This AI paper proposes a novel dual-branch encoder architecture for unsupervised speech enhancement (SE)
Voice enhancers can only be trained in truly noisy recordings, which can clearly separate voice and noise – never see paired data? A team of researchers Brno Technical University and Johns Hopkins University propose Unsupervised voice enhancement using data-defined priors (using DDP)a dual-stream encoder that divides any noisy input into two waveforms – digital – estimated clean speech and residual noise – and learns both only From unpaired datasets (Clean Speech corpus and optional noise corpus). Training enforcement and In both outputs, the input waveform is reconstructed, avoiding degenerate solutions, and aligning the design with the neural audio codec target.
Why is this important?
Most learning-based voice augmentation pipelines depend on paired clean recordings that are expensive or impossible to collect on a large scale under actual conditions. Unsupervised routes (such as Metricgan-U) eliminate the need for clean data, but combine model performance with external, non-invasive metrics used during training. Keep training with DDP Data onlyimpose discriminators on independent clean speech and noise datasets and use reconstruction consistency to link estimates to observed mixtures.
How does it work?
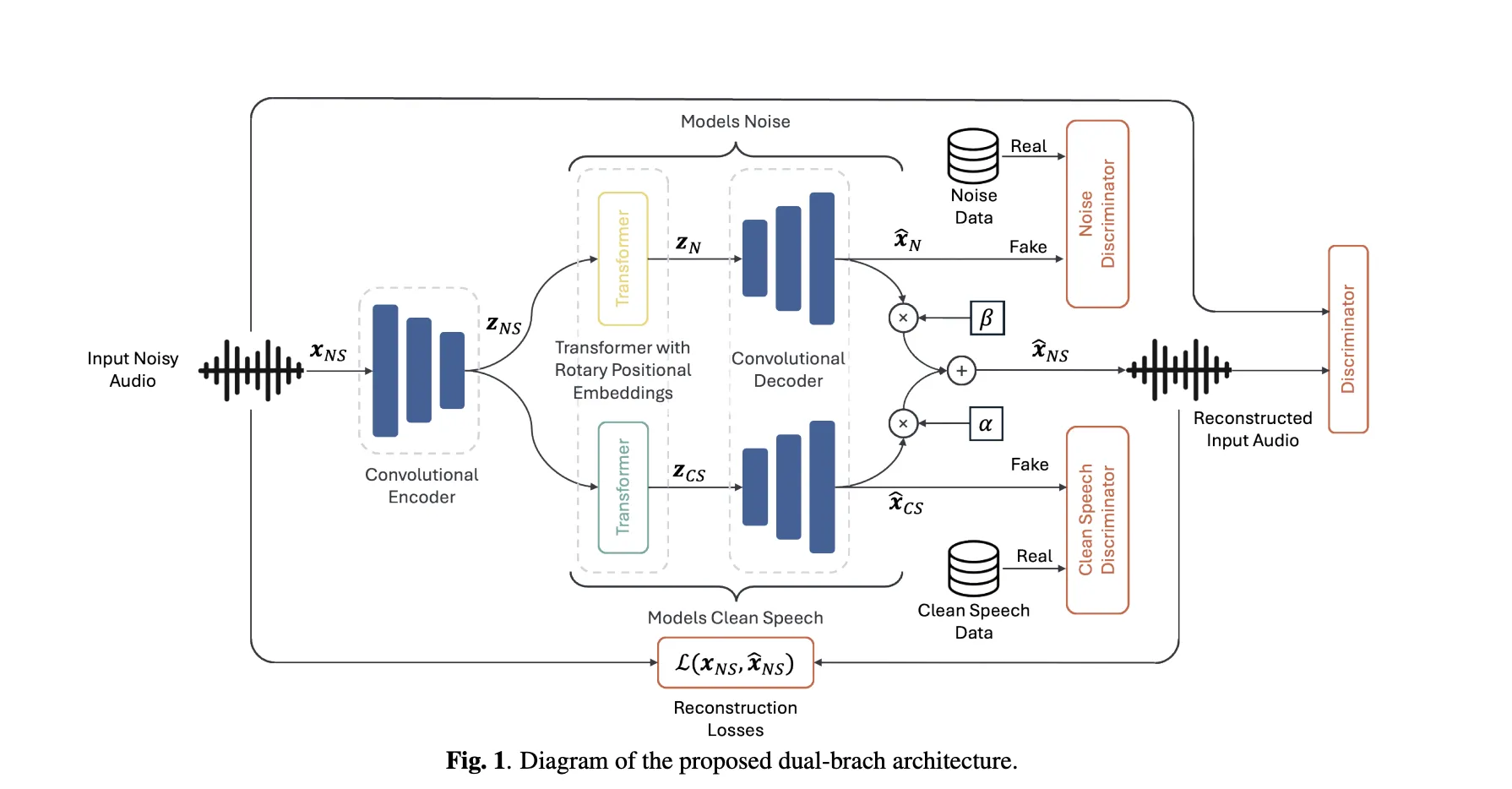
- dynamo: Codec-type encoder compresses input audio into potential sequences; this is divided into two parallel transformer branches (Roformers) Clean speech and noise The echo shapes are decoded by the shared decoder respectively. Reconstruct the input into a least squares combination of the two outputs (scalar α, β compensates for amplitude error). Reconstruction uses multi-scale MEL/STFT and SI-SDR losses such as neural audio codecs.
