This AI paper introduces Pyvision: a Python-centric framework
Visual reasoning tasks challenge artificial intelligence models to use perception and logical reasoning to interpret and process visual information. These tasks cover a wide range of applications including medical diagnosis, visual mathematics, symbolic puzzles, and image-based question answers. Success in this field requires not only object recognition, but also dynamic adaptation, abstraction and contextual inference. The model must analyze the images, identify relevant features, and often generate explanations or solutions that require a series of inference steps related to visual input.
Limitations are evident when the model is expected to apply reasoning or modify its strategies to implement various visual tasks. Many current models lack flexibility and usually default to pattern matching or hard-coded routines. These systems have difficulty breaking down unfamiliar problems or creating solutions that go beyond preset toolkits. They also fail when tasks involve abstract reasoning or require models to exceed surface-level features in visual content. The need for systems that can adapt autonomously and build new tools for reasoning has become an important bottleneck.
Previous models typically rely on fixed tool sets and rigid single-turn processing. Solutions such as Visual Chatgpt, HuggingGpt, or Vipergpt integrate tools such as segmentation or detection models, but they are confined to predefined workflows. This setting limits creativity and adaptability. These models do not require the ability to modify or extend their toolsets during the task. They process tasks linearly, which limits their practicality in areas where iterative reasoning is required. The multi-turning function is missing or severely limited, thus preventing the model from conducting more in-depth analytical reasoning.
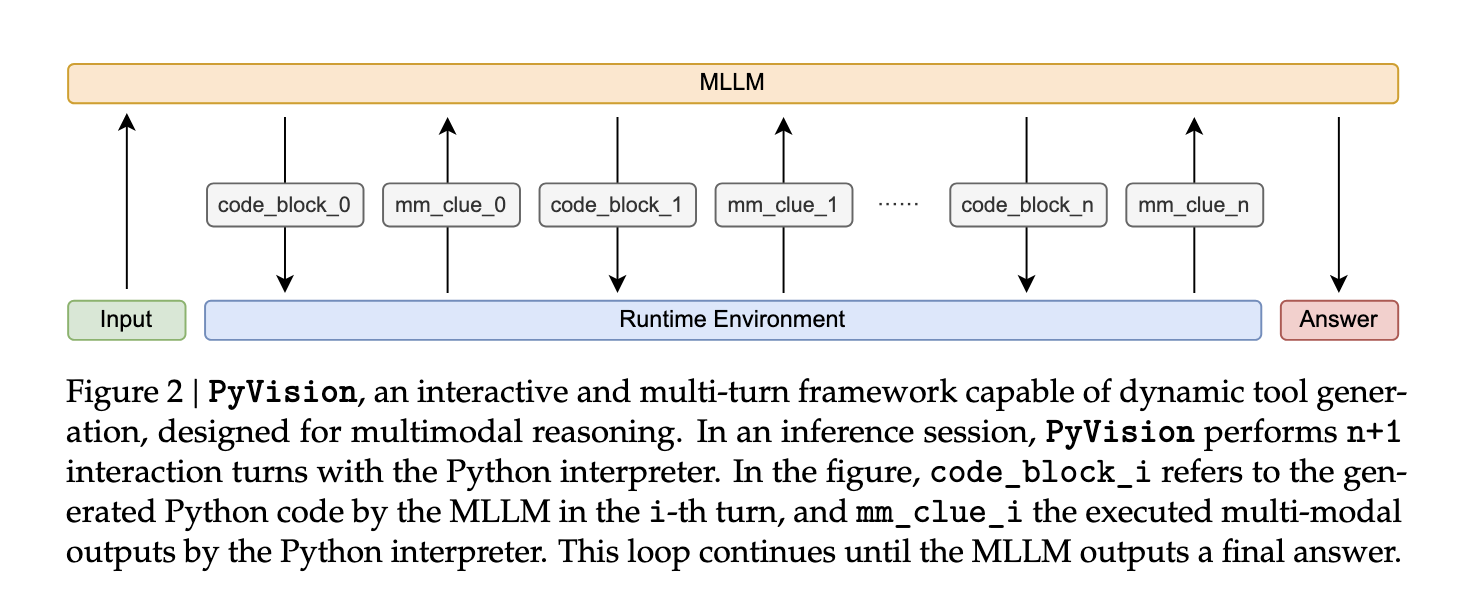
The researchers introduced Pyvision to overcome these problems. Developed by teams from Shanghai AI Labs, Rice University, CUHK, NUS and SII, the framework enables large multi-modal models (MLLMS) to independently create and execute Python-based tools for specific visual reasoning problems. Unlike previous methods, Pyvision is not bound by static modules. It uses Python as the main language and builds tools dynamically in multi-turn loops. This allows the system to adjust its approach in the task, allowing the model to make decisions, reflect on the results, and refine its code or reasoning in several steps.

