dots.ocr It is an open source visual transformer model developed for multilingual document layout parsing and optical character recognition (OCR). It performs layout detection and content recognition in a single architecture, supports over 100 languages and a wide range of structured and unstructured document types.
architecture
- Unified Model: DOTS.OCR combines layout detection and content recognition into a neural network based on a single transformer. This eliminates the complexity of individual detection and OCR pipelines, allowing users to switch tasks by adjusting input prompts.
- parameter: The model contains 1.7 billion parameters, which in most practical cases balances computing efficiency and performance.
- Input flexibility: The input can be an image file or a PDF document. The model has preprocessing options such as FITZ_PREPROCESS to optimize quality on low resolution or dense multi-page files.
Function
- multilingual: DOTS.OCR is trained on datasets spanning over 100 languages, including major world languages and less common scripts, reflecting a wide range of multilingual support.
- Content extraction: The model extracts plain text, tabular data, mathematical formulas (latex), and preserves the order of reading in the document. The output format includes structured JSON, Markdown, and HTML, depending on the layout and content type.
- Reserve structure: DOTS.OCR maintains document structures, including table boundaries, formula areas and image placement, ensuring that the extracted data remains true to the original document.
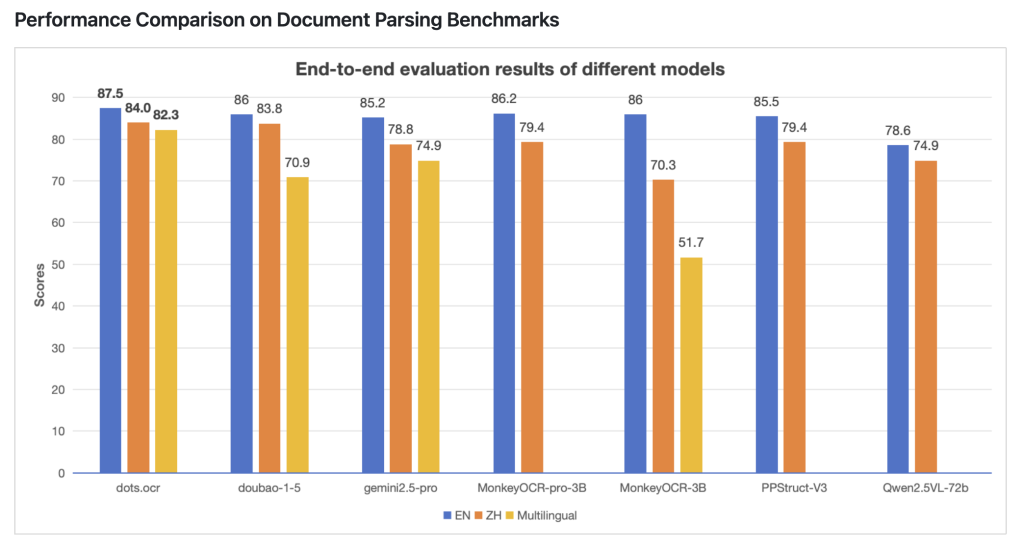
Benchmark performance
DOTS.OCR has been evaluated for modern document AI systems, and the results are summarized below:
| Benchmark | dots.ocr | Gemini 2.5-Pro |
|---|---|---|
| Table of the accuracy of TED | 88.6% | 85.8% |
| Text editing distance | 0.032 | 0.055 |
- surface: The accuracy of the table analysis is better than that of gemini2.5-Pro.
- text: Demonstrate lower text editing distance (indicates higher accuracy).
- Formulas and layouts: Match or exceed the leading models in formula recognition and document structure reconstruction.
Deployment and integration
- Open Source: Under the MIT license, sources, documentation and pre-trained models are provided on GitHub. This repository provides installation instructions for PIP, CONDA and Docker-based deployments.
- APIs and scripts: Supports flexible task configuration via prompt templates. The model can be used in batch document processing in interactive or automated pipelines.
- Output format: The extracted results are provided in structured JSON for programmatic use and, where appropriate, options for Markdown and HTML. The visual script can check the detected layout.
in conclusion
DOTS.OCR provides a highly critical, multilingual document parsing technical solution by unifying layout detection and content recognition in a single open source model. It is particularly suitable for solutions that require robust, language-sensitive document analysis and structured information extraction in resource constraints or production environments.
Check Github page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


