Thought Anchor: A machine learning framework for identifying and measuring critical inference steps in large language models
Understand the limitations of current interpretability tools in LLM
AI models (such as DeepSeek and GPT variants) all rely on billions of parameters to handle complex inference tasks. Despite its ability, a major challenge is to understand which parts of its reasoning have the greatest impact on the final output. This is especially important for ensuring AI reliability in key areas such as healthcare or finance. Current interpretability tools, such as the importance of token level or gradient-based approaches, provide only limited views. These methods often focus on orphaned components and fail to capture how different inference steps connect and influence decisions, leaving behind key aspects of model logic hidden.
Thought anchor: sentence-level explanatory nature of reasoning paths
Researchers at Duke University and AIPHABET introduced a novel interpretability framework called “Thought anchor. “This method specifically examines sentence-level reasoning to facilitate widespread use, and the researchers developed an accessible, detailed open interface on Thinky-anders.com that supports visualization and comparative analysis of inferences in internal model inference, providing a full coverage of model interpretability.
Evaluation Methods: Benchmarking of DeepSeek and Mathematical Datasets
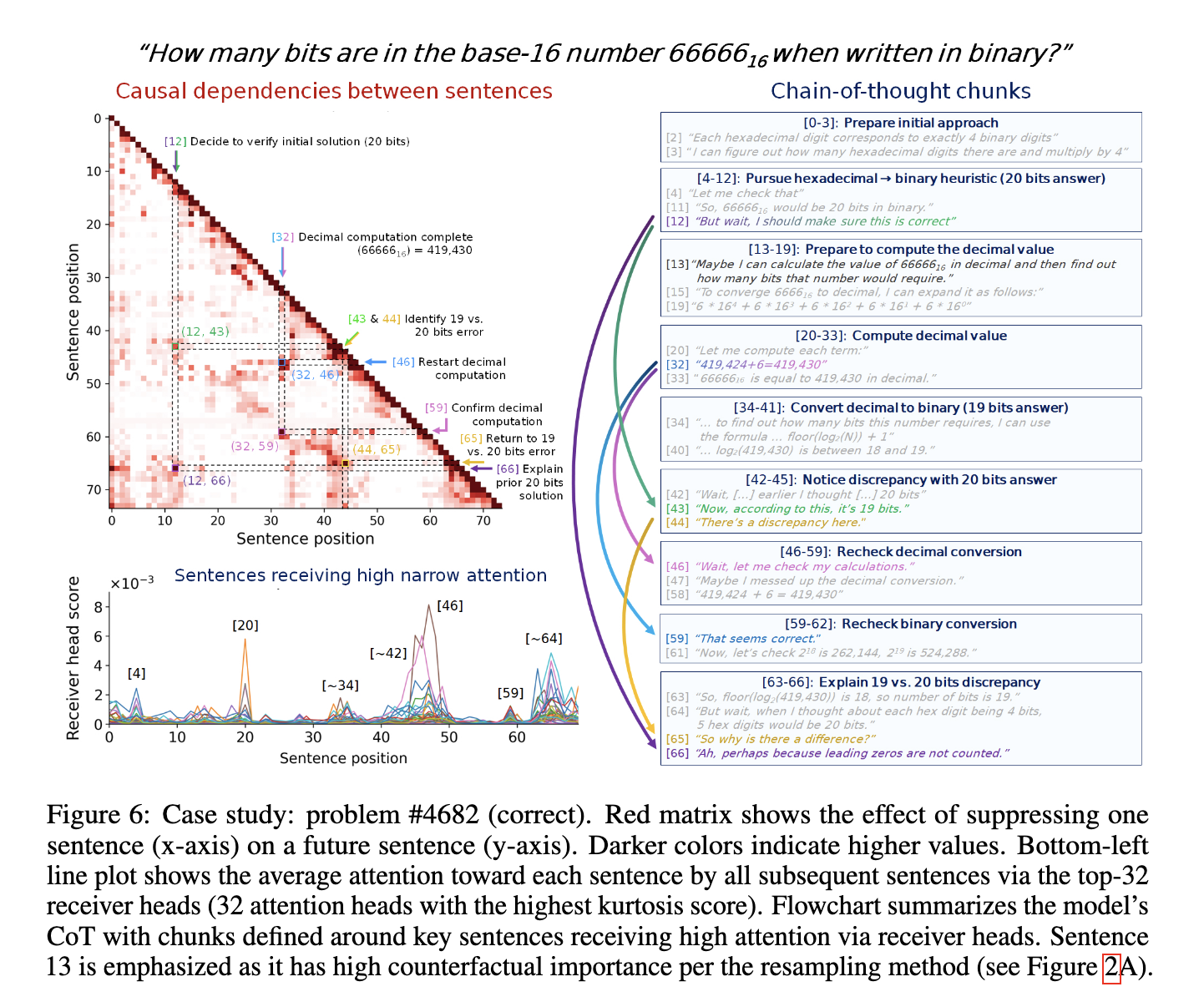
The research team clearly detailed the three interpretability methods in the assessment. The first method is black-frame measurement, using counterfactual analysis by systematically deleting sentences within the inference trace and quantifying their impact. For example, the study demonstrated sentence-level accuracy assessment by analyzing the substantive evaluation dataset, which included 2,000 inference tasks, each producing 19 responses. They used the DeepSeek question and answer model, which has about 67 billion parameters and tested it in a specially designed mathematical dataset with about 12,500 challenging mathematical problems. Second, the receiver head analysis measures attention patterns between sentence