R-Zero: A fully autonomous AI framework that generates its own training data from scratch
Large Language Models (LLM) have taken the field from natural language understanding to reasoning and code generation. However, pushing its inference ability toward a truly superhuman level is limited by the need for large, high-quality, human-announced datasets. A team of researchers from Tencent AI Seattle Labs, University of Washington, University of Maryland and University of Texas proposed R-Zero, a framework designed to train reasoning LLMs that can develop self-development without relying on external data labels.
Data beyond humans
Most advances in LLM reasoning have bound human-curated datasets to resource-intensive and fundamentally limited by human knowledge. Even the tagless method of using LLMS’s own output to get the reward signal still depends on the existing set of unsolved tasks or problems. These dependency bottlenecks are scalable and hinder the dream of open AI reasoning beyond human capabilities.
R-Zero: Self-evolution of Zero Data
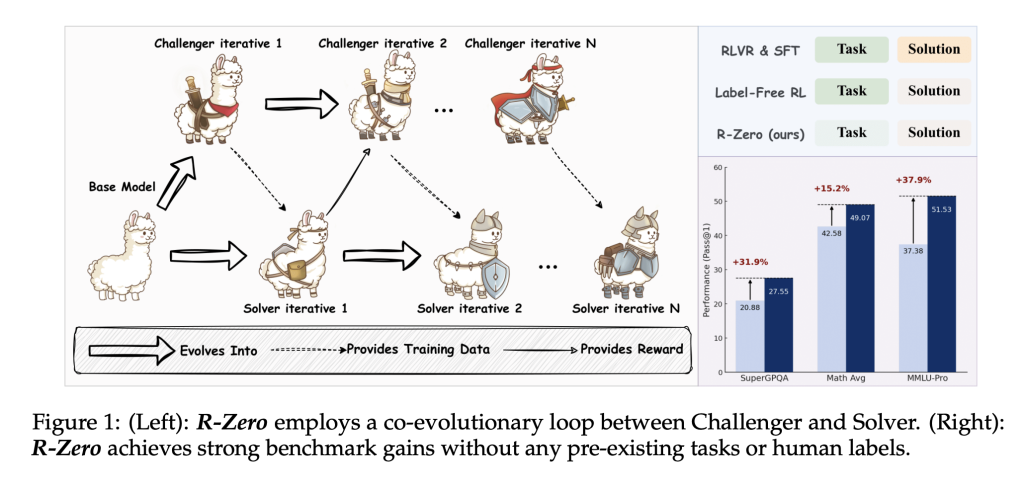
R-Zero Forge new paths by completely eliminating dependencies on external tasks and labels. Instead, it introduces a dynamic of co-evolution between two instances of the basic model:
- Challenger: Responsible for creating new, challenging inference tasks near the edge of solver functionality.
- Solver: Training can solve increasingly difficult problems brought by challengers, thereby improving iteration.
This synergy enables the course (a set of training data) to be self-generated and constantly adapt to the strengths and weaknesses of the model’s ever-evolving development. The process is as follows:
- Challenger Training: Through strengthening learning and training (especially Group relative policy optimization [GRPO]), it creates diverse and difficult to solve problems. The reward signal for each question is based on the solver’s uncertainty: the highest (empirical accuracy is close to 50%) when the solver’s answer is the largest inconsistent (empirical accuracy is close to 50%).
- Solver training: The solver fine-tunes the challenger’s selected problems. The pseudo-label (answer) depends on the majority votes in the solver’s own answer. Only the answers are neither consistent nor too dispersed (i.e., in a well-informed band) for training.
- Iterative loop: Challenger and solver replace characters, developed together in several rounds of competition, gradually improving the ability to reason without intervention.
Key technological innovations
- Group Relative Policy Optimization (GRPO)
GRPO is an enhanced learning algorithm that rewards each generated answer in the same prompt relative to each response group. This method effectively fine-tunes the policy LLM without the need for a separate value function. - Uncertainty-driven courses
Challengers are rewarded for having problems at the forefront of solvers – not easy and not impossible. The reward function reaches the peak of the task of solving the solver reaching 50% accuracy, and improves learning efficiency from theoretical analysis. - Repeat fines and format checks
To ensure diverse and well-structured training data, duplicate fines prevent similar issues in batch processing, and strict format checks ensure data quality. - Pseudo-label quality control
Use only question-solving pairs with intermediary answer consistency to filter out ambiguous or unsuitable questions and calibrate label accuracy.

