Google releases an updated version Gemini 2.5 flash memory and Gemini 2.5 flash Across the preview model AI Studio and Vertex AIplus scroll alias –gemini-flash-latest and gemini-flash-lite-latest– Always point out the latest preview of each family. For production stability, Google recommends fixing fixed strings (gemini-2.5-flash,,,,, gemini-2.5-flash-lite). Google will give two weeks of email notification before repositioning -latest alias, and point out Rate limits, features and costs may vary by alias update.
What actually changed?
- flash:improve Use of proxy tools and more effective “thinking” (multi-direct reasoning). Google Reports +5 points lift SWE bench verified Preview with May (48.9% → 54.0%), indicating better long horse planning/code navigation.
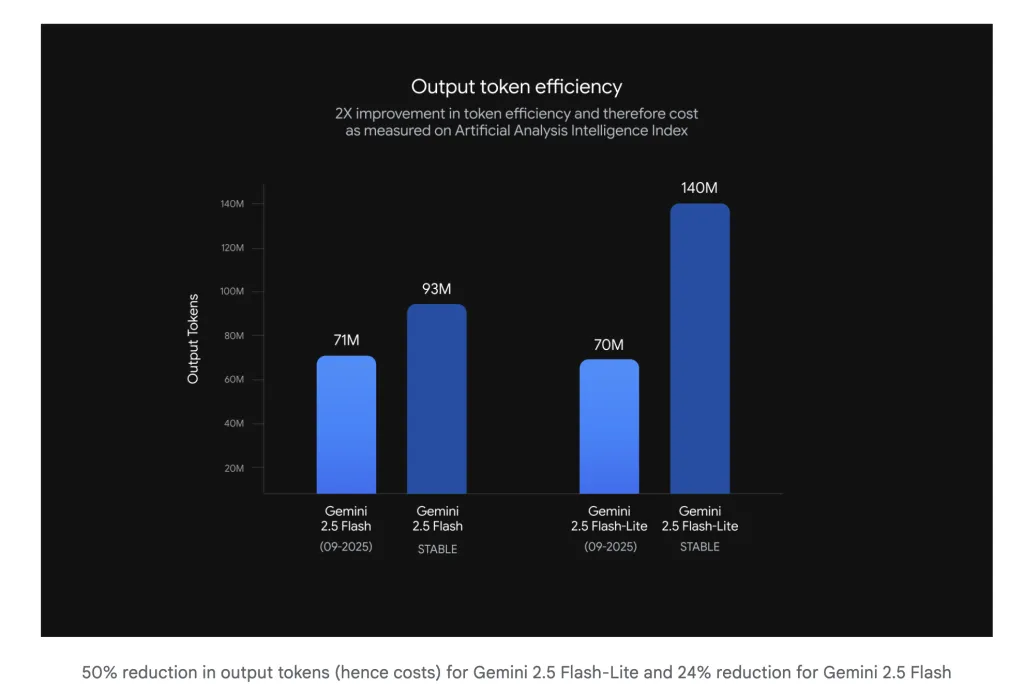
- flash: More stringent adjustments Explain the following,,,,, Decreased lengthstronger Multimodal/translation. Google’s internal chart display ~50% less output token for flash fuel and ~24% less For Flash, it directly cuts out output spending and wall lock time in throughput-limited services.
