OpenAI launches IndQA: a cultural awareness benchmark for Indian languages
How do we reliably test whether large language models truly understand real-world Indian languages and culture? OpenAI has been released industrial quality assurance, The benchmark evaluates an AI model’s ability to understand and reason about important issues in Indian languages across cultural domains.
Why choose IndQA?
OpenAI points out that about 80% of the world’s people do not speak English as their primary language. However, most benchmarks for measuring non-English proficiency remain narrow and often rely on translation or multiple-choice formats.
Benchmarks such as MMMLU and MGSM are now approaching saturation at the high end, with powerful models clustering around similar scores. This makes it difficult to see meaningful progress and test whether models understand local context, history and daily life.
India is the starting point for OpenAI’s new regional benchmarks. There are about 1 billion people in India who do not use English as their main language. There are 22 official languages, at least 7 of which are spoken by more than 50 million people. It is ChatGPT’s second largest market.
Datasets, languages and domains
IndQA assesses knowledge and reasoning in Indian languages about Indian culture and daily life. The benchmark covers 2,278 questions in 12 languages and 10 cultural domains and was created by 261 domain experts from across India.
Cultural areas include Architecture and Design, Art and Culture, Daily Life, Food and Cooking, History, Law and Ethics, Literature and Linguistics, Media and Entertainment, Religion and Spirituality, and Sports and Entertainment. Items are written in Bengali, English, Hindi, Hinglish, Kannada, Marathi, Odiya, Telugu, Gujarati, Malayalam, Punjabi and Tamil. Hinglish is included to reflect code-switching common in Indian conversations.
Each data point has four components: culture-based prompts in Indian languages, English translations for reviewability, scoring rubrics, and ideal answers expected by coding experts.
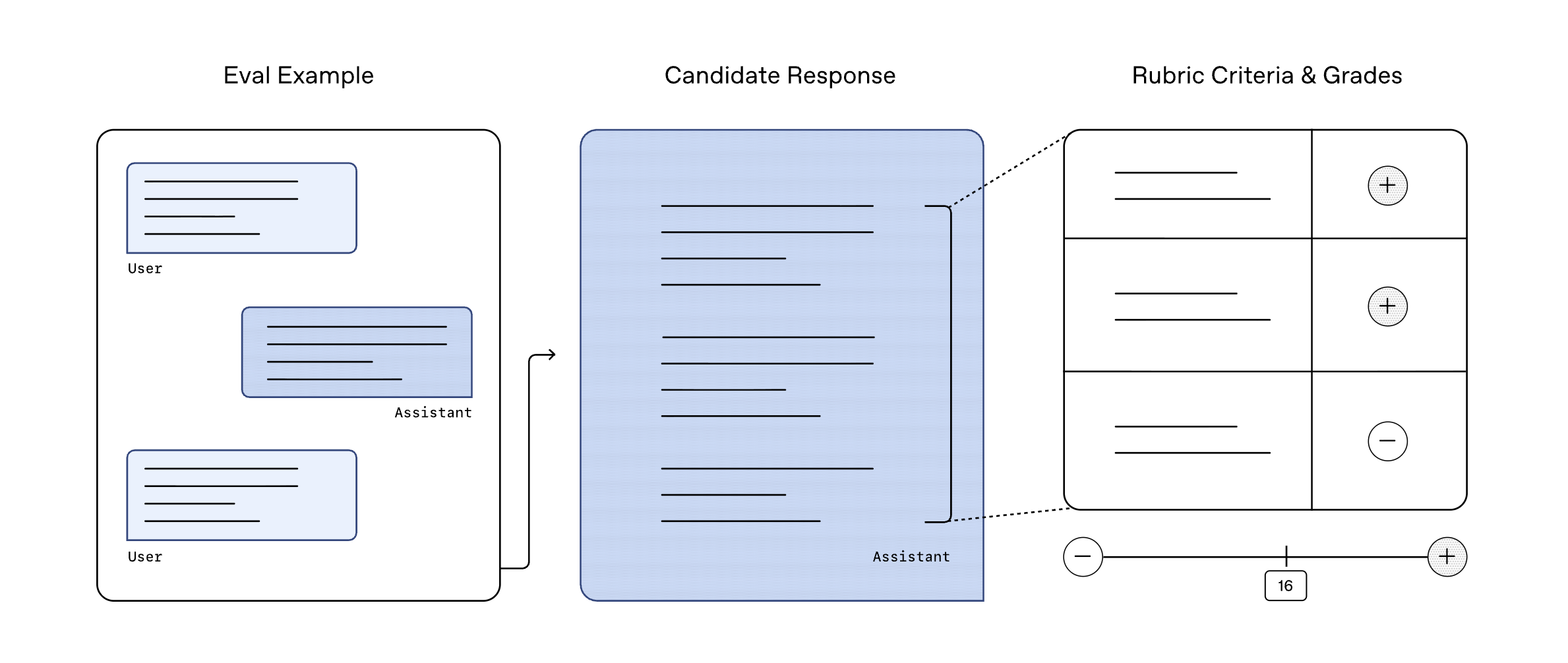
Rubric-based assessment process
IndQA uses a scoring procedure based on rubrics rather than exact match accuracy. For each question, domain experts define multiple criteria, describe what a strong answer should include or avoid, and assign a weight to each criterion.
