Salesforce AI Research launches xRouter: a reinforcement learning router for cost-aware LLM orchestration
When your application can call many LL.M.s of varying prices and abilities, who should decide which one answers each request? The Salesforce AI research team has launched “xRouter,” a tool-invocation-based routing system that addresses this gap with a reinforcement learning-based router and learns when to answer locally and when to call an external model, while tracking token-level costs.
What is an x-router?
xRouter is an orchestration system based on tool calls, built with Qwen2.5-7B-Instruct as the backbone of the router. A router is an instruction-tuned model with tool invocation capabilities that determines which downstream model to call, how to prompt it, and whether to synthesize or select answers. The implementation uses DAPO (Distributed Advantage Policy Optimization) within the Verl reinforcement learning framework and exposes an OpenAI compatible API.
The router runs over 20 LLM tools throughout the system. The tools cover Advanced, Standard, Budget and Professional levels and include GPT-5, GPT-4.1, GPT-5-Mini, GPT-5-Nano, o3, Kimi K2, DeepSeek-R1, Qwen3-235B variants and GPT-OSS models. The offload pool is a 12-model subset that includes GPT-5, GPT-5-Mini, GPT-5-Nano, GPT-4o, GPT-4.1, o3, o3-Pro, o4-Mini, GPT-OSS-120B, GPT-OSS-20B, and two Gemini-2.5 variants.
Cost-aware rewards and success gating
Routing is viewed as a reinforcement learning problem. For each episode, the reward combines a binary success signal with a cost penalty. The research team defined a reward that gave a fixed bonus when the final answer was correct, and then subtracted a term proportional to the total normalized cost of all model calls. If the answer is wrong, no matter how cheap the price is, the reward is zero.
According to the model weights page, reward = quality − λ × normalized_costwhere λ is the cost penalty coefficient. Episodes that fail actually have zero quality. This “success-gated, cost-shaping” goal forces routers to first achieve correctness and then optimize cost in a success strategy. In practice, training uses 3 cost penalty settings, which results in xRouter-7B-1, xRouter-7B-2, and xRouter-7B-3 variants.
Training data and signal design
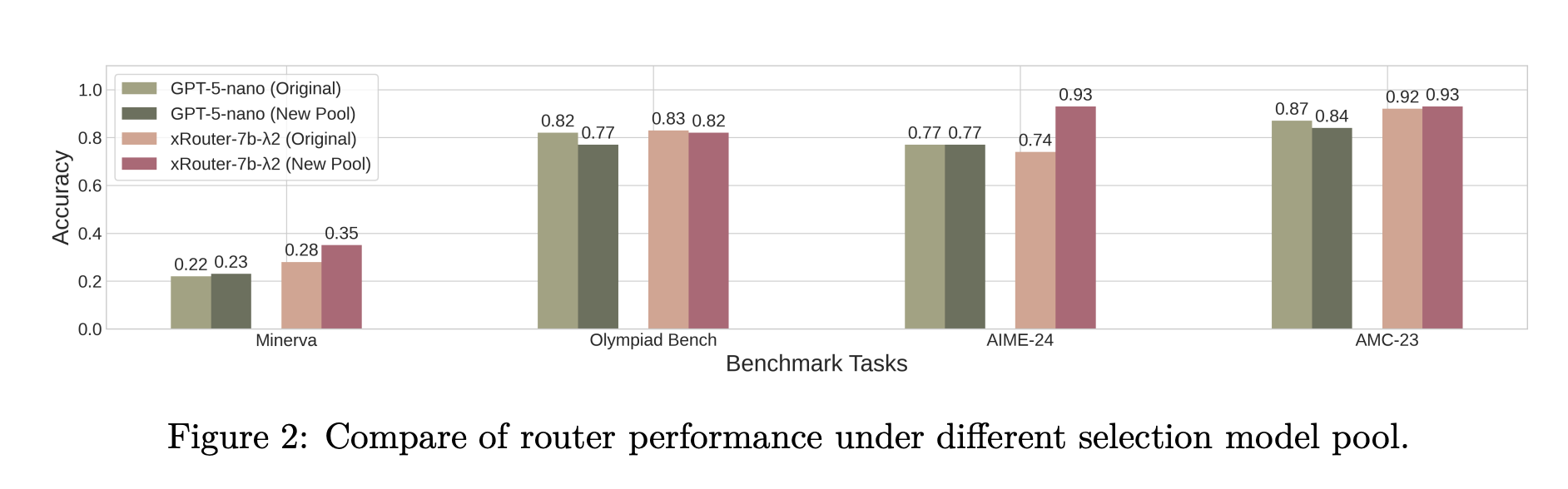
The xRouter training data comes from Reasoning360, which includes math, coding, and general reasoning tasks, and its difficulty estimates are derived from the powerful reference model Qwen3-32B. The research team divided the samples into three levels: easy, medium, and difficult, and added easier small talk, retrieval, and factual questions to teach routers when to answer directly without delegation. Each example includes descriptions and prices for different levels of models. The system also refreshes the model catalog and scrambles costs to avoid overfitting the static price list.
