NVIDIA AI unleashes diffusion renderer: an AI model for editable, realistic 3D scenes
AI-powered video generation is improving at an astonishing speed. In a short time, we went from vague, incoherent clips to videos with amazing realism. However, despite all these progress, the critical capabilities are lacking: Control and editing
While it is one thing to generate beautiful videos, it has the ability to be professional and realistic edit It – to change lighting from daytime to night, to swap the material of objects from wood to metal, or to insert new elements seamlessly into the scene – is still a powerful, largely unsolvable problem. This gap has been a key obstacle to preventing AI from becoming a real fundamental tool for filmmakers, designers and creators.
Until introduction diffusion renderer!!
In a groundbreaking new paper, researchers at NVIDIA, the University of Toronto, the School of Media and the University of Illinois Urbana-Champaign have released a framework to directly address this challenge. The diffuser represents a revolutionary leap beyond the development of mere power generation, providing a unified solution to understand and manipulate 3D scenes in a single video. It effectively bridges the gap between generation and editing, thus unlocking the true creativity of AI-driven content.
Old ways and new ways: paradigm shift
For decades, the light truth has been anchored in PBR, a method of carefully simulating optical flow. While producing amazing results, it is a fragile system. PBR relies heavily on the perfect digital blueprint of the scene – exquisite 3D geometry, detailed material textures and accurate lighting diagrams. The process of capturing this blueprint from the real world is called Reverse renderingas we all know, is difficult and prone to errors. Even in this data, even small flaws can lead to catastrophic failures in the final rendering, a critical bottleneck, and the use of PBR outside of a controlled studio environment limits the use of PBR.
Previous neural rendering techniques (such as Nerfs), while revolutionizing the creation of static views, hit the wall in terms of editing. They “bake” the lighting and materials to the site, making post-capture modifications nearly impossible.
diffusion renderer In a unified unified framework, treating “what” (the property of the scene) and “how” (the rendering) is based on the same powerful video diffusion architecture, which is the basis for models such as stable video diffusion.
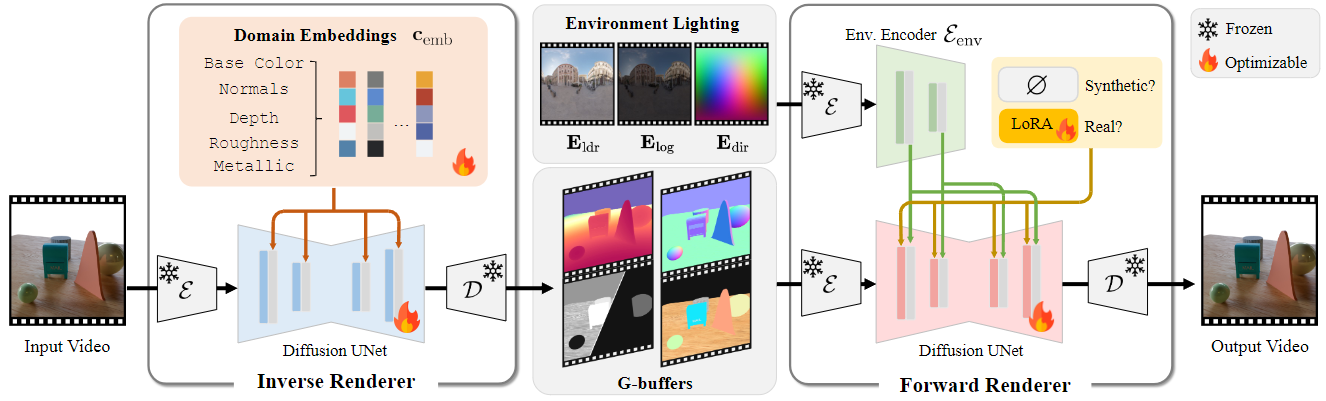
This method uses two neural renderers to process videos:
- Neural Reverse Renderer: The model is like a scene detective. It analyzes the input RGB video and intelligently estimates the intrinsic properties, generating a basic data buffer (G-buffer) describing the scene’s geometry (normal, depth) and pixel-level materials (color, roughness, metal). Each attribute is generated in a dedicated pass to achieve a high-quality generation.
