Perplexity AI releases TransferEngine and pplx Garden to run trillion-parameter LLM on existing GPU clusters
How can teams run tera-parameter language models on existing hybrid GPU clusters without expensive new hardware or deep vendor lock-in? Perplexity’s research team released TransferEngine and the surrounding pplx Garden toolkit as an open source infrastructure for large-scale language model systems. This provides a way to run models with up to 1 trillion parameters across hybrid GPU clusters without locking into a single cloud provider or purchasing new GB200-class hardware.
The real bottleneck is the network structure not the failure
Modern deployed hybrid expert models such as DeepSeek V3 with 671 billion parameters and Kimi K2 with 1 trillion parameters no longer fit on a single 8-GPU server. They must span multiple nodes, so the main constraint becomes the network structure between GPUs.
The hardware landscape here is fragmented. NVIDIA ConnectX 7 is typically delivered over a reliable connection and delivered in sequence. AWS Elastic Fabric Adapter uses reliable but out-of-order scalable reliable datagram transport, and a single GPU may require 4x 100 Gbps network adapters, or 2x 200 Gbps network adapters to reach 400 Gbps.
Existing libraries such as DeepEP, NVSHMEM, MoonCake, and NIXL are often optimized for one vendor and have reduced or lack of support on the other side. Perplexity’s research team points out directly in the research paper that prior to this work, there were no viable cross-provider solutions for LLM inference.
TransferEngine, the portable RDMA layer of LLM systems
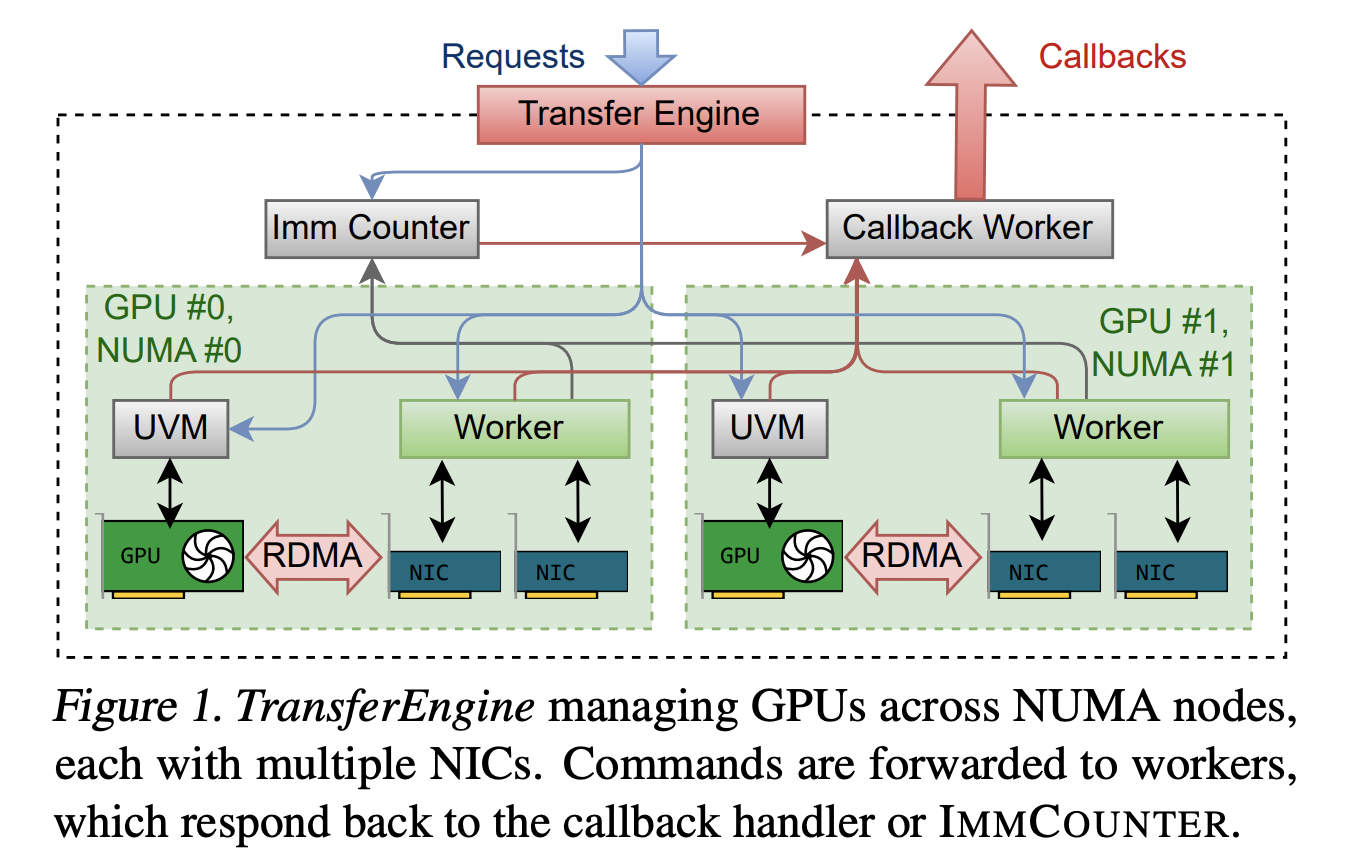
TransferEngine solves this problem by only targeting guaranteed intersection between network interface controllers. It assumes that the underlying RDMA transport is reliable but does not assume any message ordering. Among other things, it exposes a WriteImm operation on one side and an ImmCounter primitive for completion notifications.
