Using IBM’s open source AI model Granite-3B and embracing Face Transformers’ coding guide for sentiment analysis of customer reviews

In this tutorial, we will look at how to easily perform sentiment analysis of text data using IBM’s open source granite 3B models that are integrated with a hug-face transformer. Sentiment analysis is a widely used natural language processing (NLP) technology that helps quickly identify emotions expressed in texts. It makes businesses designed to understand customer feedback and enhance their products and services invaluable. Now let’s classify and visualize the emotions by installing the necessary libraries, loading the IBM granite model, classifying and visualizing the results, which is effortlessly performed in Google Colab.
!pip install transformers torch accelerateFirst, we will install the base library (Transformers, Torch and Acgelerate) to seamlessly load and run powerful NLP models. Transformers provides pre-built NLP models, Torch is the backend for deep learning tasks and accelerates to ensure efficient resource utilization on the GPU.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import pandas as pd
import matplotlib.pyplot as pltWe will then import the required Python library. We will use the torch for efficient tensor operations, transformers for training pre-trained NLP models from the hug surface, pandas for managing and processing data in a structured format, and matplotlib for visually explicit and intuitive interpretation of the analysis results.
model_id = "ibm-granite/granite-3.0-3b-a800m-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map='auto',
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)Here we will follow the model using AutoTokenizer and AutomodelForCausAllm that embraces Face to load IBM’s open source granite 3B instructions, especially the IBM Granite/Granite-3.0-3B-A800M Instruct. Even under limited computing resources, this compact instruction adjustment model has gone through tasks such as emotional classification directly within COLAB.
def classify_sentiment(review):
prompt = f"""Classify the sentiment of the following review as Positive, Negative, or Neutral.
Review: "{review}"
Sentiment:"""
response = generator(
prompt,
max_new_tokens=5,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
sentiment = response[0]['generated_text'].split("Sentiment:")[-1].split("n")[0].strip()
return sentimentNow, we will define the core function classification_sentiment. This feature leverages the IBM Granite 3B model with instructions-based prompts to classify the emotions of any given comment as positive, negative, or neutral. The function formats input review, calls the model with precise instructions, and extracts generated emotions from the generated text.
import pandas as pd
reviews = [
"I absolutely loved the service! Definitely coming back.",
"The item arrived damaged, very disappointed.",
"Average product. Nothing too exciting.",
"Superb experience, exceeded all expectations!",
"Not worth the money, poor quality."
]
reviews_df = pd.DataFrame(reviews, columns=['review'])Next, we will use pandas to create a simple dataframe comment with a collection of sample comments. These example comments are input data for emotion classification, allowing us to observe how the IBM granite model effectively determines customer sentiment in real-world situations.
reviews_df['sentiment'] = reviews_df['review'].apply(classify_sentiment)
print(reviews_df)After defining a comment, we will apply the classification_sentiment function to each comment in the data frame. This will produce a new column, namely emotion, where the IBM granite model classifies each comment as positive, negative, or neutral. By printing updated comments_DF, we can see the original text and its corresponding emotional classification.
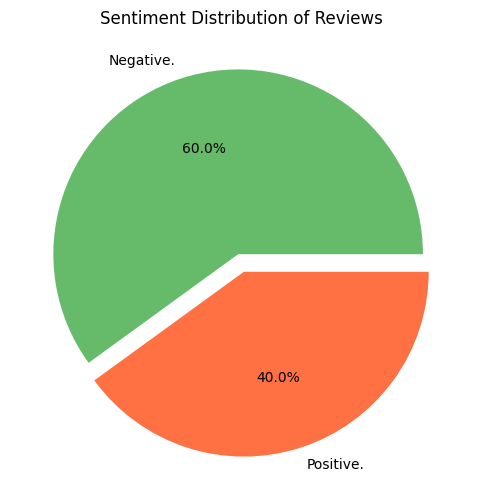
import matplotlib.pyplot as plt
sentiment_counts = reviews_df['sentiment'].value_counts()
plt.figure(figsize=(8, 6))
sentiment_counts.plot.pie(autopct="%1.1f%%", explode=[0.05]*len(sentiment_counts), colors=['#66bb6a', '#ff7043', '#42a5f5'])
plt.ylabel('')
plt.title('Sentiment Distribution of Reviews')
plt.show()
Finally, we will visualize the emotional distribution in the pie chart. This step provides a clear, intuitive overview of how to classify comments, making the overall performance of the model easier. Matplotlib lets us quickly see the proportion of positive, negative and neutral emotions, thus making your emotional analysis pipeline complete circle.
In short, we successfully implemented a powerful sentiment analysis pipeline using IBM’s Granite 3B open source model, which is hosted on the hug surface. You have learned how to quickly classify text into positive, negative, or neutral emotions using pre-trained models, effectively visualizing insights and explaining your findings. This basic approach makes it easy for you to adapt to these skills to analyze datasets or explore other NLP tasks. IBM’s granite model combined with a hug-face transformer provides an effective way to perform advanced NLP tasks.
This is COLAB notebook. Also, don’t forget to follow us twitter And join us Telegram Channel and LinkedIn GrOUP. Don’t forget to join us 80k+ ml subcolumn count.
 Recommended Reading – LG AI Research Unleashes Nexus: An Advanced System Integration Agent AI Systems and Data Compliance Standards to Address Legal Issues in AI Datasets
Recommended Reading – LG AI Research Unleashes Nexus: An Advanced System Integration Agent AI Systems and Data Compliance Standards to Address Legal Issues in AI Datasets
A post coding guide for sentiment analysis of customer comments using IBM’s open source AI models Granite-3B and Hugging Face Transformers first appeared on Marktechpost.


