Stanford University researchers present Medagentnench: Realistic Benchmarks for Medical AI Agents
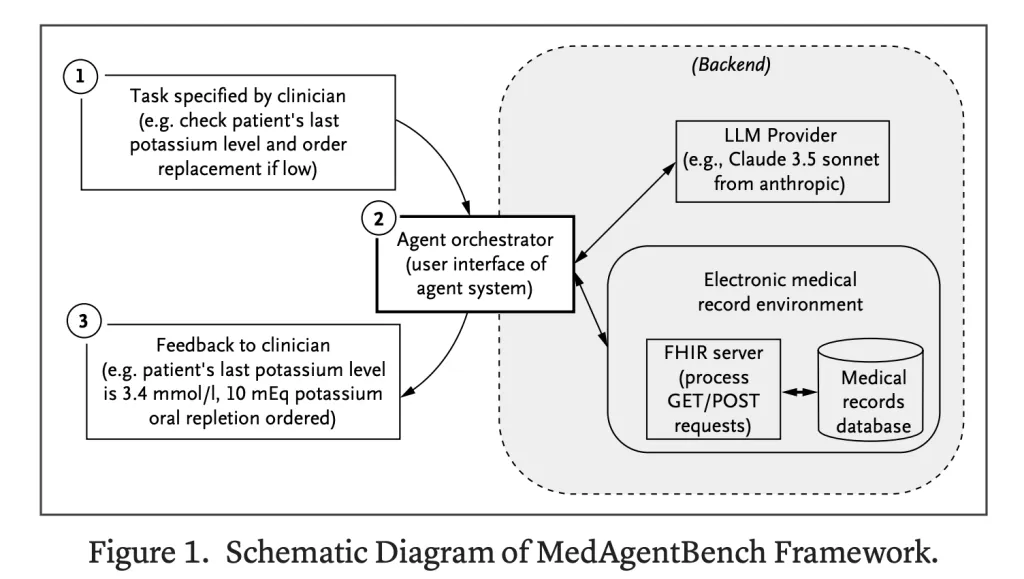
A Stanford University researchers released MedagentBenchThis is a new benchmark suite designed to evaluate large language model (LLM) agents in healthcare environments. Unlike previous question datasets, MedagentBench provides Virtual Electronic Health Record (EHR) environment Where AI systems must interact, plan and perform multi-step clinical tasks. This marks a significant shift from testing static inference to evaluating proxy capabilities Real-time, tool-based medical workflows.
Why do we need agency benchmarks in healthcare?
Recent LLMs Go beyond the shift in interactions based on static chat Agent Behavior– Explain advanced instructions, call APIs, integrate patient data and automate complex processes. Medically, this evolution can help solve Employee shortage, document burden and administrative inefficiency.
Although there is a general agent benchmark (e.g., agent, agent board, tau bench), Healthcare lacks a benchmark for standardization Medical data, FHIR interoperability and complexity of longitudinal patient records were captured. MedagentBench fills this gap by providing a reproducible, clinically relevant assessment framework.
What does MEDAGENTENCHANCEN include?
How is the task structured?
MedagentBench by 300 tasks in 10 categorieswritten by a licensed physician. These tasks include patient information retrieval, experimental results tracking, documentation, test ordering, recommendations, and drug management. In inpatient and outpatient care, tasks averaged 2–3 steps and mirrored workflows.
Which patient data support benchmarks?
Benchmark utilization 100 realistic patient profiles Extract from Stanford’s Starr data repository, including 700,000 records Includes laboratory, vitality, diagnosis, procedures and drug orders. Data are de-identified and jittered to seek privacy while retaining clinical effectiveness.
How to build an environment?
The environment is FHIR compliantsupports the retrieval (GET) and modification (POST) of EHR data. AI systems can simulate realistic clinical interactions, such as recording vitality or placing drug orders. This design allows benchmarks to be converted directly into real-time EHR systems.
How to evaluate the model?
- Metric system: Task success rate (SR), strictly measured By @1 Reflects the security requirements of the real world.
- Tested model: 12 leading LLMs including GPT-4O, Claude 3.5 sonnet, Gemini 2.0, DeepSeek-V3, Qwen 2.5 and Llama 3.3.
- Agent Orchestration: Baseline orchestration settings with nine FHIR functions, only Eight rounds of interactive rounds for each task.
Which models perform best?
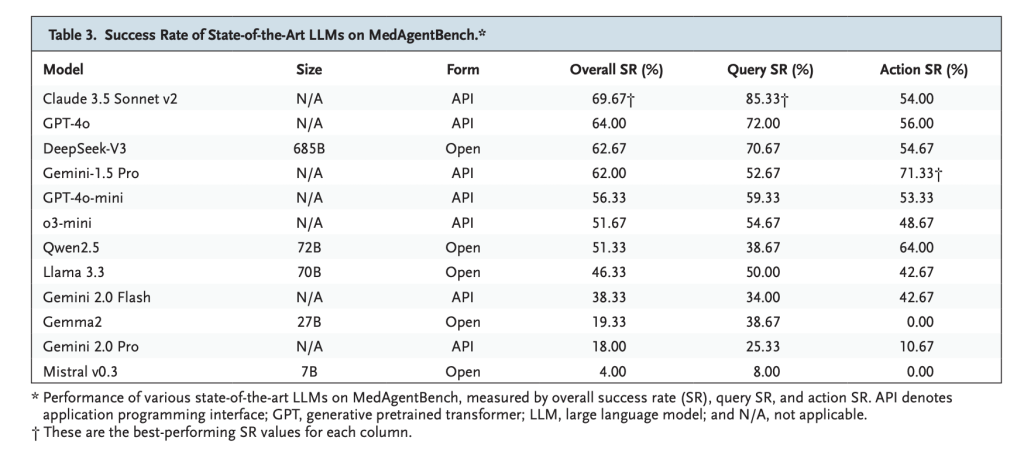
- Claude 3.5 Sonnet V2: The best overall 69.67% successespecially strong in the search task (85.33%).
- GPT-4O: 64.0% success, showing balanced retrieval and action performance.
- DeepSeek-V3: 62.67% success, leading in the open weight model.
- observe: Most models are in Query tasks But struggle with it Action-based tasks A secure multi-step execution is required.
What mistake did the model make?
Two major failure modes emerge:
- Indicates compliance failure – Invalid API call or wrong JSON format.
- Output mismatch – Provide complete sentences when structured values are required.
These errors highlight the gap Accuracy and reliabilityboth are crucial in clinical deployment.
Summary
MedagentBench established the first large-scale benchmark for evaluating LLM agents in a realistic EHR setup, pairing the task of 300 clinicians with an FHIR-compatible environment and 100 patient profiles. The results show strong potential but limited reliability – the rate of Claude 3.5 SONNET V2 is 69.67% – high showing the gap between query success and security operation execution. Despite being limited by single-institution data and EHR-centric scope, MedagentBench provides an open, reproducible framework to drive the next generation of reliable medical AI agents
Check Paper and Technology Blog. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


