Technical Deep Dive: Any MCP Server Automation LLM Agent with MCP-RL and ART
introduce
Authorized large language models (LLM) interact with dynamic, real-world environments is a new field of AI engineering. The Model Context Protocol (MCP) specification provides a standardized gateway through which LLM can connect to any external system (PIS, file system, database, application or tool) without the need for custom glue code or fragile prompt hacks every time. Nevertheless, leveraging such toolsets through programming with powerful reasoning across multi-step tasks is still a huge challenge.
This is the latest combination McP-RL (An enhanced learning loop for MCP servers) and Open Source Art (Agent Reinforcement Coach) Library Bringing paradigm offset: You can now have a proxy Detection,,,,, specializedand Exhaust yourself For any MCP service with minimal human design, no tagged data and SOTA reliability. This article unravels the exact mechanisms, implementation pathways and technical complexity (to the code level).
What is mcp-rl?
McP-RL is a built meta-training protocol designed to allow any LLM proxy to learn the MCP server’s exposed toolset through Hardened Learning (RL). MCP-RL is part of the Agent Enhanced Coaching (ART) program. Give only the URL of the server:
- The agent is placed inside the server and uses its mode to automatically discover available tools (functions, APIs, endpoints).
- Synthesis tasks are designed to cover a variety of tool applications.
- Relative Scoring System (ruler) Benchmarking agent performance, without marking gold data even on each trajectory.
- The agent is fine-tuned to maximize task success.
This means that LLM can be proficient any Consistent tools return to servers – weather, database, file search, ticketing, etc.
Art: Agent Reinforcement Coach
Art (Agent Enhanced Trainer) provides a well-curated RL pipeline for MCP-RL, supporting most VLLM/HuggingFace-compatible models (e.g. Qwen2.5, Qwen3, Qwen3, Llame, Kimi) and distributed or local computing environments. Art and:
- Client/server separation: Inference and RL training decomposition; when training is automatically uninstalled, the agent can run from any client.
- Plug-in integration: Minimum intrusion into existing code bases; just hang Art’s customers in your agent communication loop.
- GRPO algorithm: Improved RL fine-tuning method for stability and learning efficiency, leveraging Lora and VLLM for scalable deployment.
- No need to tag data: Comprehensive scene and relative reward (ruler) system completely replace the handmade dataset.
Code Walkthrough: LLM specializing in using MCP-RL
In the following code excerpt, the nature of the workflow is extracted from the art document:
from art.rewards import ruler_score_group
# Point to an MCP server (example: National Weather Service)
MCP_SERVER_URL = "
# Generate a batch of synthetic scenarios covering server tools
scenarios = await generate_scenarios(
num_scenarios=24,
server_url=MCP_SERVER_URL
)
# Run agent rollouts in parallel, collecting response trajectories
# Each trajectory = (system, user, assistant messages...)
# Assign rewards to each group using RULER's relative scoring
scored_groups = []
for group in groups:
judged_group = await ruler_score_group(group)
scored_groups.append(judged_group)
# Submit grouped trajectories for RL fine-tuning (GRPO)
await model.train(scored_groups)
explain:
- Comprehensive plan: No manual tasks.
generate_scenariosAutomatically design various prompts/tasks based on tools discovered from MCP servers. - Launch execution: Agent runs, calls the tool through MCP to obtain the trajectory of step-by-step tool usage and output.
- Ruler scores: Instead of static rewards, it is used by the ruler Relative Evaluations within each batch are automatically extended to reliably handle variable difficulty and task novelty.
- Training loop: Batch trajectories and rewards are sent to Art Server, and the Lora adapter is gradually trained using the policy gradient algorithm GRPO.
Loop Repeat – Each loop enables the agent to combine the server’s tools more accurately to solve synthesis tasks.
Under the Hood: How McP-RL Overview
- Tool Discovery: The MCP interface usually reveals OpenAPI-compliant patterns, and the agent lists all callable actions and their signatures without assumptions about domain details.
- Scene generation: Template or a handful of ammunition model hints can be used to guide the tasks of example representative usage (composition of atomic or complex APIs).
- No feedback on gold data: The ruler’s innovation is batch comparison, with more successful behavior scores higher in the current set, which is the self-papt across new tasks or noisy environments.
- Synthesis → Real Mission Bridge: Once the agent is well versed in constructed tasks, it is summarized as the needs of the actual user, as the coverage of the tool is intended to be broad and combined.