Experience performance
Mathematical reasoning benchmarks
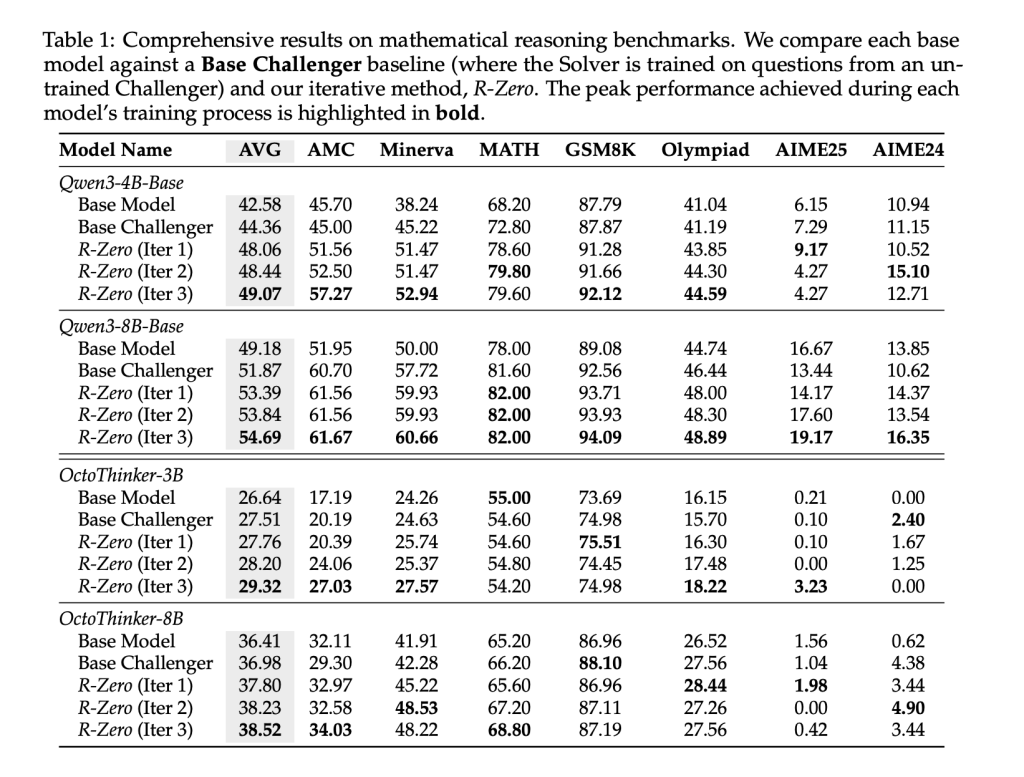
R-Zero is evaluated using seven rigorous mathematical benchmarks including AMC, Minerva, Math-500, GSM8K, Olympiad-Bench and Aime competitions. Compared with the base model and non-trained challenger baseline Three iterations of R-Zero result in substantial improvements in inference accuracy for all model sizes and architectures (For example, QWEN3-8B basically improved the average score after three iterations from 49.18 to 54.69).
General reasoning benchmarks
Crucially, R-Zero improvements Beyond Mathematics. Benchmarks including MMLU-PRO, SUPERGPQA, and Big Bench Extry Hard (BBEH) exhibited a significant increase in general domain inference accuracy (e.g., the overall mean average of QWEN3-8B-BASE from 34.49 to 38.73), indicating a strong transfer effect.
in conclusion
R-Zero marks a major milestone towards self-sufficiency Superman reasoning LLM. Its fully autonomous co-evolution training pipeline not only provides a huge experience growth in reasoning, but also provides new lenses for viewable scalable data-free development. Researchers and practitioners can try this framework today, leveraging open source tools to pioneer the next era of inference-centric language models.
Check Paper and Github page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Sajjad Ansari is a final year undergraduate student from IIT Kharagpur. As a technology enthusiast, he delves into the practical application of AI, focusing on understanding AI technology and its real-world impact. He aims to express complex AI concepts in a clear and easy way.