This library provides the minimal API in Rust. It provides two-sided send and receive for control messages, and three main one-sided operations, submit_single_write, submit_paged_writesand submit_scatterplus one submit_barrier Primitives for synchronizing between a set of peers. The NetAddr structure identifies the peer, and the MrDesc structure describes the registered memory area. The alloc_uvm_watcher call creates a device-side watcher for CPU GPU synchronization in advanced pipelines.
Internally, TransferEngine spawns a worker thread for each GPU and builds a DomainGroup for each GPU to coordinate between 1 and 4 RDMA network interface controllers. A single ConnectX 7 delivers 400 Gbps. On an EFA, a DomainGroup aggregates four 100 Gbps network adapters or two 200 Gbps network adapters to achieve the same bandwidth. Sharding logic knows about all network interface controllers and can split transmissions between them.
On the hardware side, the research team reports peak throughput of 400 Gbps for NVIDIA ConnectX 7 and AWS EFA. This matches a single platform solution and confirms that the abstraction layer does not leave a large performance penalty.

pplx Garden, open source package
TransferEngine is released under the MIT license as part of the pplx garden repository on GitHub. The directory structure is simple. fabric-lib Contains the RDMA TransferEngine library, p2p-all-to-all Implement expert blending for all cores, python-ext Provides Python extension modules from Rust core, and python/pplx_garden Contains Python package code.
System requirements reflect modern GPU clusters. The Perplexity research team recommends using Linux kernel 5.12 or higher to support DMA BUF, CUDA 12.8 or higher, libfabric, libibverbs, GDRCopy, and RDMA structures with GPUDirect RDMA enabled. Each GPU should have at least one dedicated RDMA network interface controller.
Break down pre-filling and decoding
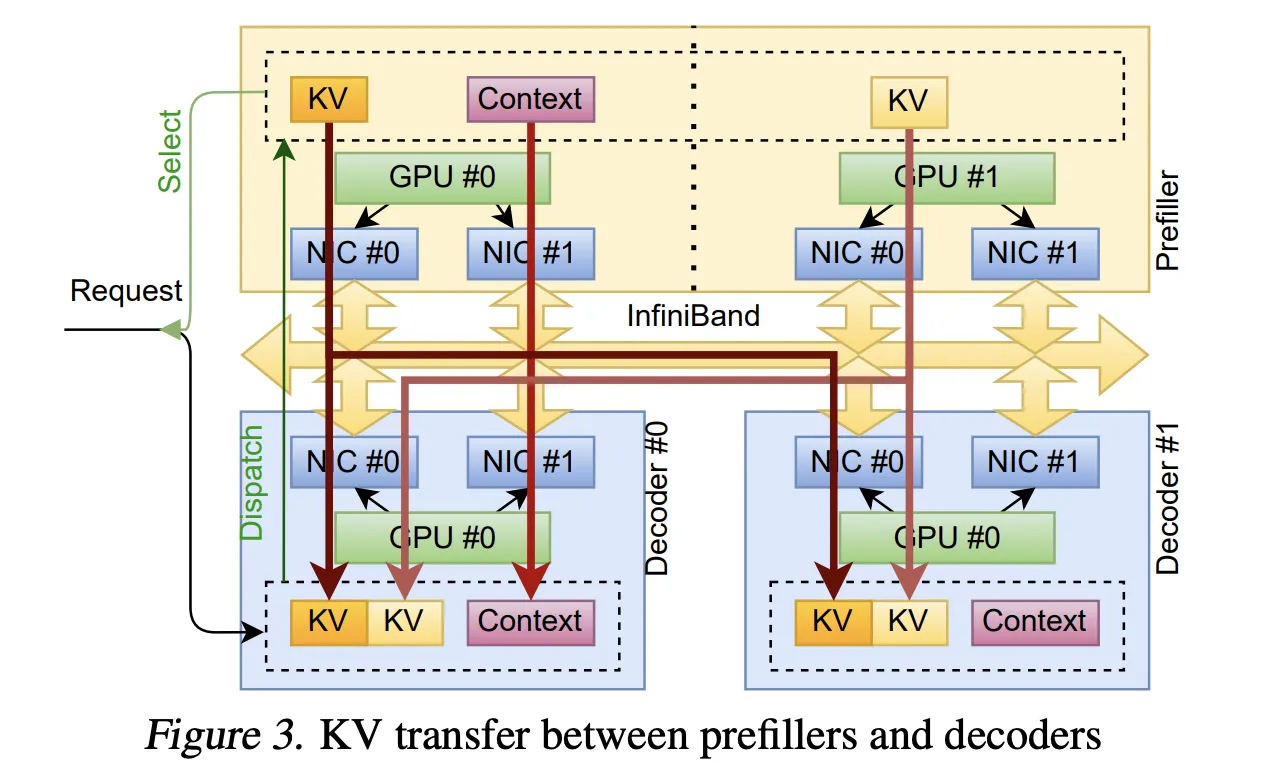
this first The production use case is classification inference. Prepopulation and decoding run on different clusters, so the system must stream KvCache from the prepopulation GPU to the decode GPU at high speed.
