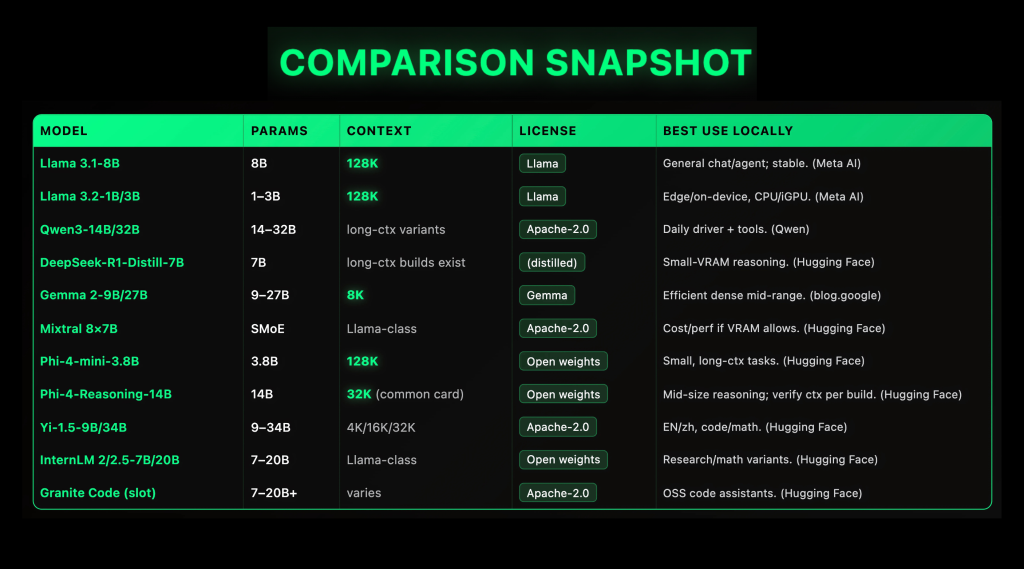
Top 10 local LLMs (2025): context window, VRAM target and license comparison
Local LLMs are rapidly maturing in 2025: Open Weight Homes Llama 3.1 (128K context length (CTX)),,,,, Qwen3 (Apache-2.0, dense + MOE),,,,, Gemma 2 (9b/27b, 8k CTX),,,,, Mix 8×7b (Apache-2.0 Smoe)and PHI-4-MINI (3.8B, 128K CTX) Shipping now with reliable specifications and top-notch local runners (GGUF/llama.cppLM Studio, Ollama), practical on local or even laptop reasoning if you match context length and quantization to VRAM. This guide lists the ten most deployable options listed through license clarity, stable GGUF availability and reproducible performance characteristics (parameters, context length (CTX), QUANT PRESETS).
Top 10 local LLMs (2025)
1) Meta Llama 3.1-8B – Powerful “Daily Driver”, 128K Context
Why is important. A stable multilingual baseline with long context and top-notch support in a local toolchain.
Specification. Dense 8B decoder only; official 128K Context; instruction adjustments and basic variations. Llama license (open weight). Common GGUF builds and Ollama recipes exist. Typical settings: q4_k_m/q5_k_m≤12-16GB VRAM, Q6_K ≥24GB.
2) Meta Llama 3.2-1b/3b – edge level, 128K context, friendly on device
Why is important. Small model still used 128K When quantized, the token and run on the CPU/IGPU; suitable for laptops and mini PCs.
Specification. 1B/3B instruction adjustment model; META confirmed 128K context. Can be passed llama.cpp Multi-ocase stack for GGUF and LM Studio (CPU/CUDA/VULKAN/METAL/ROCM).
3) QWEN3-14B/32B – Open Apache-2.0, powerful tool usage and multilingual
Why is important. Broad family (intensive + MOE) Apache-2.0 There are active community ports to GGUF; extensive coverage is locally competent general/agent “daily driver”.
