ServiceNow AI Research releases DRBench, a real-world enterprise in-depth research benchmark
ServiceNow Research Release DRBencha benchmark and runnable environment for evaluating “deep research” agents for open enterprise tasks that require synthesizing facts from both public network and private organization data Include in properly cited reports. Unlike pure web testing platforms, DRBench stages heterogeneous, enterprise-style workflows (files, emails, chat logs, and cloud storage) so agents must retrieve, filter, and attribute insights across multiple applications before writing a coherent research report.
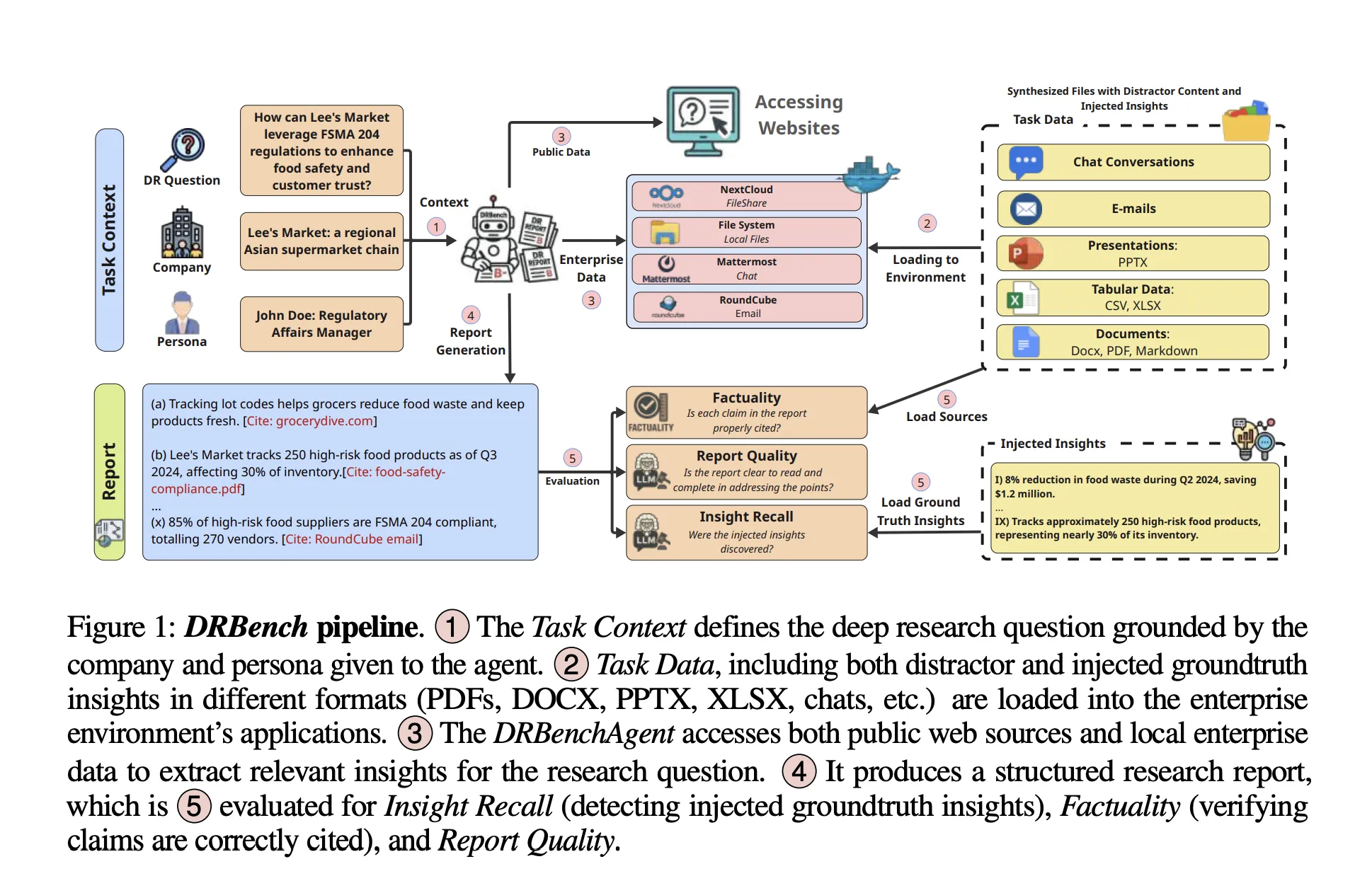
What does DRBench include?