In fact, Pyvision is initiated by receiving user queries and corresponding visual input. MLLM (such as GPT-4.1 or Claude-4.0-Sonnet) generates Python code based on prompts that are executed in an isolated environment. Results – text, visual or numerical – back to the model. With this feedback, the model can modify its plan, generate new code and iterate until a solution is generated. The system supports cross-steering persistence, which means that it remains variable between interactions, allowing sequential reasoning. Pyvision includes internal security features such as process isolation and structured I/O, which ensures robust performance even under complex inference loads. It utilizes Python libraries such as OpenCV, Numpy and Pillows for operations such as segmentation, OCR, image enhancement, and statistical analysis.
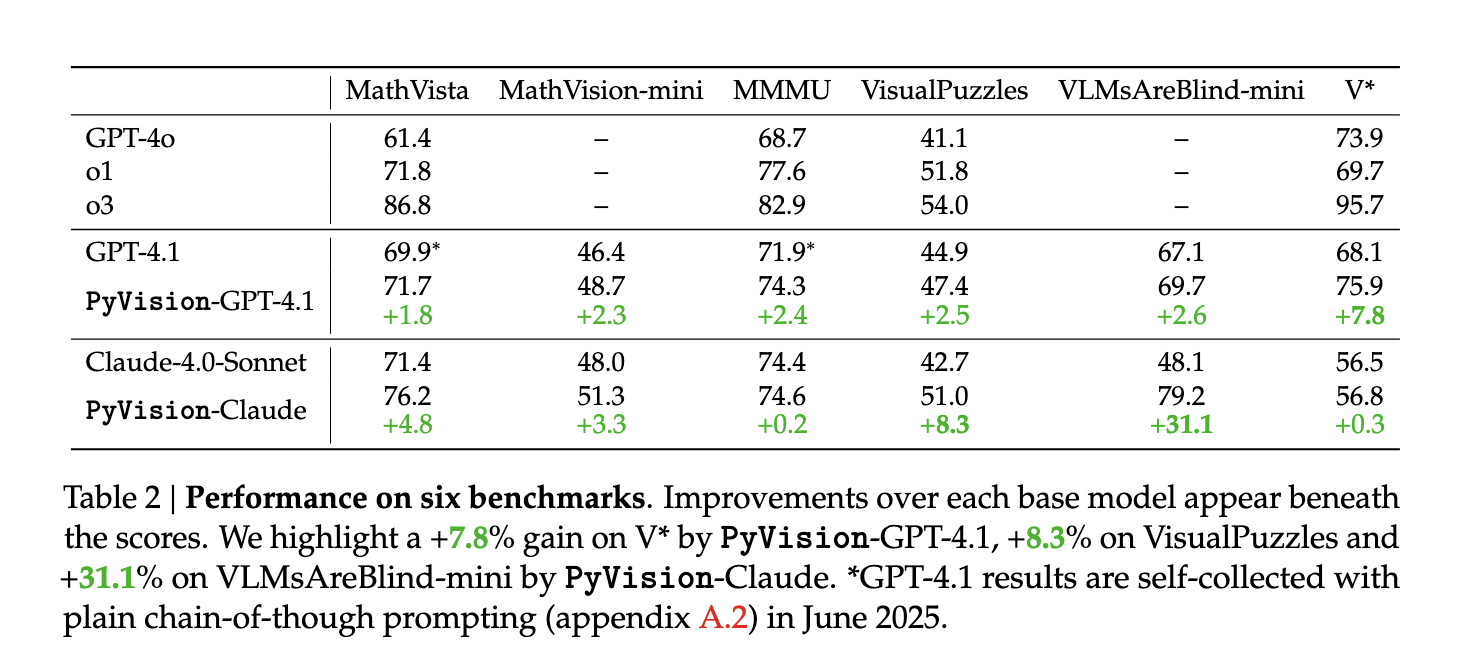
Quantitative benchmarks verify the effectiveness of Pyvision. On the visual search benchmark V*, Pyvision improves GPT-4.1’s performance from 68.1% to 75.9%, an increase of +7.8%. On the symbolic visual reasoning benchmark VLMSareBlind-Mini, the accuracy of Claude-4.0-Sonnet increased from 48.1% to 79.2%, an increase of 31.1%. Additional benefits were observed on other tasks: +2.4% for MMMU, +2.5% for VisualPuzzles for GPT-4.1; +4.8% for MathVista, +8.3% for Claude-4.0-Sonnet. These improvements vary by the advantages of the underlying model – models that stand out in perception benefit from Pyvision in perceptually heavy tasks, while inference models gain more benefits in abstract challenges. Pyvision expands the capabilities of basic models rather than masking or replacing them.
This study highlights significant advances in visual reasoning. Pyvision solves basic limitations by allowing models to create problem-specific tools in real time. This method transforms the static model into a proxy system that can perform thoughtful, iterative problem solving. Through dynamic connections to perception and reasoning, Pyvision takes a critical step to build intelligent, adaptable AI to address complex real-world visual challenges.
Check Paper, github pages and projects. All credits for this study are to the researchers on the project.
Researchers with Nvidia, OpenAI, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgan, Amgan, Aflac, Aflac, Wells Fargo and 100s read AI Dev newsletters and researchers read. [SUBSCRIBE NOW]
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.


