OpenAI releases “gpt-oss-safeguard” research preview: two open weight inference models for security classification tasks
OpenAI has released a research preview of gpt-oss-safeguard, two open-weighted secure inference models that allow developers to apply custom security policies at inference time. These models are available in two sizes, gpt-oss-safeguard-120b and gpt-oss-safeguard-20bboth fine-tuned from gpt-oss, both licensed under Apache 2.0, and both available on Hugging Face for local use.
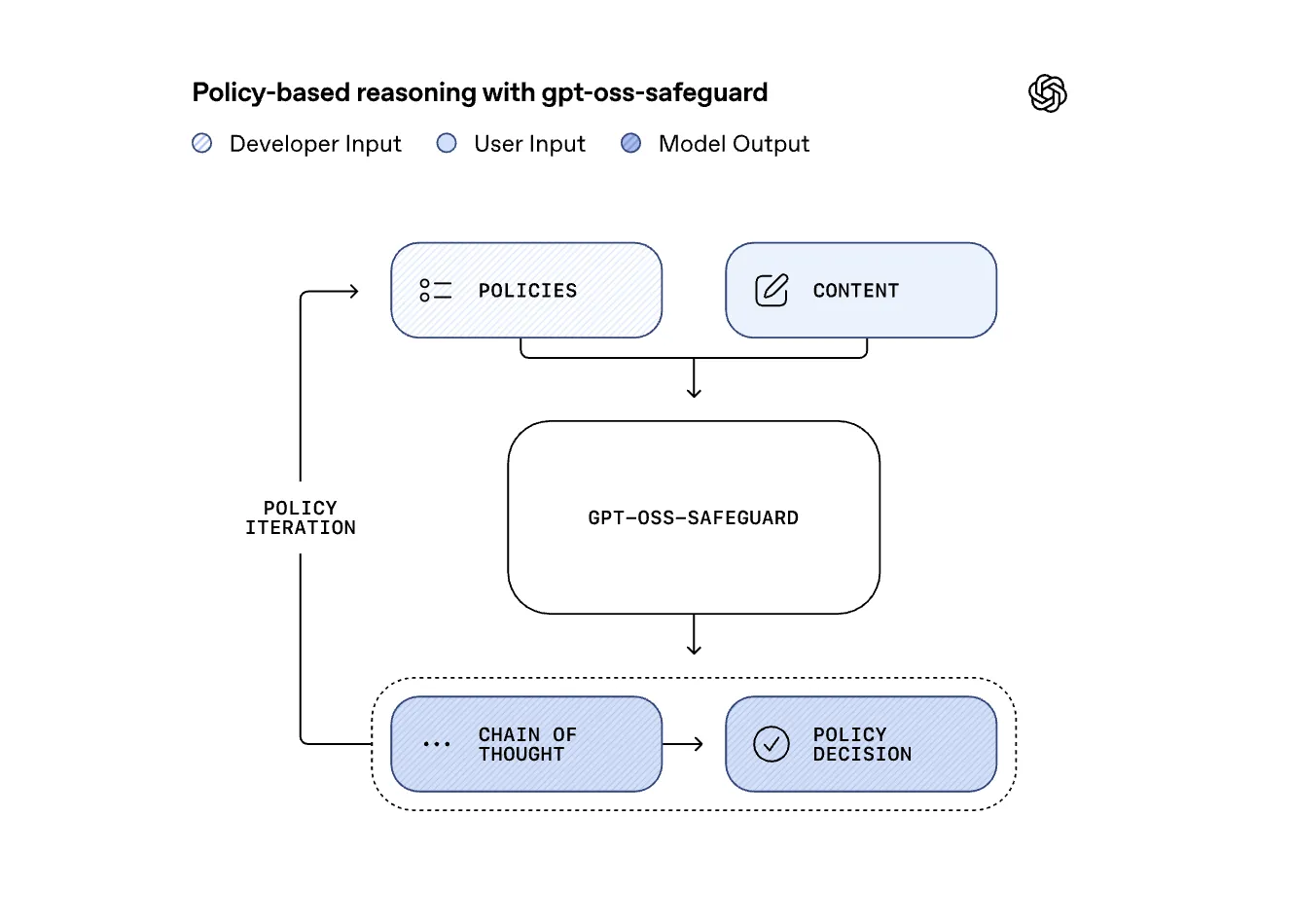
Why is policy mandated security important?
