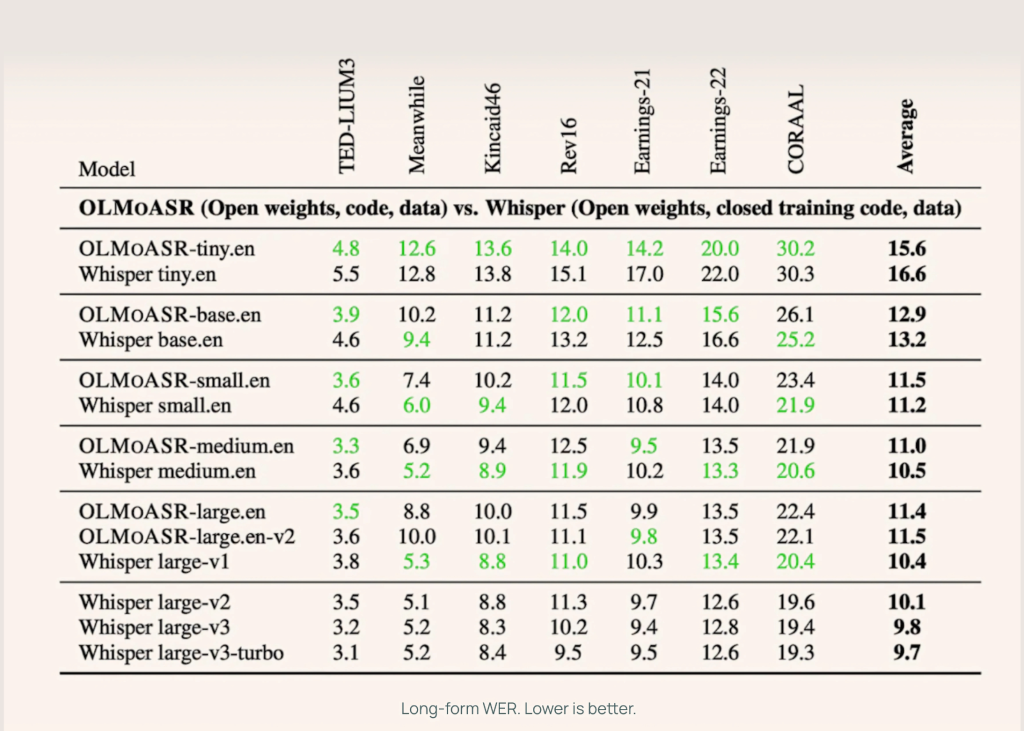
Medium model (769m)
- 12.8% (word error rate) on short form pronunciation
- 11.0% In a long-term speech
This almost matches the whisper. 12.4% and 10.5% respectively.
Large model (1.5b)
- Large EN-V1 (440k hours): 13.0% short form with whisper large size is 12.2%
- Large EN-V2 (680k hours): 12.6% WER, narrowing the gap to less than 0.5%
Smaller models
Even Tiny and according to The version is competitive:
- Tiny.en: ~20.5% short form, ~15.6%
- base.en: ~~16.6% short form, ~12.9% long form
This gives developers the flexibility to select models based on computational and latency requirements.
How to use it?
Transcribing audio requires only a few lines of code:
import olmoasr
model = olmoasr.load_model("medium", inference=True)
result = model.transcribe("audio.mp3")
print(result)
Output includes transcription and Time allocation segmentmaking it available for title, satisfying transcriptional or downstream NLP pipelines.
Fine-tuning and domain adaptation
Since AI2 provides complete training code and recipes, Olmoasr can be Fine-tuning for professional fields:
- Medical speech recognition – Adapt to the model on datasets such as imitation or proprietary hospital recordings
- Legal Translation – Training in court audio or legal proceedings
- Low resource accent – Fine tuning of dialects is not fully covered in Olmoasr-mix
This adaptability is crucial: ASR performance often degrades when the model is used in a dedicated domain with a specific domain specific jargon. Open pipelines directly adapt to the adaptability of the domain.
Apply
Olmoasr opens up exciting opportunities in academic research and real-world AI development:
- Educational Research: Researchers can explore the complex relationship between model architecture, dataset quality, and filtering techniques to understand their impact on speech recognition performance.
- Human computer interaction: Developers are free to embed speech recognition capabilities directly into conversational AI systems, real-time conference transcription platforms, and accessibility applications without relying on proprietary APIs or external services.
- Multimodal AI development: When used in conjunction with large language models, Olmoasr can create advanced multimodal assistants that seamlessly process spoken input and produce intelligent, context-aware responses.
- Research benchmarks: Public availability of training data and evaluation metrics position OlmoASR as a standardized reference point, allowing researchers to compare new approaches to reproducible baselines consistent with future ASR studies.
in conclusion
The launch of Olmoasr brings high-quality voice recognition that can be developed and published in a way that prioritizes transparency and repeatability. Although these models are currently limited to English only, they still require a lot of training calculations, they provide a solid foundation for adaptation and expansion. This release sets a clear point of reference for future work in open ASR and makes it easier for researchers and developers to study, benchmark and apply speech recognition models.
Check Model embracing face, github page and Technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
: Using small-scale reinforcement learning to effectively refine reasoning in LLM")

