OpenAI researchers train weight sparsity transformer to expose explainable circuits
If neural networks are now making decisions everywhere from code editors to security systems, how can we actually see the specific circuits inside that drive each behavior? OpenAI has launched a new study on mechanical interpretability that trains language models to use sparse internal wiring so that model behavior can be explained using small, explicit circuits.
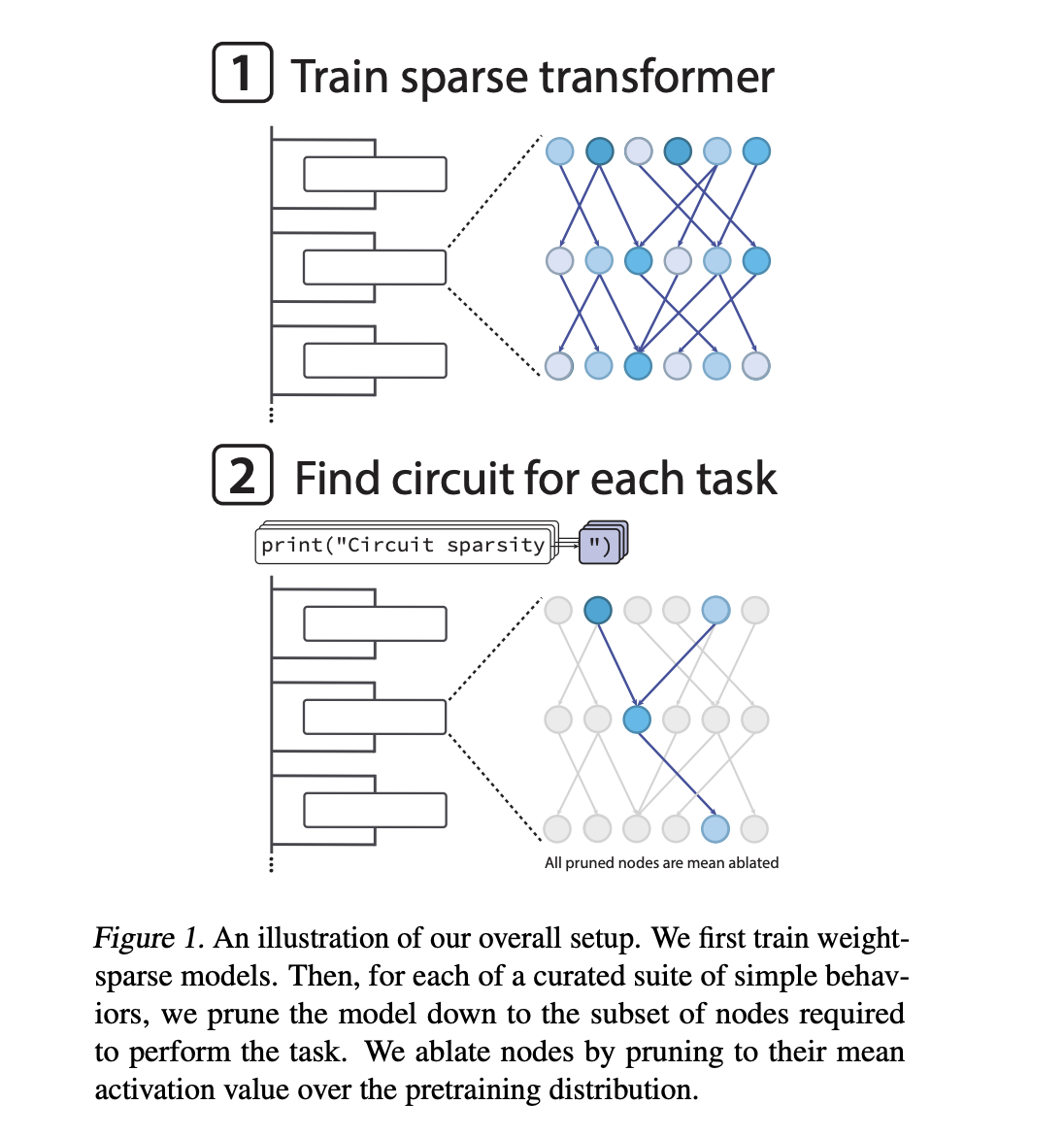
Train the Transformer to make its weights sparse
Most Transformer language models are dense. Each neuron reads and writes many remaining channels, and the features are often additive. This makes circuit-level analysis difficult. Previous OpenAI work attempted to use sparse autoencoders to learn sparse features based on dense models. New research work changes the basic model to make the transformers themselves sparsely weighted.
