VL-COGITO: Advancing multimodal reasoning through progressive course reinforcement learning
Multimodal reasoning, where models integrate and interpret information from multiple sources such as text, images, and charts, is a boundary challenge in AI. VL-Cogito is the most advanced multi-modal large language model (MLLM) and partner proposed by Damo Academy (Alibaba Group), introducing a powerful reinforcement learning pipeline that fundamentally upgrades the inference skills across large models with math, science, logic, charting and general understanding.
Core innovation
VL-Cogito’s unique approach to surround Progressive Course Enhanced Learning (PCURL) The framework is designed to systematically overcome the instability and domain gaps of multimodal reasoning. The framework includes two groundbreaking innovations:
- Online Difficulty Soft Weighting (ODSW): This mechanism assigns dynamic weights to the difficulty of training samples and the constantly evolving functions of the model. Instead of strictly filtering “simple” or “hard” samples, ODSW ensures that each prompt properly contributes gradient updates, allowing the model to go from clear situations to complex, challenging challenges through continuous lessons. The three variants adjust the focus by segmented functions based on deduction accuracy, guided by the empirical distribution of learning theory and task difficulty.
- Dynamic Length Reward (DYLR): Traditional length rewards in RL-based inference models set a static goal that fails to take into account task complexity and encourages unnecessary verboseness. DYLR solves this problem by calculating the ideal target length for each prompt, which is estimated by the average length of the correct ejection sample for each problem. Promote short, fast reasoning for simple tasks, while complex tasks motivate deeper, multi-step exploration, perfectly balance efficiency and correctness.
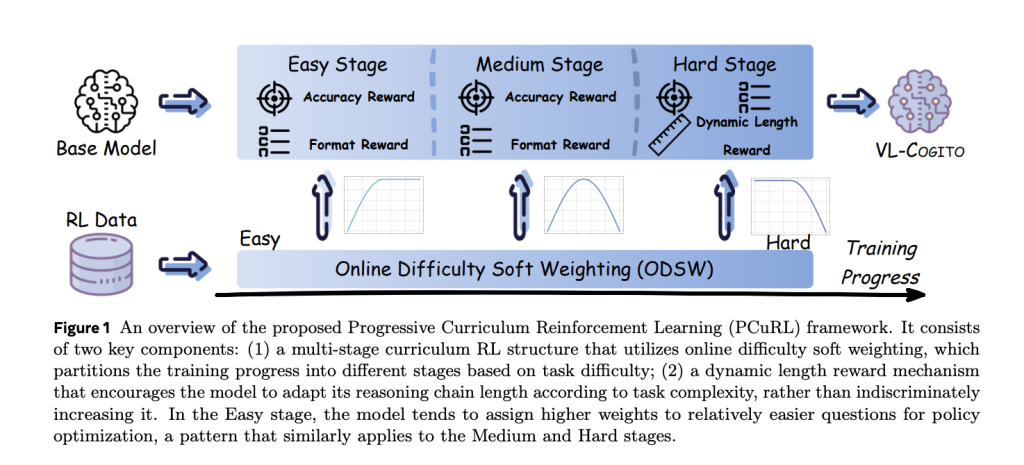
Training pipeline
VL-COGITO’s post-RL training training starts directly from the QWEN2.5-VL-INSTRUCT-7B main chain with Fine-tuning (SFT) cold start without initial supervision Required. The PCURL process is clearly divided into three sequential RL phases: easy, medium and hard. At each stage:
- The same datasets are shuffled, bringing the model to various generalization challenges.
- ODSW’s weighting function For this stage, gradient updates tend to be target difficulty.
- During the difficult stage, DYLR is triggered to encourage expansion of adaptive reasoning chains.
Technical settings details:
- ADAMW Optimizer, LR = 1E-6, DeepSpeed-Zero3.
- Launched batch size: 512; Global batch size: 128; Sequence length: 4,096; KL differential loss: 1E-3; 16 response samples per prompt; Temperature: 1.0.
- Reward hyperparameters: α= 1, β= 0.5, γ= 1, w= 0.25 (finite for zero accurate prompt).