pairs, revealing how previous inference steps affect subsequent information processing. The study found obvious directional attention, indicating that certain anchoring sentences significantly guided subsequent reasoning steps. Third, the causal attribution approach evaluates how the effects of inhibiting a particular reasoning step affect subsequent output, thus illuminating the precise contribution of internal reasoning elements. These techniques combined together produce precise analytical outputs and discover clear relationships between inference components.
Quantitative benefits: high precision and clear causal relationship
Applying the idea anchor, the research team demonstrated a significant improvement in interpretability. Black-Box analysis enables powerful performance metrics: For each reasoning step in the evaluation task, the research team observed significant changes in the impact on model accuracy. Specifically, the correct inference path always reaches a precision level of more than 90%, significantly exceeding the incorrect path. Receiver head analysis provides evidence of a strong directional relationship measured by the attention distribution across all layers and attention heads within DeepSeek. These directional attention patterns always guide subsequent inference, with the receiver head showing the relevant score averaged about 0.59 across layers, confirming the ability of interpretability methods to effectively determine influential reasoning steps. Furthermore, causal attribution experiments clearly quantify how the reasoning steps spread their impact. Analysis shows that the causal influence exerted by the initial reasoning sentence leads to observable effects on subsequent sentences, with the average causal influence measure of about 0.34, further consolidating the accuracy of the thought anchor.
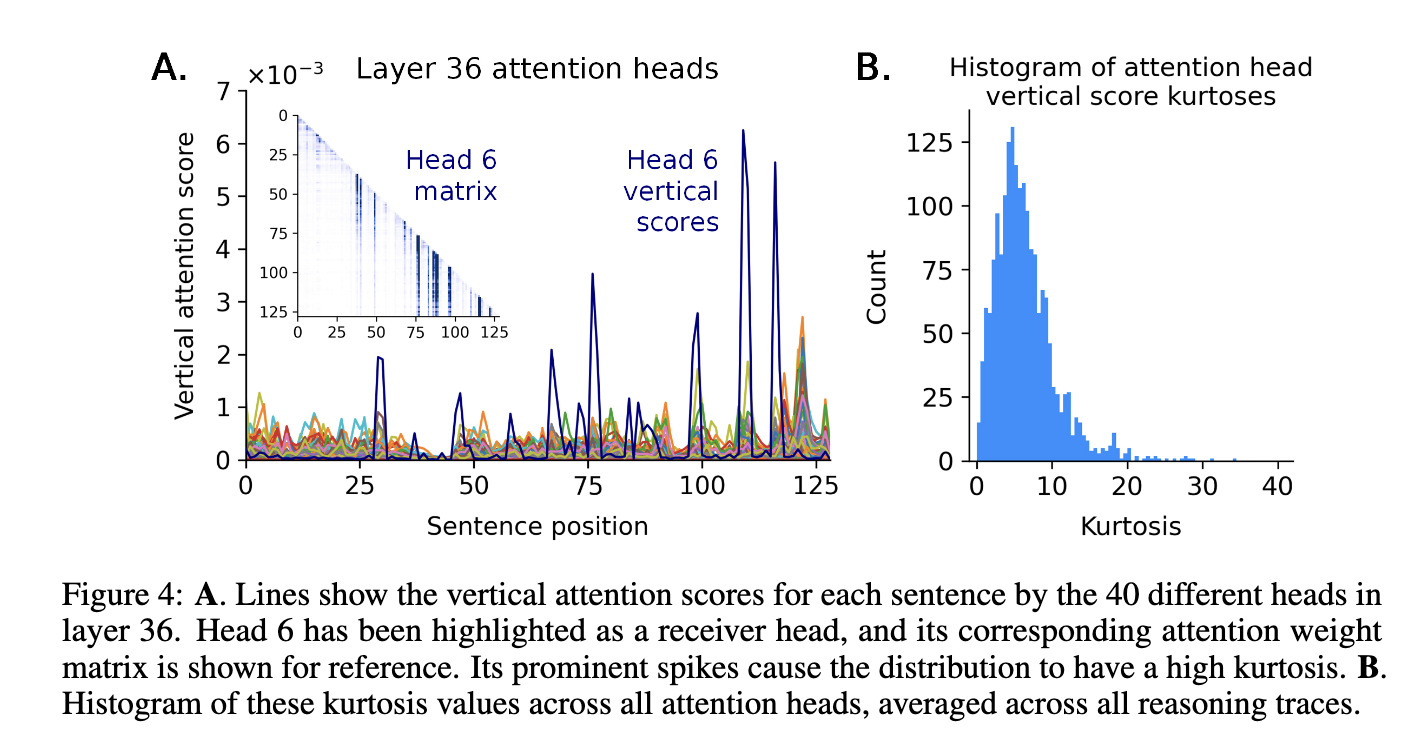