Specification. 14b/32b dense checkpoint with long cultural variants; modern tokenizer; rapid ecosystem updates. Starting with Q4_K_M, 14B on 12 GB; when you have 24 GB+, move to Q5/Q6. (QWEN)
4) DeepSeek-R1-Distill-Qwen-7b – Suitable compact reasoning
Why is important. Refined from the R1 style reasoning trajectory; deliver step-by-step quality at a speed of 7B and provides widely available GGGUF. Great for math/coding on moderate VRAM.
Specification. 7b dense; there is a novel variant in each conversion; the planned GGUFS covers F32→Q4_K_M. For 8–12 GB VRAM, try Q4_K_M; for 16–24 GB, use Q5/Q6.
5) Google Gemma 2-9b/27b – efficient and dense; 8K context (clear)
Why is important. Strong quality and quantitative behavior; 9B is a great mid-range local model.
Specification. Dense 9b/27b; 8k Context (do not exaggerate); open weights in Gemma terms; extensive packaging llama.cpp/ollama. 9B@Q4_K_M runs on many 12 GB cards.
6) Mix 8×7b (SMOE) – Apache-2.0 Sparse Moe; Cost/perf porthorse
Why is important. The mix of experts is throughput benefits when reasoning: ~2 experts/tokens are selected at runtime; there is a huge compromise when you have ≥24-48GB VRAM (or multiple GPUs) and want stronger general performance.
Specification. 8 experts for 7B (sparse activation); Apache-2.0; Indicator/basic variants; Mature GGGUF conversion and Ollama recipes.
7) Microsoft Phi-4-Mini-3.8b – Small model, 128K context
Why is important. “Small foot print reasoning” with reality 128K Context and grouping concerns; solids are used for CPU/IGPU frames and latent sensitive tools.
Specification. 3.8b density; 200k vocabulary; SFT/DPO alignment; model card documentation 128K Context and training materials. Use Q4_K_M on ≤8–12 GB VRAM.
8) Microsoft Phi-4-curated 14B – Medium Inference (every build CTX)
Why is important. A 14B reasoning-adjusted variant is better for tasks passing through thought chain styles than the general 13–15B benchmark.
Specification. Dense 14b; Context varies by distribution (Model card for general release list 32K). For 24 GB VRAM, Q5_K_M/Q6_K comfort; a hybrid runner (non-gguf) requires more.
9) Yi-1.5-9b/34b – Apache-2.0 bilingual; 4K/16K/32K variant
Why is important. Competitive EN/ZH performance and permitted licensing; 9b is a powerful alternative to Gemma-2-9b; 34B steps toward higher reasoning under Apache-2.0.
Specification. dense; context variant 4K/16K/32K;Open weight under Apache-2.0 with active HF card/repository. For 9B, use Q4/Q5 on 12–16 GB.
10) Internlm 2 / 2.5-7b / 20b – Research to research; branch of mathematical adjustment
Why is important. Open series with lively research rhythms; 7b is a practical local target; 20b moves you to Gemma-2-27b level ability (at higher VRAM).
Specification. Dense 7b/20b; multiple chat/basic/math variants; active HF presence. GGUF conversion and Ollama packages are common.
Summary
In a local LLM, the tradeoffs are clear: dense Predictable latency and simpler quantization models (e.g., Llama 3.1-8b with recorded 128K context; Gemma 2-9b/27b with explicit 8K window), move to Sparse cute Like hybrid 8×7b Small reasoning Model (phi-4-mini-3.8b, 128k) is the best position for CPU/IGPU box. License and ecosystem are as important as original scores: QWEN3’s Apache-2.0 release (intensive + MOE) and Meta/Google/Microsoft model cards provide the operation guardrails (context, tokenizer, usage terms) you actually use. At runtime, standardization GGUF/LLAMA.CPP For portability, Ollama/LM Studio For convenience and hardware offloading, as well as size quantization (Q4→Q6), your memory budget. In short: choose Context + License + Hardware Pathnot just the resonance of the rankings.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


 standardizes AI connections using tools and data")