- The opponent’s prior: Three discriminator ensembles – clear, noisy and noisy – Spread distribution constraints: a clean branch must resemble a clean speech corpus; a noise branch must resemble a noise corpus; a reconstructed mixture must sound natural. Use LS-GAN and function matching loss.
- initialization: Initializing the encoder/decoder from the validated description improves convergence and final quality with training from scratch.
How to compare?
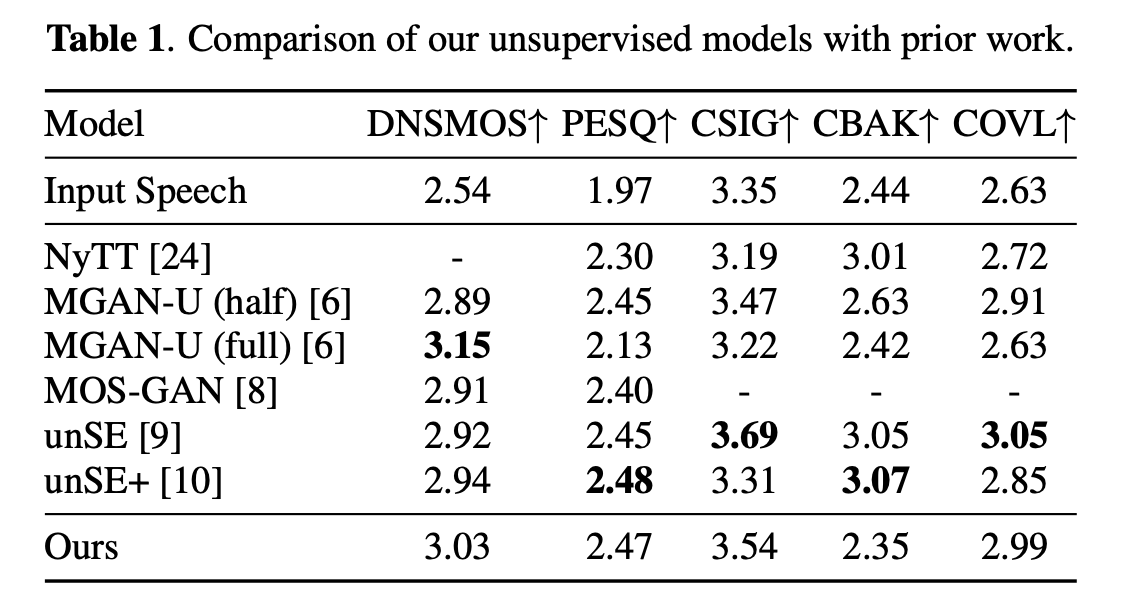
On the standard VCTK+Requirements Simulate settings, using DDP to report parity with the strongest unsupervised baseline (e.g., UNSE/UNSE+ based on optimal transmission) and competitive DNSMOS with Metricgan-U (Directly Optimized DNSMOS). Example number (input with system): DNSMOS from 2.54 (noisy) ~3.03 (Use ddp), pesq 1.97 arrive ~2.47; Some baseline trajectories caused by the noise attenuation of non-speech segments are consistent with explicit noise.
Data selection is not a detail, but a result
A center found: Which one A clean corpus defines previous swing results, even creates Excessive time The results of the simulation test.
- VCTK+ requirement prior (VCTK cleaning) → Optimal score (DNSMOS ≈3.03), but this configuration is impractical to “peep” in the target distribution used to synthesize the mixture.
- Extraterritorial prior test → Significantly lower metrics (e.g. PESQ ~ 2.04), reflecting distribution mismatch and some noise leaking into clean branches.
- Chime-3 in the real world: Use the “closed” channel as Before cleaning the inner area In fact, it is injured – because the “clean” reference itself contains the bleeding environment; a truly clean corpus output from the outside world higher DNSMOS/UTMO is developing and testing, although there are some clear tradeoffs under stronger suppression.
This illuminates the differences between previously unsupervised results and believes that careful, transparent prior selection is given when SOTA is required on simulation benchmarks.
The proposed dual-branch encoder architecture treats enhancement as explicit two-source estimation with a priori of data definition rather than metric scaling. Reconstruction constraints (clean + noise = input) plus an adversarial prior to independent cleaning/noise corpus gives a clear inductive bias, while initialization from neural audio codecs is a pragmatic approach to stable training. The results appear to be competitive with the unsupervised baseline while avoiding the DNSMOS-guided goal; it should be noted that the choice of “clean prior” has a significant impact on the reported gains, so the claim should specify the choice of the corpus.
Check Paper. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter. wait! Are you on the telegram? Now, you can also join us on Telegram.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.
🙌Follow Marktechpost: Add us as the preferred source on Google.