The OpenAI team trains decoder-only transformers using an architecture similar to GPT 2. After each optimizer step using the AdamW optimizer, they enforce a fixed sparsity level for each weight matrix and bias (including token embeddings). Only the largest magnitude entries in each matrix are kept. The rest are set to zero. During training, the annealing scheme gradually reduces the proportion of non-zero parameters until the model reaches the target sparsity.
In the most extreme case, about one in a thousand weights is non-zero. Activation is also a bit sparse. At a typical node location, about a quarter of the activation values are non-zero. Therefore, even if the model width is large, the effective connection graph is very thin. This helps to clearly map features onto the remaining channels used by the circuit.
Measuring interpretability through task-specific pruning
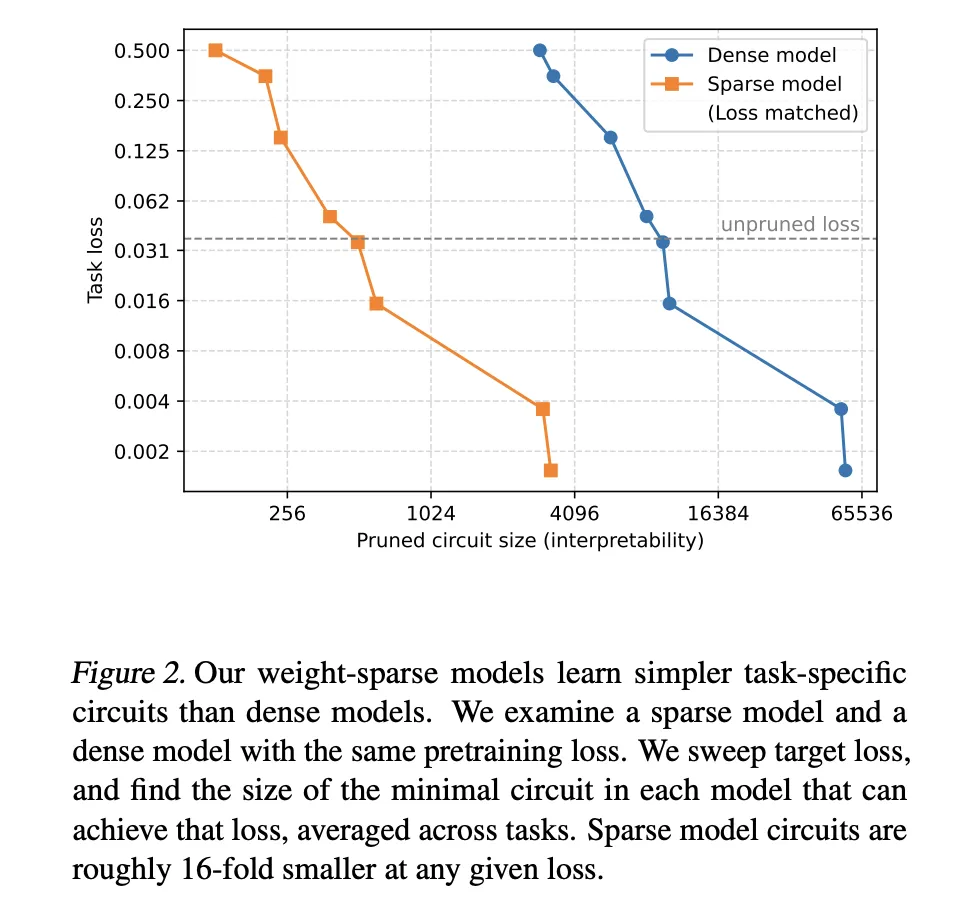
To quantify whether these models are easier to understand, the OpenAI team didn’t rely solely on qualitative examples. The research team defined a set of simple algorithm tasks based on Python next token prediction. An example single_double_quote requires the model to use the correct quote character to terminate a Python string. Another example, set_or_string, asks the model to choose between .add and += depending on whether the variable is initialized as a set or a string.