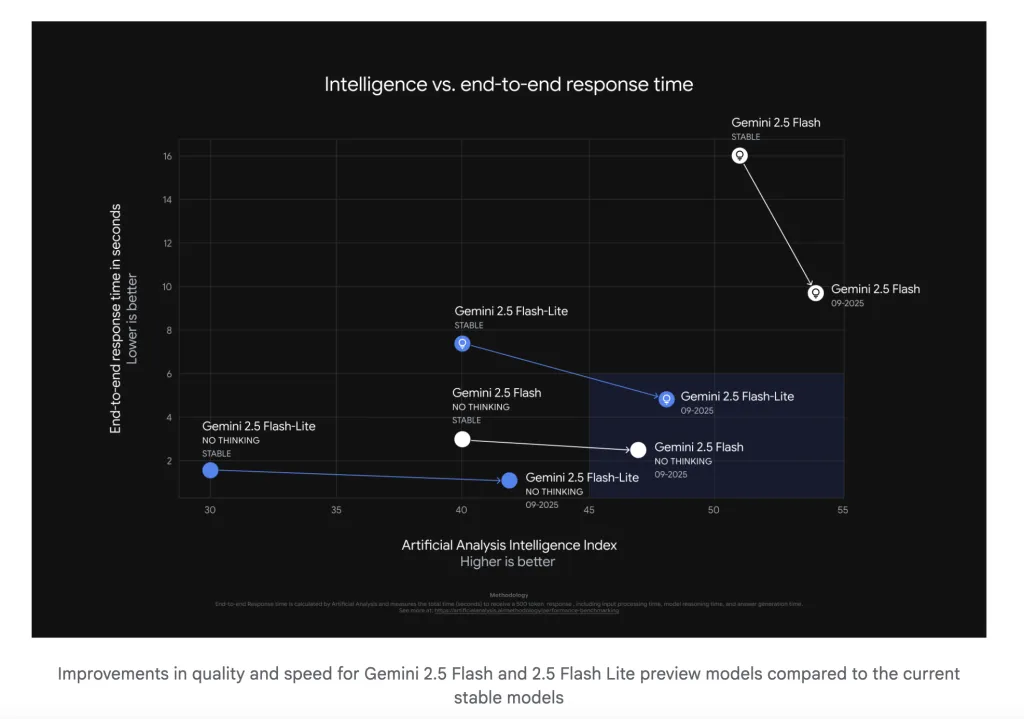
Manual analysis (account behind AI benchmarking website) received Pre-release access And published external measurements in intelligence and speed. Highlights of threads and companion pages:
- Throughput: In endpoint testing, Gemini 2.5 flash (preview 09-2025, reasoning) Reported as The fastest proprietary model They tracked around ~887 output token/s In the AI Studio settings.
- Smart Index Delta: September preview flash and flash “Smart” score improvements in manual analysis (site page decomposition reasoning vs. non-disputed tracks and mixed price assumptions) compared to previous stable versions.
- Token efficiency: The thread reiterates Google’s own reduction claim (-24% Flash, -50% Flash-lite) and puts the winning framework as Cost per success Improvements to strict delay budgets.
Cost surface and context budget (for deployment options)
- Flash ga list price yes $0.10/1 million input token and $0.40/1m output token (Google’s July GA Post and DeepMind model page). This baseline is a detailed description of the reduction, translated into immediate savings.
- context: Flash-Lite support ~1m-token Context with configurable “thinking budget” and tool connectivity (search grounding, code execution) – A proxy stack for interleaved reads, planning, and multi-tool calls.
Browser Agent Angle and O3 Claims
The loop advocate says “The new Gemini flash has Level O3 accuracybut yes 2× Faster and 4×cheap exist Browser proxy Task. “This is Community Reportnot in official Google posts. It may trace back to a private/limited task suite (DOM Navigation, Action Plan) with specific tool budgets and timeouts. Use it as your own simplified assumption; don’t regard it as a truth that transcends.
Practical team guidance
- PIN and Chase
-latest: If you rely on strict SLA or fixed restrictions, pin Stable string. If you keep getting the cost/delay/quality of canary,-latestAlias reduces upgrade friction (Google provides two weeks of notification before switching pointers). - High QP or token endpoint:from Flash-Lite Preview;Detailed and guided instructions to upgrade the outflow token. Verify multimodal under production load and long text traces.
- Agent/Tool Pipeline:a/b Flash preview Multi-step tooling uses places where dominate costs or failure modes; Google’s SWE bench-verified lifts and community tokens digital recommendations for better planning under a limited mind budget.
Model string (current)
- Preview:
gemini-2.5-flash-preview-09-2025,,,,,gemini-2.5-flash-lite-preview-09-2025 - Stable:
gemini-2.5-flash,,,,,gemini-2.5-flash-lite - Scroll aliases:
gemini-flash-latest,,,,,gemini-flash-lite-latest(Pointer semantics; features/restrictions/pricing may be changed).
Summary
Google’s new version update tightens Tool usage capability (Flash) and Token/latency efficiency (Flash) and introduce -latest Alias are used for faster iterations. External benchmarks Manual analysis It means meaningful Throughput and Intelligence Index Revenues for September 2025. Preview, now the flash test is The fastest proprietary model In their seat belts. Verify your workload (especially the browser proxy stack) before committing to aliases in production.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