TransferEngine uses alloc_uvm_watcher to track progress in the model. During pre-filling, the model increments the observer value after each layer’s attention output projection. When a worker observes a change, it issues a paged write to the layer’s KvCache page, and then a single write to the remaining context. This approach allows cached pages to be streamed layer by layer without requiring fixed world membership and avoids strict ordering constraints on the collective.
Fast weight transfer for reinforcement learning
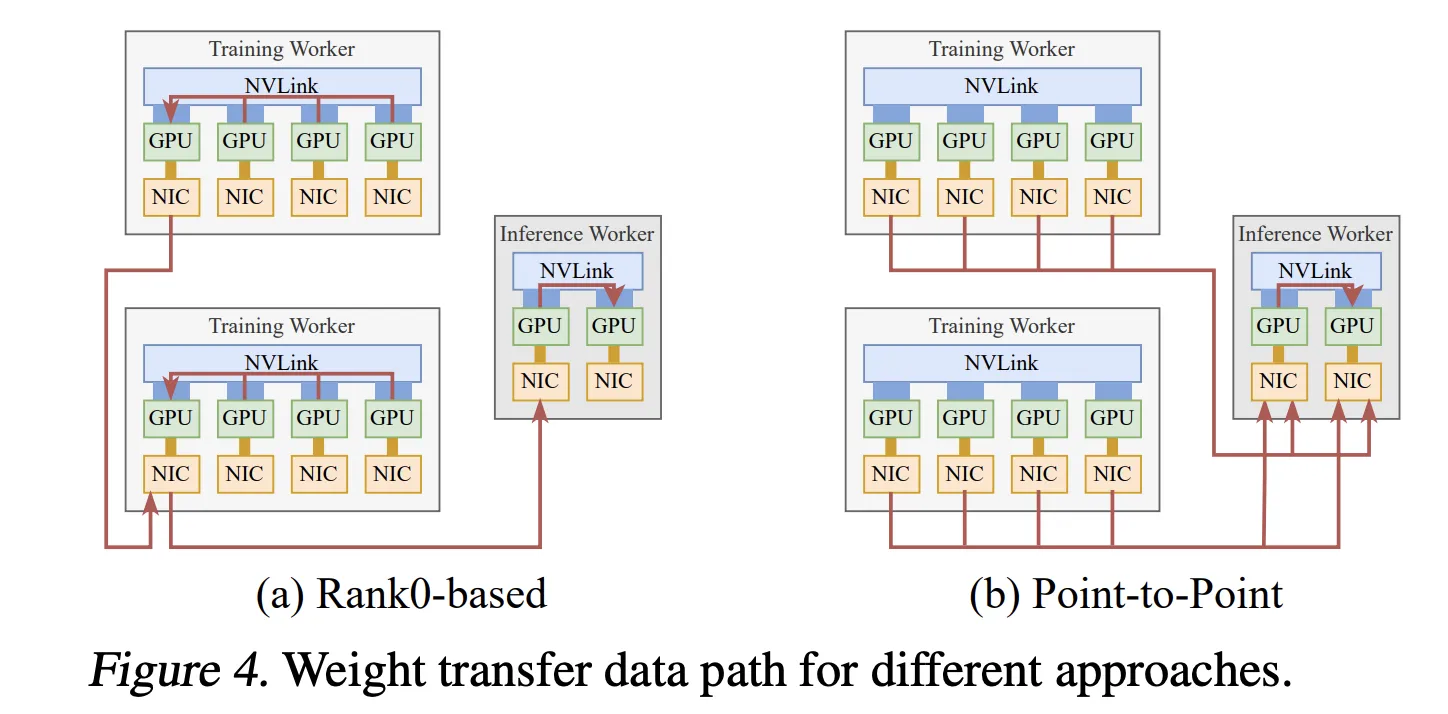
this second The system is asynchronous reinforcement learning fine-tuning, with training and inference running on separate GPU pools. Traditional designs collect updated parameters into a single level and then broadcast them, which limits the throughput of a network interface controller.