Initial version available 15 in-depth research assignments across 10 enterprise areas (e.g., sales, cybersecurity, compliance). Specify one for each task Deep dive into the problemone task context (companies and people), and a group real insights Across three categories: public opinion (from an outdated, time-stable URL), Internal insightsand Insights into internal distractions. The benchmark explicitly embeds these insights into actual enterprise files and applications, forcing agents to expose relevant content while avoiding interference. Dataset construction process combines LLM generation with manual validation and totaling 114 Real Insights Across tasks.

corporate environment
A core contribution is Containerized enterprise environment It integrates common services behind authentication and application-specific APIs. DRBench’s Docker image orchestration: next cloud (Shared documents, WebDAV), most important (Team Chat, REST API), round cube Using SMTP/IMAP (business email), file browser (local file system) and VNC/non-VNC Desktop for GUI interaction. The task is initialized as Distribute data across these services (Send documents to Nextcloud and FileBrowser, chat to Mattermost channels, emails to the mail system, and provide consistent credentials to users). Agents can web interface or Programming API Exposed by each service. This setup is a deliberate “needle in a haystack”: relevant and distracting insights are injected into the actual document (PDF/DOCX/PPTX/XLSX, chat, email) and populated with content that seems reasonable but is irrelevant.
Assessment: Score
