Prefix RFT: A unified machine learning framework for hybrid supervised fine tuning (SFT) and reinforced fine tuning (RFT)
Large language models are often refined after preprocessing using supervised fine tuning (SFT) or enhanced fine tuning (RFT), and each language model has obvious advantages and limitations. SFT can effectively teach guided tracking through example-based learning, but can lead to rigid behavior and poor generalization. RFT, on the other hand, uses reward signals to optimize the model of successful tasks, which can improve performance while also causing instability and dependence on strong starting policies. Although these methods are often used sequentially, their interactions are still rarely understood. This raises an important question: How do we design a unified framework that combines SFT structures with goal-driven learning of RFT?
Research on intersections after RL and LLM training has gained momentum, especially for training inference models. Offline RLs learned from fixed datasets often result in suboptimal policies due to data diversity. This has sparked interest in combining offline and online RL approaches to improve performance. In LLM, the main strategy is to first apply SFT to teach ideal behavior and then use RFT to optimize the results. However, the dynamics between SFT and RFT are still under-understood, and finding effective ways to integrate them remains an open research challenge.
Researchers at the University of Edinburgh, Fadan University, Alibaba Group, Stepfun and the University of Amsterdam have proposed a unified framework that combines supervised and enhanced fine-tuning in a way called prefix-rft. This approach uses partial demonstration guidance to explore, allowing the model to continue to generate solutions that are flexible and adaptable. Tested on mathematical reasoning tasks, prefix RFT always outperforms independent SFT, RFT and hybrid policy approaches. It is easily integrated into existing frameworks and demonstrates the robustness of presentation quality and quantity variations. The integration of demonstration-based learning and exploration will lead to more effective and adaptive training for large language models.
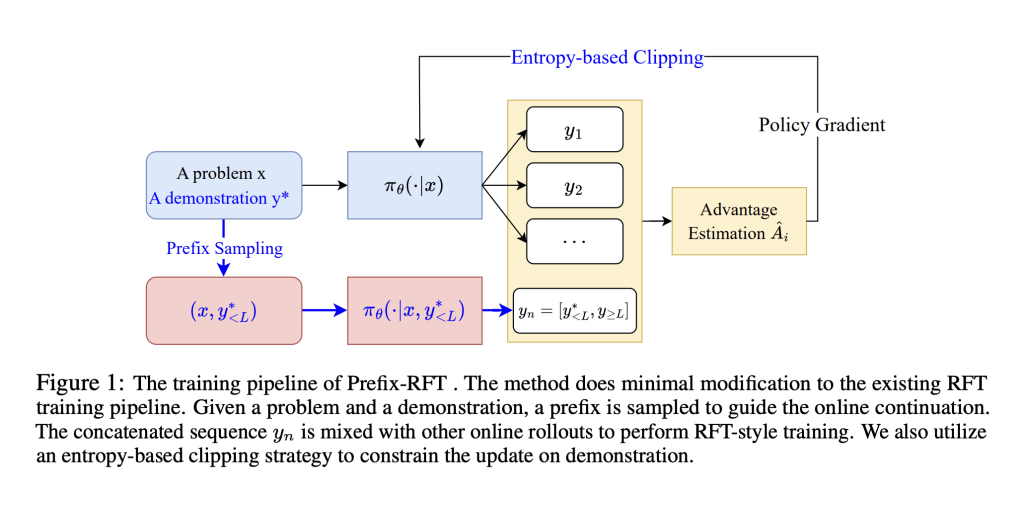
This study introduces the advantages of prefix reinforcement fine-tuning (prefix RFT) to fuse SFT and RFT. Although SFT provides stability through imitating expert demonstrations, RFT encourages exploration by using reward signals. Prefix RFT is demonstrated by using partials (prefixes) and letting the model generate the rest. This method guides learning without overly relying on all supervision. It combines technologies such as entropy-based tailoring and cosine decay scheduler to ensure stable training and effective learning. Prefix RFT provides a more balanced and adaptable fine-tuning strategy compared to previous methods.
Prefix RFT is a reward fine-tuning method that can improve performance using high-quality offline mathematical datasets such as OpenR1-Math-220k (46K filtering problem). Tests were conducted on QWEN2.5-MATH-7B, 1.5B and LLAMA-3.1-8B and evaluated on benchmarks including AIME 2024/25, AMC, Math500, Math500, Minerva, and Olympiadbench. The prefix RFT reached the highest AVG@32 and surpassed 1 point on the task, exceeding RFT, SFT, Relift and Luffy. Using Dr. Grpo, it updates only the top 20% of the high-entry prefix tokens, with the prefix length decayed from 95% to 5%. It maintains the SFT loss in the middle, indicating a strong balance between imitation and exploration, especially on difficult issues (Trainhard).

In summary, prefix RFT combines the advantages of SFT and RFT by leveraging sampled demonstration prefixes to guide learning. Although it is simple, it always outperforms SFT, RFT and hybrid baselines in a variety of models and datasets. Even with only 1% of the training data (450 tips), it still maintains strong performance (AVG@32 only dropped from 40.8 to 37.6), showing efficiency and robustness. Its top 20% entropy-based token update strategy proves the most effective effect, achieving the highest benchmark score with shorter yields. Furthermore, using a cosine decay scheduler for prefix length, especially on complex tasks such as AIME, can enhance stability and learning dynamics compared to unified strategies.
Check The paper is here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Sana Hassan, a consulting intern at Marktechpost and a dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. He is very interested in solving practical problems, and he brings a new perspective to the intersection of AI and real-life solutions.