Furthermore, the study addresses another key aspect of interpretability: attention to clustering. Specifically, the study analyzed 250 different attention heads in the DeepSeek model in multiple inference tasks. Among these supervisors, research shows that some receiver heads will always focus heavily on specific inference steps, especially during mathematically intensive queries. In contrast, other attention heads exhibit more distribution or ambiguous attention patterns. The explicit classification of receivers through its interpretability provides further granularity for understanding the internal decision structure of LLM and may guide future model architecture optimization.
Key points: Accurate reasoning analysis and actual benefits
- Thought anchors specifically focus on internal reasoning processes at the sentence level, thereby improving interpretability, which greatly outperforms conventional activation methods.
- Combining black box measurements, receiver head analysis and causal attribution, the thought anchor provides comprehensive and precise insights into model behavior and inference flow.
- The application of the thought anchor method in the DeepSeek Q&A model (with 67 billion parameters) produces compelling empirical evidence, characterized by strong correlation (mean attention score of 0.59) and causal effects (mean measure of 0.34).
- Open source visualization tools on Think-Cannors.com provide significant benefits of usability, thereby facilitating collaborative exploration and improving interpretability approaches.
- The extensive attention head analysis (250 heads) of this study further refines the understanding of how attention mechanisms promote reasoning, thus providing potential avenues for improving future model architecture.
- Thought Anchors demonstrates the ability to build a strong foundation for safe utilization of complex language models in sensitive high-risk areas such as healthcare, finance, and critical infrastructure.
- This framework provides opportunities for future interpretability approaches aimed at further improving the transparency and robustness of AI.
Check Paper and interaction. All credits for this study are to the researchers on the project. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Sana Hassan, a consulting intern at Marktechpost and a dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. He is very interested in solving practical problems, and he brings a new perspective to the intersection of AI and real-life solutions.



