Stepfun AI releases Step-Audio 2 Mini: an open source 8B voice-to-speech AI model that exceeds GPT-4O-Audio
Stepfun AI Team has been released Step-Audio 2 Minian 8B parameter speech-to-speech large audio language model (LALM), which provides expression, grounding and real-time audio interaction. exist Apache 2.0 LicenseThis open source model achieves state-of-the-art performance in speech recognition, audio comprehension and voice conversation benchmarks, which can be achieved through commercial systems such as GPT-4O-Audio.
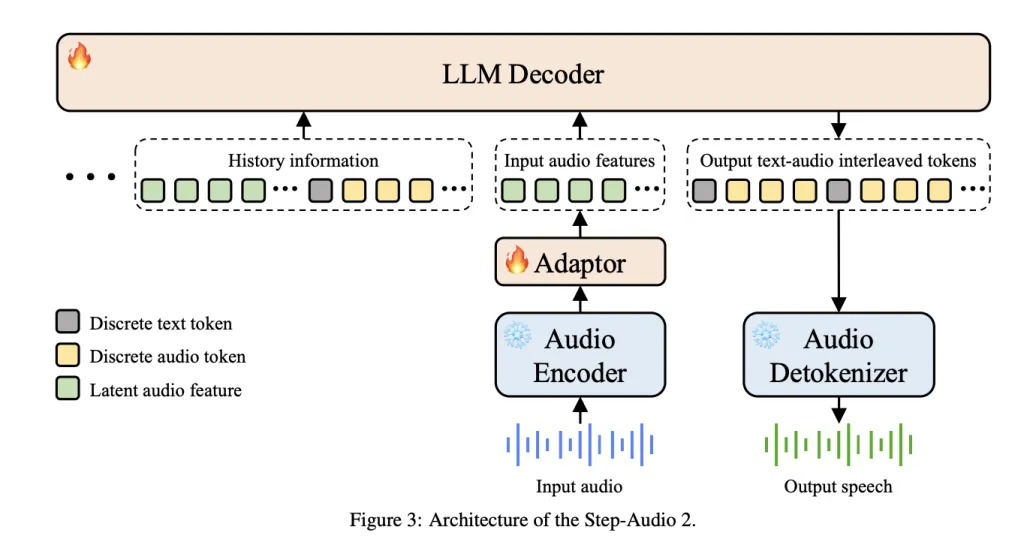
Key Features
1. Unified audio text symbolization
Unlike the cascading ASR+LLM+TTS pipeline, Step-Audio 2 integration Multi-mode discrete token modelingWhere Text and audio tokens share a single modeling stream.
This can:
- Seamless reasoning across text and audio.
- immediate Voice style switching During reasoning.
- Consistency of semantics, rhythms, and emotional output.
2. Expressive and emotional
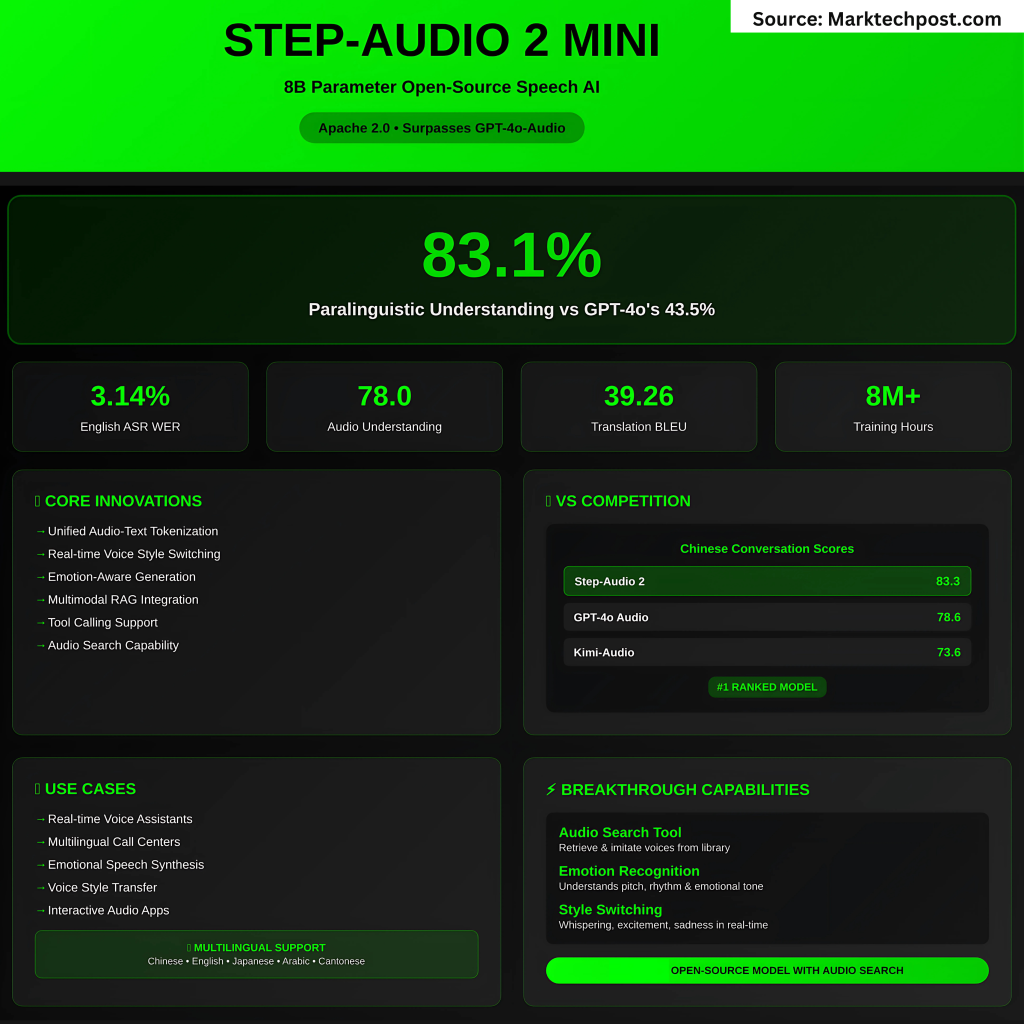
This model not only transcribes the speech, but also explains Paralinguistic characteristics Like tone, rhythm, emotion, tone and style. This allows for conversations with the emotional tones of reality, such as whispering, sadness or excitement. Benchmark on stepval-audio-parlalanical Show Step-Adio 2 implementation 83.1% accuracyfar beyond GPT-4O audio (43.5%) and Qwen-Omni (44.2%).