The Perplexity research team uses TransferEngine to perform point-to-point weight transfers. Each training GPU writes its parameter shards directly to the corresponding inference GPU using one-sided writes. Pipeline execution splits each tensor into multiple stages, fully sharded data, host-to-device copy when offloading weights in parallel, reconstruction and optional quantization, RDMA transfers, and barriers implemented via scatter and ImmCounter.
In production, this setup can provide weight updates for models such as Kimi K2 with 1 trillion parameters and DeepSeek V3 with 671 billion parameters in approximately 1.3 seconds from 256 training GPUs to 128 inference GPUs.
Hybrid expert routing across ConnectX and EFA
this third One piece of the pplx garden is a hybrid of point-to-point expert scheduling and compositional kernels. It uses NVLink for intra-node traffic and RDMA for inter-node traffic. Scheduling and combining are split into separate transmit and receive stages so that the decoder can be micro-batched and communicated with grouped generic matrix multiplication overlaps.
The host agent thread polls the GPU status and calls TransferEngine when the send buffer is ready. Routes are first exchanged, then each rank calculates the consecutive receive offsets for each expert and writes the tokens to a private buffer that can be reused between schedules and combinations. This reduces the memory footprint and keeps write volumes large enough to use the full link bandwidth.
On ConnectX 7, the Perplexity research team reports state-of-the-art decoding latency that is competitive with DeepEP in terms of number of experts. On AWS EFA, the same core provides the first feasible MoE decoding latency, with higher but still practical value.
In multi-node tests using DeepSeek V3 and Kimi K2 on AWS H200 instances, the cross-node distribution model reduced latency for medium batch sizes, a common mechanism for production services.
comparison table
| Key points | TransferEngine (pplx garden) | Deep EP | NVSHMEM (used by the General Education Department) | moon cake |
|---|---|---|---|---|
| main character | Portable RDMA point-to-point for LLM systems | MoE all scheduled and consolidated | General purpose GPU shared memory and collective | Distributed KV cache for LLM inference |
| Hardware focus | NVIDIA ConnectX 7 and AWS EFA, multiple NICs per GPU | NVIDIA ConnectX with GPU-Initiated RDMA IBGDA | NVIDIA GPUs on RDMA architecture (including EFA) | RDMA NIC in KV-centric service stack |
| state of education for all | Fully supported, reports peak 400 Gbps | Not supported, requires IBGDA on ConnectX | API works, but use of MoE shows severe degradation of EFA | Paper reports that its RDMA engine does not support EFA |
| Portability of LLM systems | Single API across vendors, ConnectX 7 and EFA | Vendor-specific and ConnectX-centric | NVIDIA-centric, not available for EFA MoE routing | Focus on KV sharing, no cross-provider support |
Main points
- TransferEngine provides a single RDMA point-to-point abstraction that runs on NVIDIA ConnectX 7 and AWS EFA and transparently manages multiple network interface controllers per GPU.
- The library exposes a sided WriteImm with an ImmCounter and achieves a peak throughput of 400 Gbps on two NIC families, allowing it to match a single vendor stack while maintaining portability.
- The Perplexity team uses TransferEngine in three production systems, using KvCache streams for decomposed pre-fill decoding, reinforcement learning weight transfers that update trillion-parameter models in about 1.3 seconds, and Mixture of Experts scheduling composition for large models like Kimi K2.
- On ConnectX 7, pplx Garden’s MoE cores deliver state-of-the-art decoding latencies and outperform DeepEP on the same hardware, while on EFA they deliver the first practical MoE latencies for trillion-parameter workloads.
- Because TransferEngine is open sourced under the MIT license in the pplx garden, teams can run very large expert mixes and dense models on heterogeneous H100 or H200 clusters across cloud providers without having to rewrite the network stack specific to each vendor.
Perplexity’s release of TransferEngine and pplx Garden is a real contribution for LLM infrastructure teams hampered by vendor-specific network stacks and expensive fabric upgrades. The portable RDMA abstraction reaches peak speeds of 400 Gbps on both NVIDIA ConnectX 7 and AWS EFA, supports KvCache streaming, fast reinforcement learning weight transfers, and expert hybrid routing to directly address the trillion-parameter service constraints of real systems.
Check Paper and repurchase agreements. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


