PokeeResearch-7B: An open 7B deep research agent trained with AI Feedback Reinforcement Learning (RLAIF) and powerful inference scaffolding
Puji Artificial Intelligence Already open source PokeeResearch-7Ba 7B parameter deep research agent that performs a complete research loop, decomposes the query, issues search and read calls, validates candidate answers, and then synthesizes multiple research threads into a final response.
Agents run research and validation cycles. In research, it calls on external tools to perform web searches and page readings or to come up with provisional answers. During the validation process, it checks the answer against the retrieved evidence and accepts or restarts the study. This structure reduces brittle traces and catches obvious errors before they are finalized. The research team formalized this cycle and added a test-time synthesis phase that merged multiple independent research threads.
Training recipes, RLAIF and RLOO
PokeeResearch-7B fine-tuned from Qwen2.5-7B-Instruct using no annotations Reinforcement learning based on AI feedback, called RLAIF,and Enhanced leave-one-out algorithm, called RLOO. Rewards target semantic correctness, reference fidelity, and directive compliance, not token overlap. The model’s Hugging Face card lists a batch size of 64, 8 research threads per tip during reinforcement learning, a learning rate of 3e-6, 140 steps, context of 32,768 tokens, bf16 accuracy, and nearly 13 GB of checkpoints. The research team emphasized that RLOO provides an unbiased policy gradient and compared it with a family of biased PPOs that approximate policies.
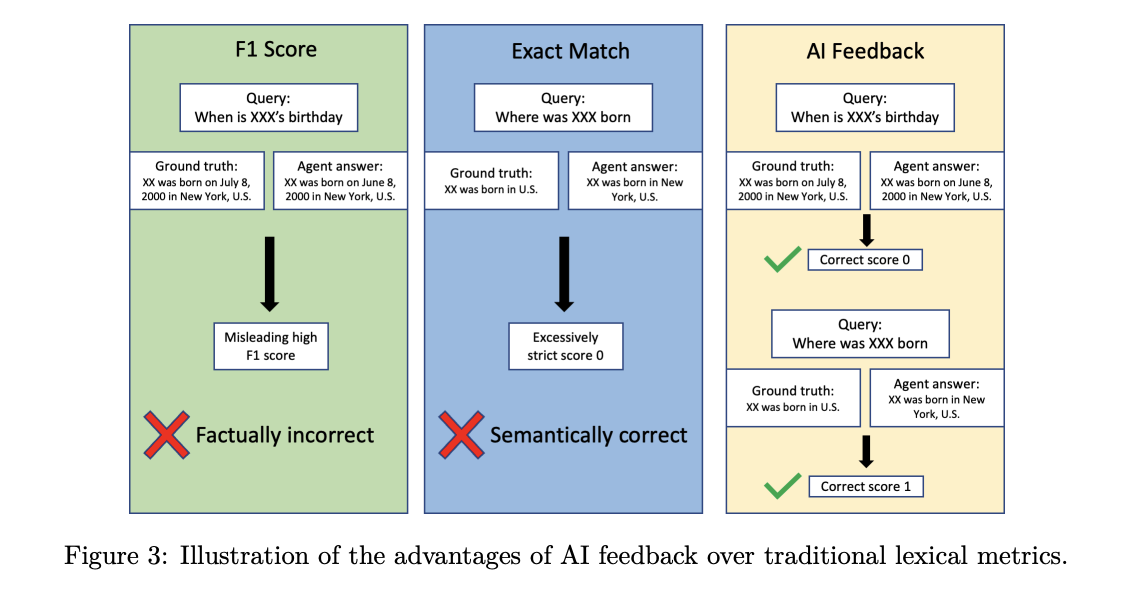
Inference scaffolding and research lead synthesis
The stand consists of three mechanisms. Self-correcting, the agent detects malformed tool calls and retries. Self-validation, where the agent checks its own answer against evidence. Study thread synthesis, where the agent runs multiple independent threads for each question, summarizes them, and then synthesizes the final answer. The team reports that synthesis improves accuracy on difficult benchmarks.
Evaluation plan
The research team evaluated plain text questions on 10 benchmarks: NQ, TriviaQA, PopQA, HotpotQA, 2WikiMultiHopQA, Musique, Bamboogle, GAIA, BrowseComp, and Humanity’s Last Exam. They sampled 125 questions for each dataset (GAIA sampled 103 questions), for a total of 1,228 questions. For each question, they ran 4 study threads and then used Gemini-2.5-Flash-lite to calculate the average accuracy (mean was 4) to judge correctness. The maximum number of interactions is set to 100.