3. Search speech generation
Step-Audio 2 merge Multi-mode rag (retrieval machine):
- Web Search Integration Used for factual basis.
- Audio search– A new ability to retrieve real sounds from large libraries and blend them into responses, enabling them to Voice/style imitation When reasoning.
4. Tool calls and multimodal reasoning
This system goes beyond voice synthesis through support Tool calls. Benchmarks show that Step-Audio 2 matches text LLM Tool selection and parameter accuracyalthough Audio search tool call– Features not available in text LLM only.
Training and data scales
- Text + Audio Corpus: 1.356T token
- Audio Hours: 8m+reality and synthesis time
- Diversity of speakers: ~ 50k sounds in language and dialect
- Preprocessing pipeline: The multi-stage course covers ASR, TT, voice-to-voice translation and a dialogue synthesis of emotion-marking.
This massive training allows the Step-Audio 2 Mini to retain powerful text reasoning (through its Qwen2-Audio and Cosyvoice Foundation) while mastering fine-grained audio modeling.
Performance Benchmark
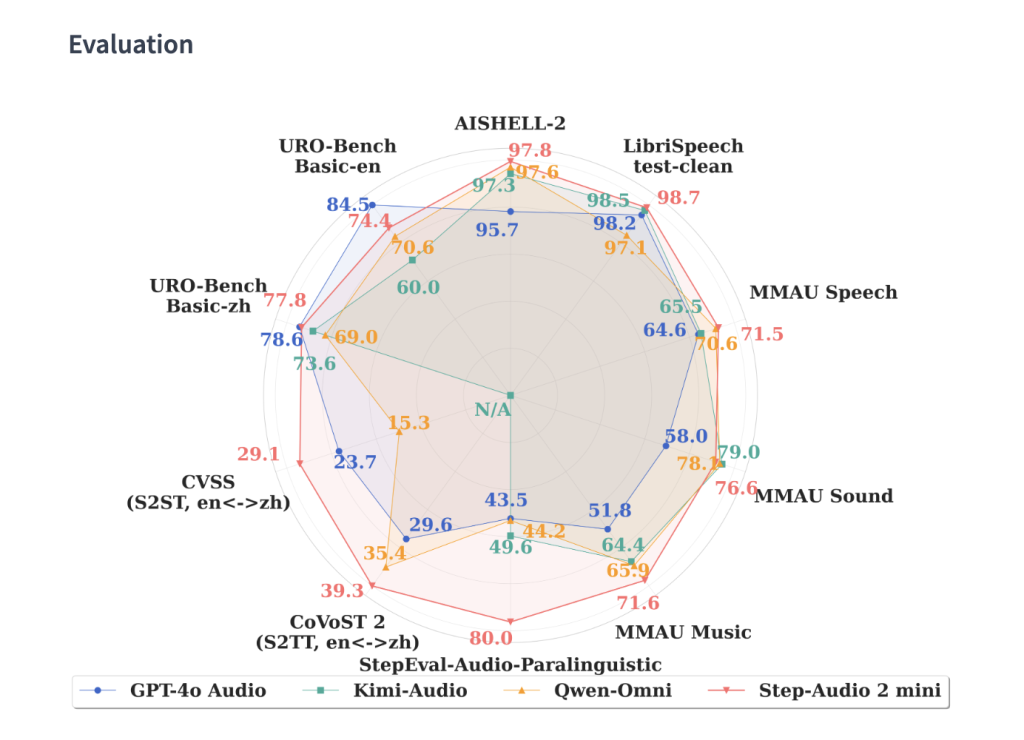
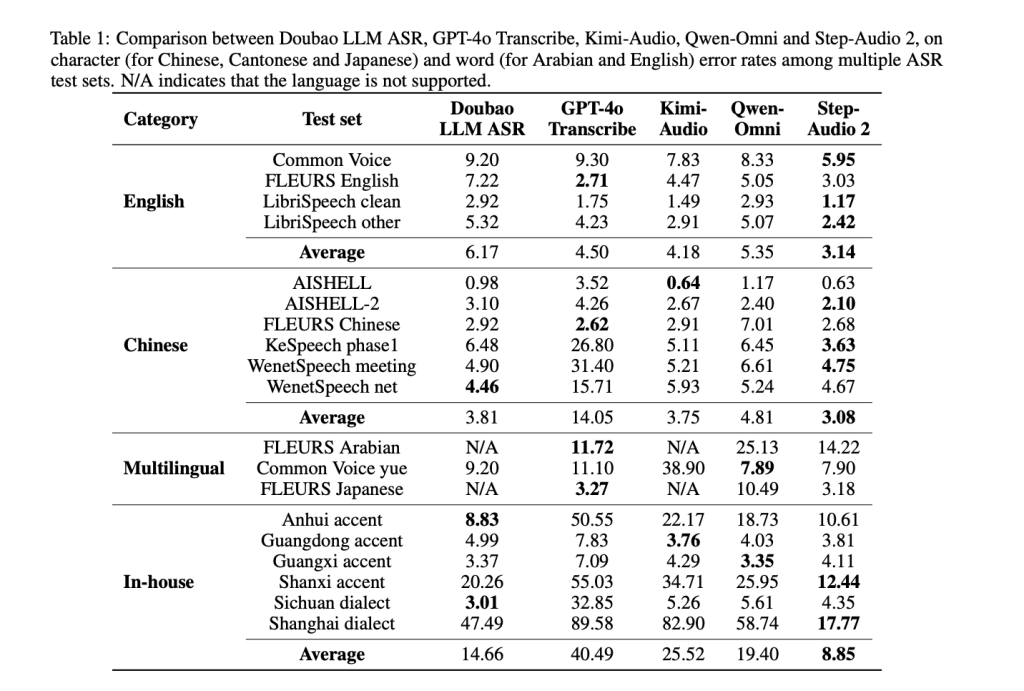
Automatic speech recognition (ASR)
- English: Average 3.14% (average transcription that beat GPT-4O was 4.5%).
- Chinese: Average CER was 3.08% (significantly lower than GPT-4O and QWEN-OMNI).
- Strong across dialects and accents.
Audio Understanding (MMAU Benchmark)
- Step-Audio 2: 78.0 average, exceeding Omni-R1 (77.0) and audio Flamingo 3 (73.1).
- Strongest Voice and voice reasoning tasks.
Voice translation
- COVOST 2 (S2TT): BLEU 39.26 (highest in open and closed models).
- CVSS (S2ST): BLEU 30.87, before GPT-4O (23.68).
Dialogue Bench (URO BENCH)
- China Dialogue: The best overall 83.3 (Basic) and 68.2 (Pro).
- English dialogue: Competition with the GPT-4O (83.9 vs. 84.5) is far ahead of other open models.
in conclusion
Step-Audio 2 Mini Give developers and research communities access to advanced multimodal voice intelligence. By combining qwen2-audioThe reasoning ability Cosyvoice’s tokenized pipelineand enhancement Search-based groundingStepfun delivers the most capable Turn on the audio LLM.
Check Paper and Model embracing face. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