Failed trajectories, such as wrong answers from expensive models or unnecessary calls that the router could have answered on its own, still incur the full cost and receive zero reward. This produces a clean learning signal where correctness gate rewards and costs determine the routing strategy.
How the router behaves during inference?
The router supports three execution modes. It can answer directly from the backbone without invoking tools. It can call one or more downstream models and then use its own reasoning about the output to synthesize a response. It can also call downstream models and use special select_response Tool for selecting one of the responses as the final answer. These modes are implemented through function calls in an OpenAI-style interface, which the orchestration engine executes through LiteLLM and SGLang.
As a rule of thumb, trained xRouter instances use a mixture of direct responses and synthetic responses. Off-the-shelf routers such as GPT-4o, GPT-4.1, GPT-5, Qwen2.5-7B, and Qwen3-8B tend to respond directly in most cases, even when instructed to offload in uncertainty. This is an important behavioral difference and explains part of the efficiency gain.
Quantitative results and cost-effectiveness
On static routing baselines of Minerva, MATH-500, Olympiad Bench, AIME-24, AMC-23, Codeforces, Code-Contests, and Human-EvalPlus, the xRouter-7B variant consistently improves accuracy compared to using the same base model as the untrained router. For example, xRouter-7B-2 achieves accuracy close to GPT-5 on the Olympiad benchmark while using approximately one-eighth the evaluation cost of GPT-5.
In system-level comparisons on LiveCodeBenchv5, GPQADiamond, AIME25, MT-Bench, IFEval and LiveBench, xRouter-7B-3 achieved the highest average accuracy on LiveCodeBenchv5 among all tested systems at a moderate cost. On tasks such as GPQA, the xRouter variant can achieve around 80% to 90% of the accuracy of GPT-5 while consuming less than one-fifth of the cost. The research team concluded that their cost-aware reward could reduce inference costs by up to 80% at similar completion rates. This model of weighted HF card reports cost reductions of up to 60% for equivalent quality in other settings.
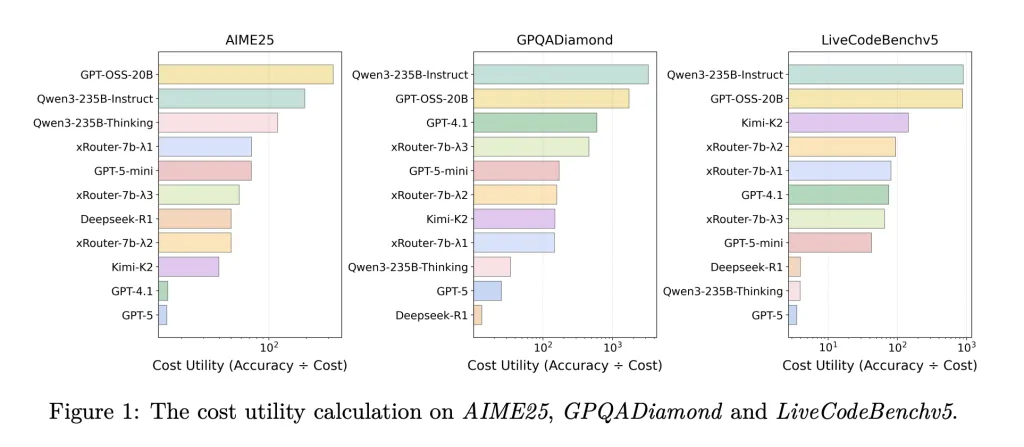
The research team also defined “cost utility” as accuracy divided by cost. Open source single models with very low API prices often achieve higher cost-utility but lower absolute accuracy. xRouter sits in the middle, trading some cost utility for greater task performance, which is typically a concern for production systems.
Main points
- xRouter is a tool for calling routers built on Qwen2.5 7B Instruct. It learns to select among more than 20 external LLMs through explicit cost-aware reinforcement learning policy learning.
- The router uses success-gated rewards, where the task only gets a positive reward if the final answer is correct, and within the success trajectory it applies a cost penalty term λ multiplied by the normalized cost, resulting in three xRouter 7B variants with different cost-accuracy trade-offs.
- Training on difficulty tiering and synthesizing simple queries on Reasoning360 teaches xRouter when to answer directly and when to offload, while perturbing prices and model pools improves robustness to changing provider directories.
- Across math, coding, and inference benchmarks, xRouter 7B models achieve near GPT 5 accuracy on difficult tasks such as Olympiad Bench, and approximately 80% to 90% GPT 5 accuracy on GPQA, while reducing offload costs by 60% to 80% depending on the evaluation setting.
Editor’s Note
xRouter is a practical step toward cost-aware orchestration of heterogeneous LLM queues. It shows that a medium-sized router trained with DAPO on Reasoning360 using success-gated, cost-forming rewards can consistently approach GPT 5 accuracy while reducing offloading costs by up to 60% to 80%.
Check Paper and model weight. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