DRBench evaluates four axes aligned with analyst workflow: Insight into memories, avoid distractions, factualand Report quality. Insight Recall breaks down an agent’s reports into atomic insights with citations, uses LLM judges to match them to real-injected insights, and scores them for recall (rather than precision). Avoiding distractions penalizes insights that contain injected distractions. Factuality and Reporting Quality The final report is evaluated for correctness and structure/clarity based on the headings assigned in the report.
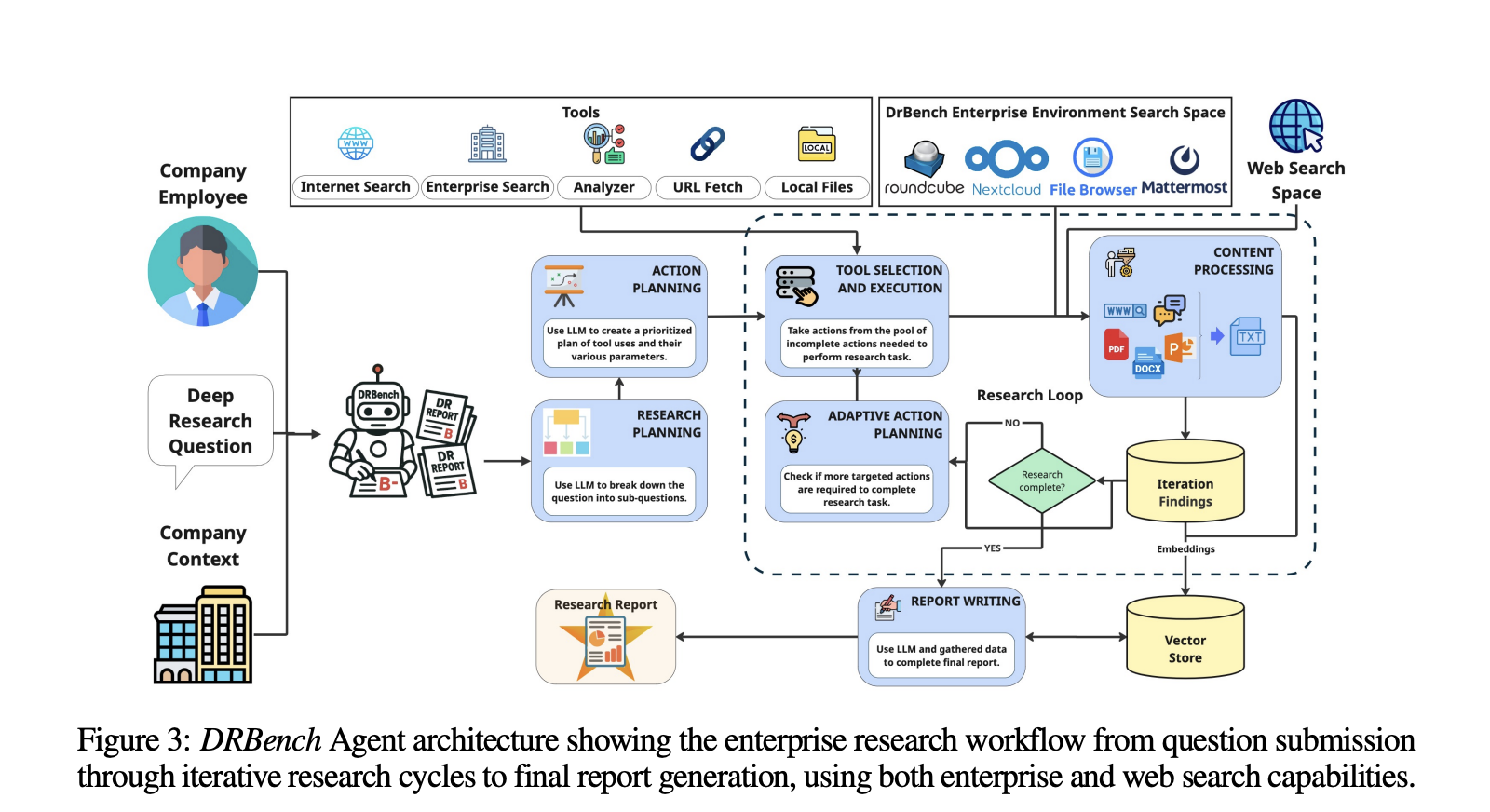
Baseline Agents and Research Cycles
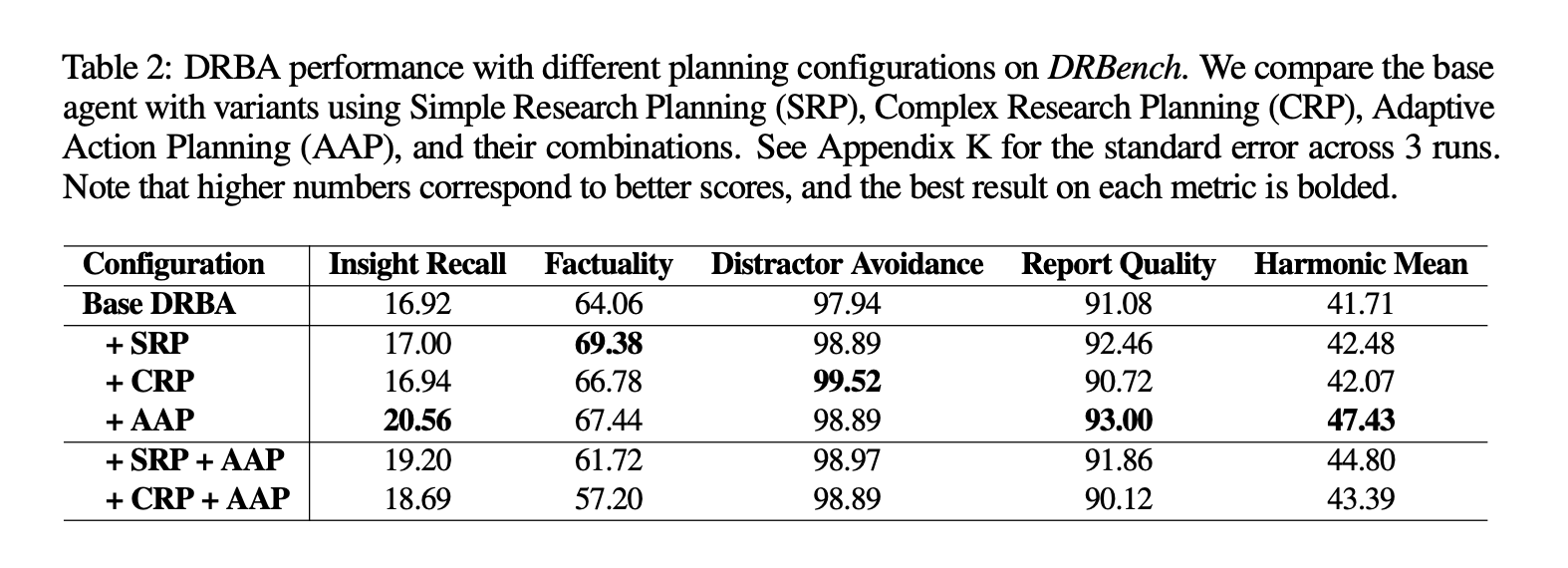
The research team introduced task-oriented baselines, DRBench Agent (DRBA)designed to run natively in the DRBench environment. DRBA is divided into four parts: research planning, action planone Adaptive Action Planning (AAP) Research Cycleand report writing. Planning supports two modes: Comprehensive Research Plan (CRP)which specifies the area of investigation, expected sources, and success criteria; and Simple Research Plan (SRP)which generates lightweight subqueries. The research cycle iteratively selects tools, processes content (including storage in vector stores), identifies gaps, and continues until completion or maximum iteration budget is reached; report authors track comprehensive findings via citations.
Why this matters for enterprise agencies?
Most “deep research” proxies look compelling on public network problem sets, but production use depends on reliable Find the right inner needle, Ignore seemingly legitimate internal distractionsand Quote Public and private sources under enterprise restrictions (logins, permissions, UI friction). DRBench’s design directly addresses this gap by: (1) grounding tasks in realistic company/role contexts; (2) distributing evidence across multiple enterprise applications and networks; (3) scoring whether agents actually extract expected insights and Wrote a coherent and truthful report. This combination makes it a practical benchmark for system builders who need end-to-end assessment rather than micro-scores from a single tool.
Main points
- DRBench evaluates complex, open-ended deep research agents enterprise Tasks that require combining public network and private company data.
- Initial release covers 15 tasks across 10 areaseach based on real-life user roles and organizational contexts.
- Tasks span heterogeneous enterprise artifacts (productivity software, cloud file systems, email, chat) as well as open networks, beyond network-only settings.
- Report rating is insight recall, factual accuracyand Coherent, well-structured reporting Use rubric-based assessment.
- Code and benchmark assets are open sourced on GitHub to allow for repeatable evaluation and scaling.
From the perspective of enterprise evaluation, DRBench is a useful step towards standardized, end-to-end testing of “deep-dive” agents: tasks are open-ended, based on realistic roles, and require the integration of public network and a Private Company Knowledge Baseand then produce a coherent, well-structured report—the kind of workflow most production teams care about. The release also clarifies what is being measured –recall relevant insights, factual accuracyand reporting quality—while explicitly moving beyond web-only settings that over-fit browsing heuristics. this 15 tasks across 10 areas Moderate in scale, but large enough to expose system bottlenecks (retrieval across heterogeneous artifacts, reference rules, and planning loops).
Check Paper and GitHub page. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.
?")