Dataset planning and RL data sampling
The carefully planned training set covers 23 open source multimodal datasets in six task categories: Mathematical reasoning, logical reasoning, counting, scientific reasoning, chart understanding and general image understanding.
- All samples have been redesigned to an open quality inspection format to prevent surface multiple selection prompts for exploitation.
- Sampling difficulty: QWEN2.5-VL-7B-r-Instruct was tested; any sample with an accuracy of ≥50% in 8 runs will be deleted to ensure that only truly challenging tasks are retained.
Evaluation and benchmark results
Cross-benchmark performance
VL-Cogito benchmarks general and reasoning-oriented MLLM on the Ten Task Panel, including Geometry @3K, Mathverse, Mathverse, Mathverse, Mathverse, Mathversa, Chartvista, ChartVista, ChartQA, ScienceQA, MMMU, Emma, and Mmstar.
- Absolute accuracy On the backbone: Geometric @3K +7.6%, MathVista +5.5%, Logicvista +4.9%, ScienceQA +2.2%, Emma +4.5%, MMSTAR +3.8%.
- Latest results for the 6/10 benchmark: VL-Cogito’s leadership or matching the highest results, especially on rigorous mathematical and scientific tasks. Models that use SFT or force rethinking strategies “cold start” will not exceed their powerful course-based RL.
| Model | geo3k | math | Mathvista | Mathvision | LogicVista | Chartqa | science | Um | Emma | mmstar |
|---|---|---|---|---|---|---|---|---|---|---|
| VL-Cogito (7b) | 68.7 | 53.3 | 74.8 | 30.7 | 48.9 | 83.4 | 87.6 | 52.6 | 29.1 | 66.3 |
| VL-RETHINKER (7b) | 67.7 | 54.6 | 73.7 | 30.1 | 45.7 | 83.5 | 86.7 | 52.9 | 28.6 | 64.2 |
| MM-Eureka (8b) | 67.2 | 52.3 | 73.4 | 29.4 | 47.1 | 82.7 | 86.4 | 52.3 | 27.4 | 64.7 |
| QWEN2.5-VL (7b) | 61.6 | 50.4 | 69.3 | 28.7 | 44.0 | 82.4 | 85.4 | 50.9 | 24.6 | 62.5 |
Ablation of components
- Course RL The average score was increased to the average score of Vanilla GRPO alone +0.8%.
- Dynamic length reward Further improve performance, especially in the field of hard mathematics.
- ODSW Always exceed the performance of binary hard sample filtration, especially when the training data is unbalanced or skewed.
Reasoning efficiency and training dynamics
- Dynamic Rewards The cosine rewards of fixed length produce higher average accuracy and higher token efficiency. Adaptive lengths occur longer for mathematical and logical tasks, and are shorter in science and general understanding.
- The hard phase of PCURL caused a surge in inference length and verification accuracy, exceeding the accuracy of the static output length of the vanilla GRPO in the plateau.
Case study
VL-Cogito demonstrates detailed, step-by-step reasoning of self-reflection. For math, the model breaks down the solution into particle chains and actively corrects the error steps, which are behaviors instilled through RL validation and advantage estimation[1, Figure 5]. Regarding the classification question (e.g., identifying a decomposer or skyscraper in an image), it methodically considers each option before boxing an answer and demonstrates a strong multimodal understanding and process reliability.

Insights and Influences
VL-Cogito’s system PCURL pipeline verifies several key insights:
- Learnability is important: The prompt has the prompt of intermediate difficulty, and the optimization model is the best progress.
- Exposed to challenge catalyzing deep reasoning: Overemphasis on simple samples will degrade performance; incremental emphasis on harder samples will create lasting depth of analysis.
- Reward granularity is crucial: Combining correctness, format and length helps with subtle context-sensitive inference output.
- Sft-free cold start RL is feasible and very effective: With PCURL, the model does not have to rely on expensive SFT warm-ups.
in conclusion
VL-Cogito’s architecture and training innovation sets new standards for multimodal reasoning across different benchmarks. Design and empirical validation of progressive course RL with dynamic length rewards point to a general roadmap for powerful reasoning in multiple models.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.