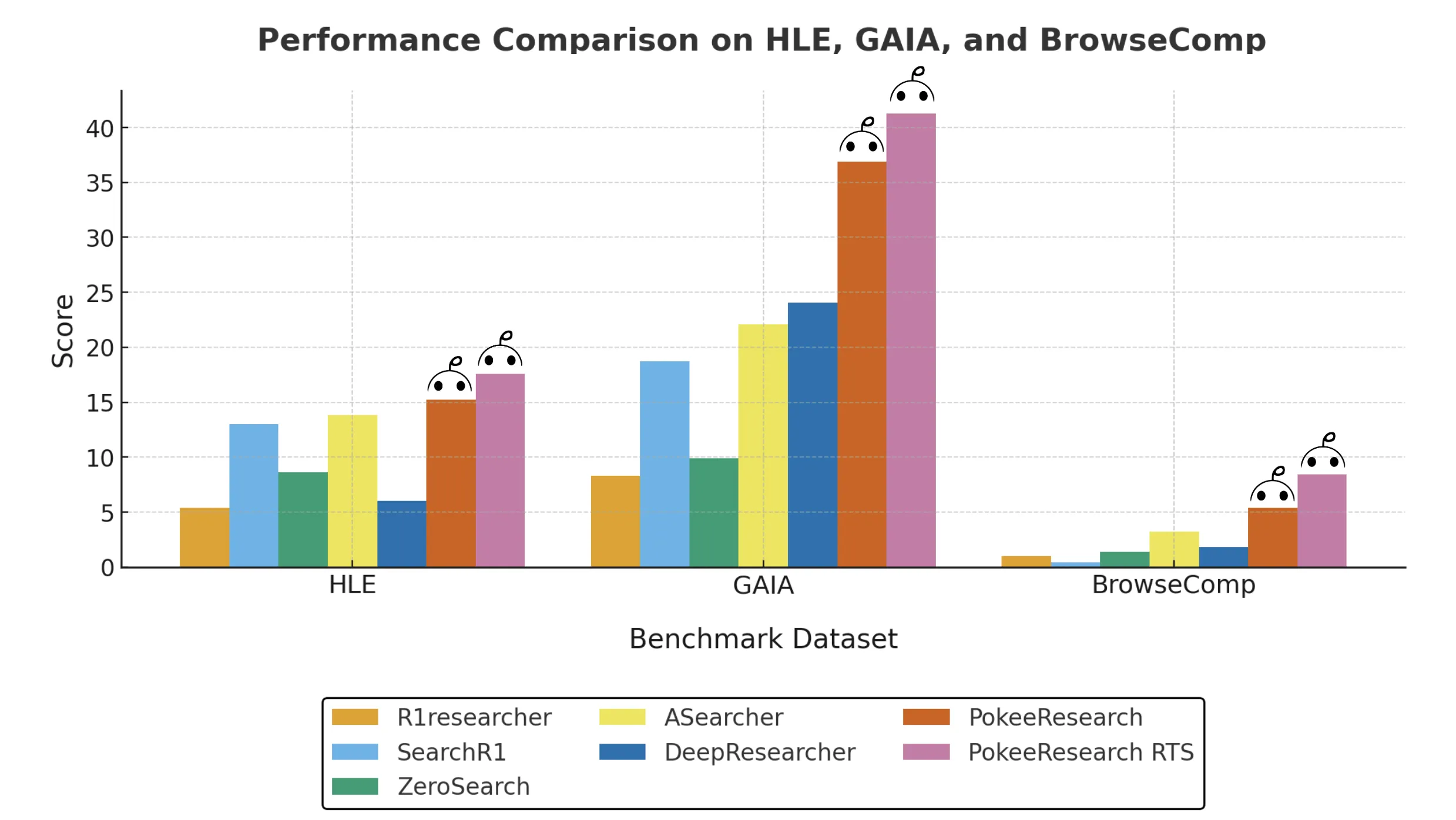
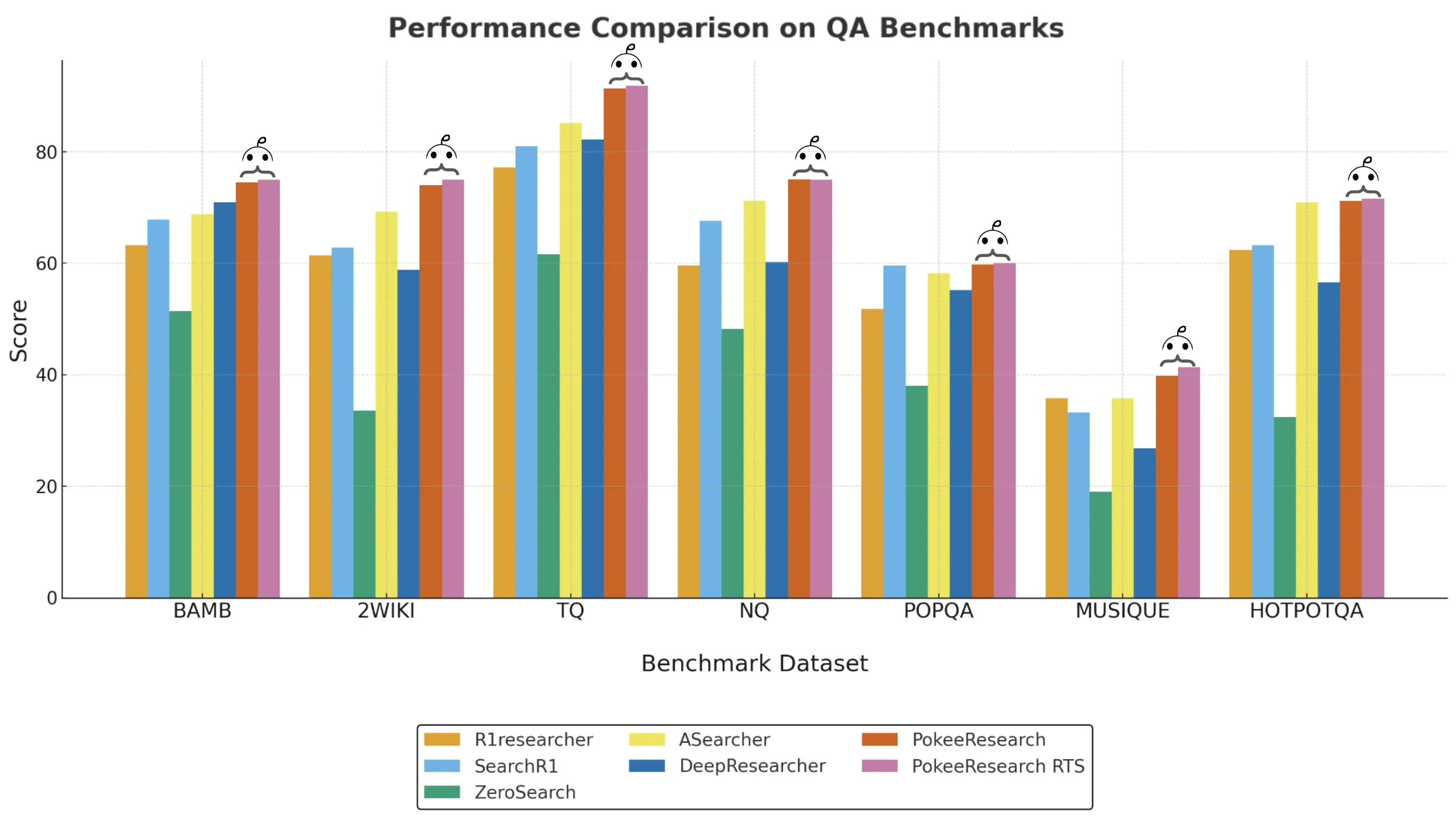
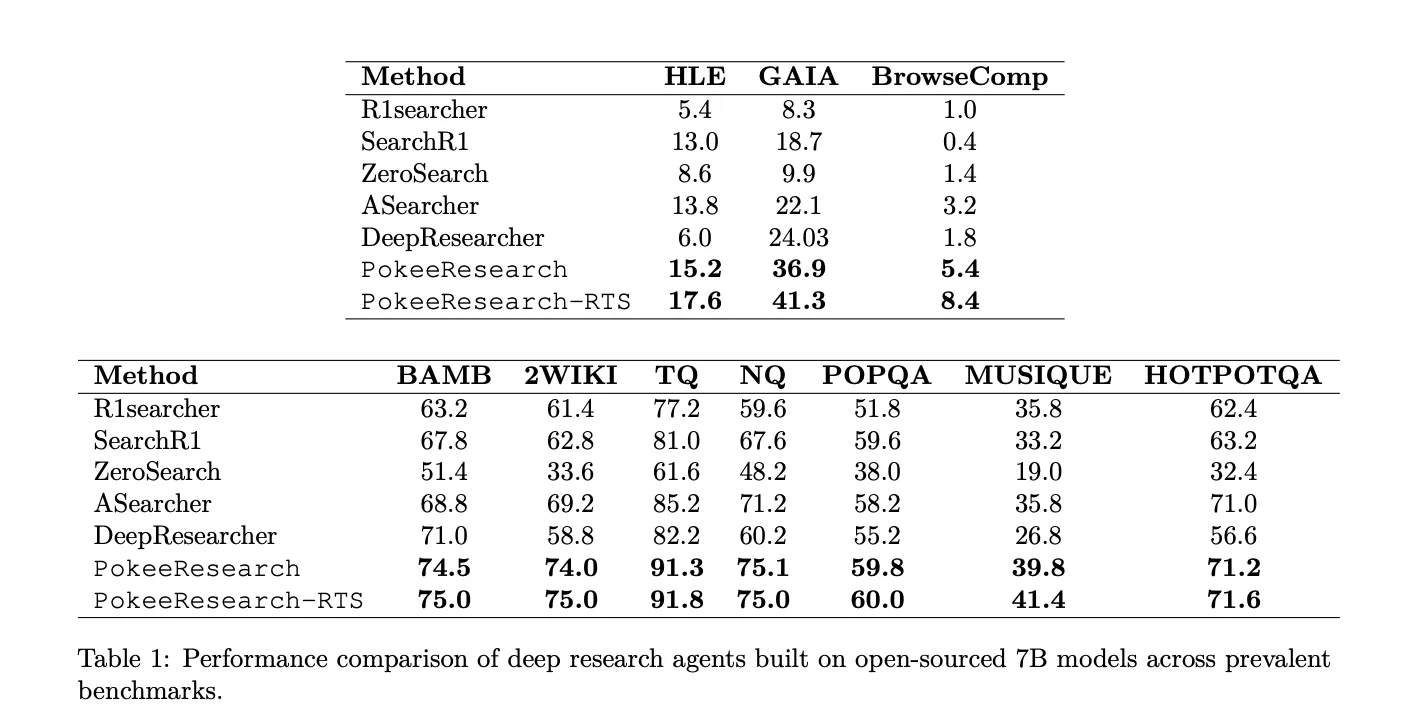
7B scale results
PokeeResearch-7B reports the best average of 7B deep research agents at 4 accuracy across 10 datasets. On HLE, the model reports 15.2 without RTS and 17.6 with RTS. On GAIA, the model reports 36.9 without RTS and 41.3 with RTS. On BrowseComp, the model reports 5.4 without RTS and 8.4 with RTS. The model improves over the recent 7B baseline on seven QA benchmarks: Bamboogle, 2WikiMultiHopQA, TriviaQA, NQ, PopQA, Musique, and HotpotQA. The benefit of RTS is largest on HLE, GAIA and BrowseComp, and smaller on the QA set.
Main points