Real-world impacts and benchmarks
- Minimum settings: Can be deployed with any MCP server – endpoint only, no internal code or access required.
- General Purpose: Agents can be trained to use any tool set – weather, code analysis, file search, etc.
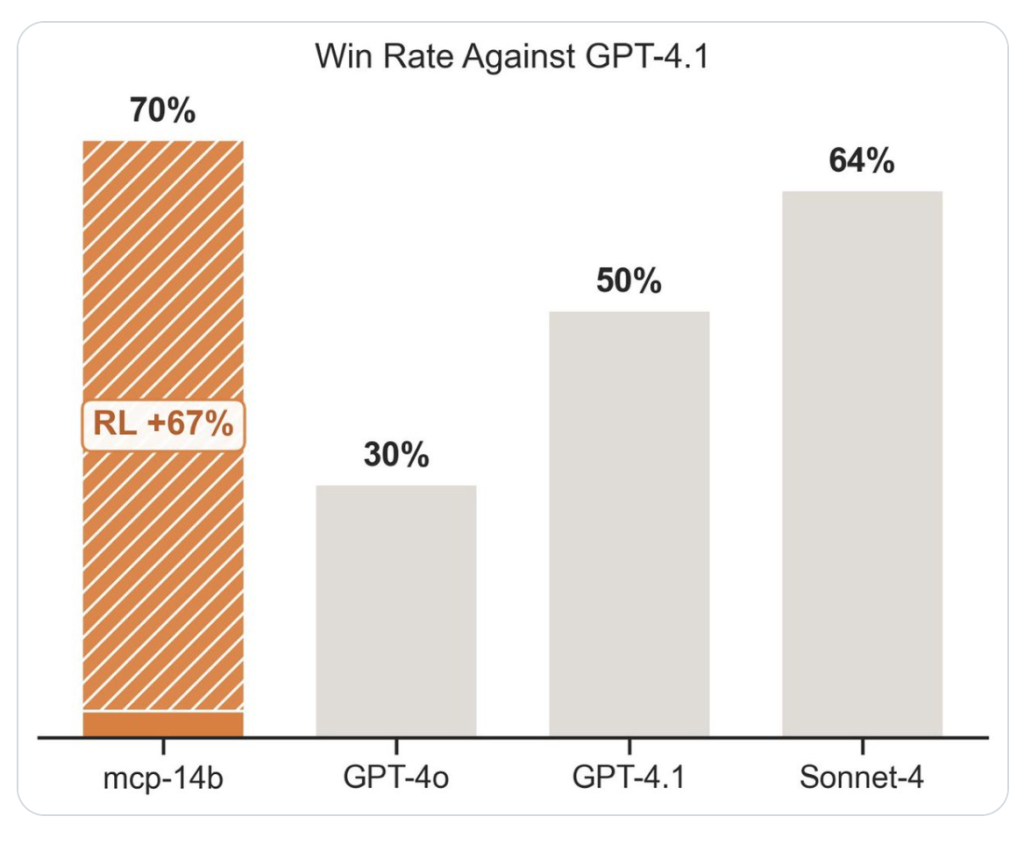
- The most advanced results: Match or beat professional agent baseline in 2/3 public benchmarks.
- Zero-marked data: This method provides a scalable way for proxy RL, and applies even if it is not possible to purchase expert demonstrations.
Architectural Overview
| Element | describe |
|---|---|
| Art Client | Carefully plan agent sales, send/receive messages, batch rewards |
| Art Server | Handle inference and RL training loops, manage Lora checkpoints |
| MCP Server | Uncovering the tool set that is queried by agents during each task |
| Solution Engine | Automatically generate various task prompts for synthesis |
| Ruler scorer | Relative reward allocation for each group of trajectories |
Practical integration
- Install:
pip install openpipe-art - flexibility: ART cooperates with on-premises or cloud computing through VLLM or compatible backends.
- Debugging Tools: Integrated with W&B, langfuse, openpipe for observationality.
- Customizable: Advanced users can adjust scene synthesis, reward molding, batch size, and Lola configuration.
Summary
The combination of MCP-RL and Art Summary has disappeared for years of RL automation design, allowing you to convert any LLM to Tool usage,,,,, Self-planning Agent, insufficient domain shape, no annotation training data. Whether your environment is a public API or a custom enterprise server, the agent can learn at work and achieve scalable, robust performance.
For more details, practice sample notebooks and the latest benchmarks, visit the Art Library and its [MCP- RL-specific training examples]

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