For each task, they searched for the smallest subnetwork (called a circuit) that could still perform the task up to a fixed loss threshold. Pruning is node-based. A node is a layer-specific MLP neuron, an attention head, or a layer-specific residual flow channel. When a node is pruned, its activation is replaced by its average over the pretrained distribution. This is the average ablation.
The search uses continuous mask parameters for each node and Heaviside-style gates, and is optimized using a through-estimator such as surrogate gradient. The complexity of a circuit is measured by the number of active edges between nodes that remain. The main interpretability metric is the geometric mean of edge counts across all tasks.
Example circuit in sparse transformer
In the single_double_quote task, the sparse model produces compact and fully interpretable circuits. In the early MLP layer, a neuron acts as a quote detector, activating on both single and double quotes. The second neuron acts as a quote type classifier that differentiates between the two quote types. The attention head then uses these signals to follow the opening quote position and copies its type to the closing position.
In circuit diagram terms, the mechanism uses 5 residual channels, 2 MLP neurons in layer 0, and 1 attention head in later layers, with a single relevant query key channel and a single value channel. If the rest of the model is ablated, this subgraph can still solve the task. If you delete these edges, the model will not be able to complete the task. Therefore, this circuit is both sufficient and necessary in the operational sense defined herein.

For more complex behavior, such as type tracing for a variable named current within a function body, the recovered circuit is larger and only partially understood. The research team showed an example where one attention operation writes the variable name into a tag set() at the point of definition, while another attention operation later copies the type information from that tag back into subsequent uses of current. This still results in a relatively small circuit diagram.
Main points
- Weight-sparse transformer design: OpenAI only trains GPT-2 style decoder transformers so that almost all weights are zero and about one in a thousand weights are non-zero, thus forcing sparsity in all weights and biases (including token embeddings), resulting in a thin connected graph that is structurally easier to analyze.
- Interpretability is measured as minimum circuit size: This work defines a benchmark for simple Python next labeling tasks and, for each task, searches for the smallest subnetwork in terms of active edges between nodes that still achieves a fixed loss using node-level pruning and mean ablation and pass-through estimator style mask optimization.
- Concrete, fully reverse-engineered circuits emerge: In a task such as predicting matching quote characters, the sparse model produces a compact circuit containing a few remaining channels, 2 critical MLP neurons, and 1 attention head, which the authors can fully reverse engineer and verify that this circuit is both sufficient and necessary for the behavior.
- Sparsity provides smaller circuits at a fixed capacity: At matching pretraining loss levels, weight-sparse models require approximately 16 times smaller circuits than those recovered from dense baselines, defining a capability interpretability bound where increasing sparsity improves interpretability while slightly reducing raw capability.
OpenAI’s work on weight sparse transformers is a pragmatic step toward achieving mechanical interpretability. By enforcing sparsity directly in the base model, this article transforms abstract discussions of circuits into concrete graphs with measurable edge counts, explicit necessity and sufficiency tests, and reproducible benchmarks for the Python next token task. These models are small and inefficient, but the approach is relevant to future security auditing and debugging workflows. This research treats interpretability as a first-class design constraint rather than a post hoc diagnostic.
Check Papers, GitHub repositories and technical details. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