Model-based raters check candidate responses against these criteria and mark which ones are satisfactory. The final score is the sum of the weights that satisfy the criteria divided by the total possible score. This is like grading short exam answers, which supports partial credit and captures nuance and cultural correctness rather than just surface mark overlap.
Construction process and adversarial filtering
OpenAI describes a four-step build process:
First, they partnered with organizations in India to recruit experts in 10 fields. These experts are native speakers of the target language and English and possess deep subject expertise. They write difficult, reasoned prompts based on regional contexts such as literature, food history, law, or media.
Second, they applied adversarial filtering. Each draft question is evaluated using OpenAI’s most powerful models (GPT-4o, OpenAI o3, GPT-4.5) at the time of creation and (sometimes after public release) GPT-5. Only questions for which a majority of models failed to produce an acceptable answer were retained. This leaves room so that future model improvements can be clearly shown on IndQA.
Third, experts provide detailed scoring rubrics for each question, similar to exam rubrics. These criteria are reused every time another model is evaluated on IndQA.
Fourth, experts write ideal answers and English translations, which are then peer-reviewed and iteratively revised until they sign a quality agreement.
Measuring the progress of Indian languages
OpenAI uses IndQA to evaluate the latest cutting-edge models and map the progress of Indian languages over the past few years. They report that model performance improved significantly on IndQA, but there is still considerable room for improvement. Results are stratified by language and domain, and include comparisons of GPT-5 Thinking High with other cutting-edge systems.
Main points
- IndQA is a culture-based benchmark for India: IndQA assesses an AI model’s ability to understand and reason about important questions in Indian languages across culturally specific domains, rather than just testing translation or multiple-choice accuracy.
- The dataset was built by experts and is quite large: The benchmark consists of 2,278 questions in 12 languages and 10 cultural domains and was developed in collaboration with 261 domain experts from across India, covering areas such as architecture, daily life, food, history and religion.
- Evaluation is based on scoring criteria and is not an exact match: Each data point is bundled with native language prompts, English translations, detailed scoring criteria, and ideal answers, and model output is scored by a model-based system that checks weighted expert-defined criteria, allowing for partial credit and nuanced cultural assessment.
- Adversarial filtering of questions against OpenAI’s most powerful models: Filter draft issues by running GPT 4o, OpenAI o3, GPT 4.5, and partially GPT 5 and keep only projects with a majority of model failures, which leaves room for future models on IndQA.
IndQA is a timely step as it targets the real gap where most existing multilingual benchmarks exceed indexing for English content and translation style tasks, while India has multiple high- and low-resource languages. IndQA provides expert-curated, title-based assessments on issues that matter in the Indian cultural context and uses adversarial filtering for GPT 4o, OpenAI o3, GPT 4.5 and GPT 5 to reserve space for cutting-edge models. This launch makes IndQA a practical north star for evaluating Indian language reasoning in modern AI systems.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