- train: PokeeResearch-7B Fine-tunes Qwen2.5-7B-Instruct with RLAIF using the RLOO estimator, optimizing rewards for factual accuracy, citation fidelity, and instruction compliance rather than marking overlap.
- scaffold: The agent runs a research and verification loop through a research thread, executing multiple independent threads and then combining the evidence to arrive at a final answer.
- Evaluation plan: Benchmarks span 10 datasets with 125 questions each, except GAIA with 103 per dataset, 4 threads per question, average @4 accuracy judged by Gemini-2.5-Flash-lite, capped at 100 times.
- Results and release: PokeeResearch-7B reports the latest technology of 7B deep research agents, such as HLE 17.6 with RTS, GAIA 41.3 with RTS, BrowseComp 8.4 with RTS, and released under Apache-2.0, with the code and weights made public.
PokeeResearch-7B is a useful step forward for actual deep research on proxies. It uses RLOO to align training with RLAIF and thus targets semantic correctness, reference fidelity, and instruction compliance. Reasoning scaffolding includes self-validation and research thread synthesis, which improve difficult benchmarks. This evaluation uses the average of 10 data sets4, using Gemini 2.5 Flash lite as the criterion. This release releases Apache 2.0 code and weights, as well as a clear tool stack using Serper and Jina. This setup runs on a single A100 80 GB and is expandable.
Check Paper, HF model and GitHub repository. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