Traditional conditioning models are trained based on a single fixed policy. When this policy changes, the model must be retrained or replaced. gpt-oss-safeguard reverses this relationship. It takes a developer-written policy as input along with user content and then reasoning step-by-step to decide whether the content violates the policy. This turns security into a prompt and assessment task, better suited for rapidly changing or domain-specific harms such as fraud, creatures, self-harm, or game-specific abuse.
The same model as OpenAI’s internal secure inference engine
OpenAI stated that gpt-oss-safeguard is an open weight implementation of the secure inference engine and is used internally across systems such as GPT 5, ChatGPT Agent, and Sora 2. In production, OpenAI already runs small high-recall filters first and then upgrades uncertain or sensitive items to inference models, with up to 16% of total compute going to safe inference in recent releases. The open version enables external teams to reproduce this defense-in-depth model without guessing how the OpenAI stack works.
Model size and hardware adaptation
The large model gpt-oss-safeguard-120b has 117B parameters and 5.1B active parameters, and is sized to fit on a single 80GB H100-class GPU. The smaller gpt-oss-safeguard-20b has 21B parameters and 3.6B active parameters and targets lower latency or smaller GPUs, including 16GB settings. Both models were trained on a harmonic response format, so the cues had to follow that structure or the results would be degraded. The license is Apache 2.0, which is the same as the parent gpt-oss model, thus allowing commercial on-premises deployment.

Assessment results
OpenAI evaluated the model on internal multi-strategy tests and on public datasets. In terms of multi-policy accuracy, where the model must correctly apply multiple policies simultaneously, gpt-oss-safeguard and OpenAI’s internal safety reasoner outperformed gpt-5-thinking and the open gpt-oss baseline. On the 2022 review dataset, the new model slightly outperformed gpt-5-thinking and the in-house Safety Reasoner, but OpenAI noted that the gap was not statistically significant and should not be oversold. On ToxicChat, the internal Safety Reasoner still leads, followed closely by gpt-oss-safeguard. This puts the open model within competition for real audit tasks.
Recommended deployment modes
OpenAI makes it clear that pure inference on every request is expensive. The recommended setup is to run a small, fast, high-recall classifier on all traffic, then only send uncertain or sensitive content to gpt-oss-safeguard, and run the reasoner asynchronously when the user experience requires a fast response. This mirrors OpenAI’s own production guidelines and reflects the fact that dedicated task-specific classifiers can still win when large, high-quality labeled datasets exist.
Main points
- gpt-oss-safeguard is a research preview of two open-weight safe inference models, 120b and 20b, which use developer-provided policies to classify content at inference time, so policy changes do not require retraining.
- These models implement the same safe inferencer mode used by OpenAI inside GPT 5, ChatGPT Agent, and Sora 2, where a first fast filter only routes risky or ambiguous content to slower inference models.
- Both models are fine-tuned based on gpt-oss, maintaining the harmonious response format, and resized for real-world deployments, the 120b model is suitable for a single H100-class GPU, the 20b model is targeted at 16GB-class hardware, and both are Apache 2.0 on Hugging Face.
- On the internal multi-policy evaluation and 2022 audit datasets, the assurance model outperformed the gpt-5-thinking and gpt-oss baselines, but OpenAI noted that the small gap compared to the internal Safety Reasoner was not statistically significant.
- OpenAI recommends using these models in a hierarchical review pipeline, combined with community resources such as ROOST, so that the platform can express custom taxonomies, review thought chains, and update policies without touching weights.
OpenAI is taking an internal security model and making it replicable, which is the most important part of this release. The models are open weight, policy conditional and Apache 2.0 so the platform can eventually apply its own taxonomies rather than accepting fixed labels. The fact that gpt-oss-safeguard matched and sometimes slightly outperformed the in-house safety reasoner on the 2022 audit dataset while outperforming gpt-5-thinking in multi-policy accuracy by a non-statistically significant margin suggests that this approach is already available. The recommended tiered deployment is realistic for production.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