- Neural forward renderer: The model acts as an artist. It requires G-buffers from the reverse renderer, combining them with any desired lighting (environmental map), and synthesizes realistic videos. Crucially, it is already trained to be reliable and capable of producing amazing, complex light transmission effects such as soft shadows and reflections, even if the input G-buffer from the inverse renderer is imperfect or “noisy”.
This synergy of self-correction is at the heart of the breakthrough. The system is designed for the chaos of the real world, where perfect data is a myth.
Secret Seasoning Sauce: A New Data Strategy to Blink Reality Gap
Without smart data, smart models have nothing. The researchers behind the diffusers designed a clever two-pronged data strategy to teach their models the perfect physics and imperfect reality.
- A huge synthetic universe: First, they built a huge, high-quality synthetic dataset of 150,000 videos. Using thousands of 3D objects, PBR materials, and HDR lighting maps, they create complex scenes and render them with a perfect path tracking engine. This provides a perfect “textbook” for inverse rendering models to learn from and provide them with perfect basic data.
- Automatically mark the real world: The team found that alternative renderers that only accept synthetic data were good at promoting to real videos. They freed it in a massive dataset of 10,510 real-world videos (DL3DV10K). The model automatically generates the G-Buffer tag for this real-world video. This creates a huge, 150,000 samples of real-life scene dataset with corresponding (although imperfect) Intrinsic attribute graphs.
By co-training forward renderers perfectly synthesized data and automatically labeled real-world data, the model learns to bridge critical “domain gaps”. It learns the rules from the appearance and feeling of the integrated world and the real world. To handle the inevitable inaccuracy in automatically labeled data, the team incorporated the Lola (low-level adaptation) module, a clever technique that allows the model to adapt to noisy real data without compromising the knowledge gained in the original synthesis set.
The most advanced performance
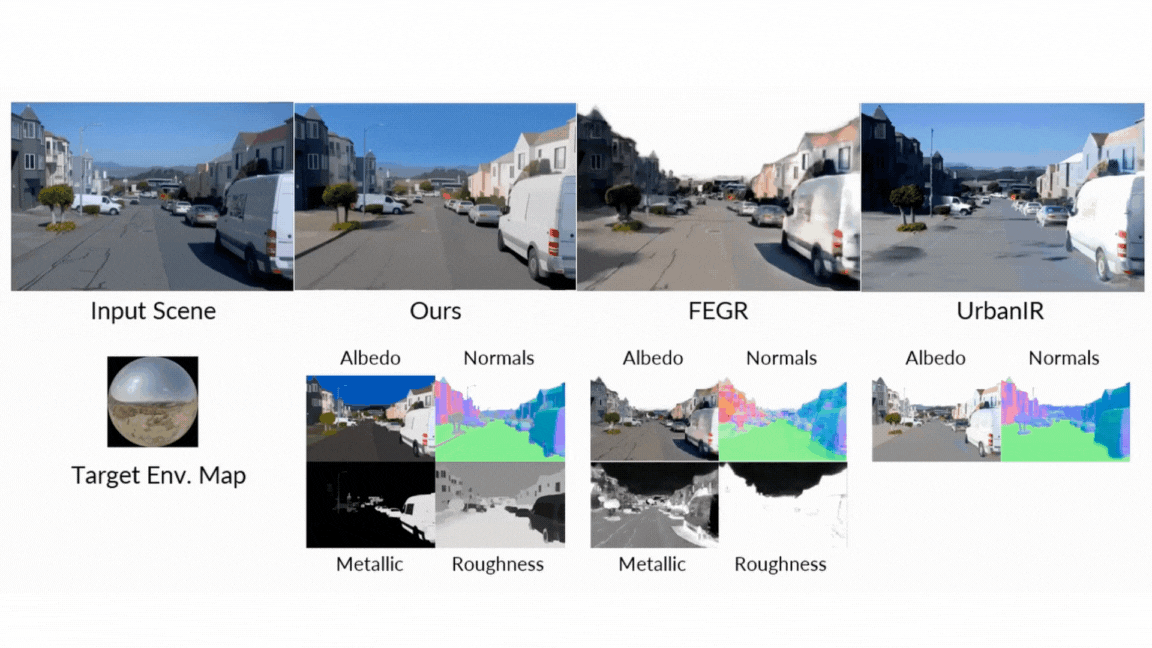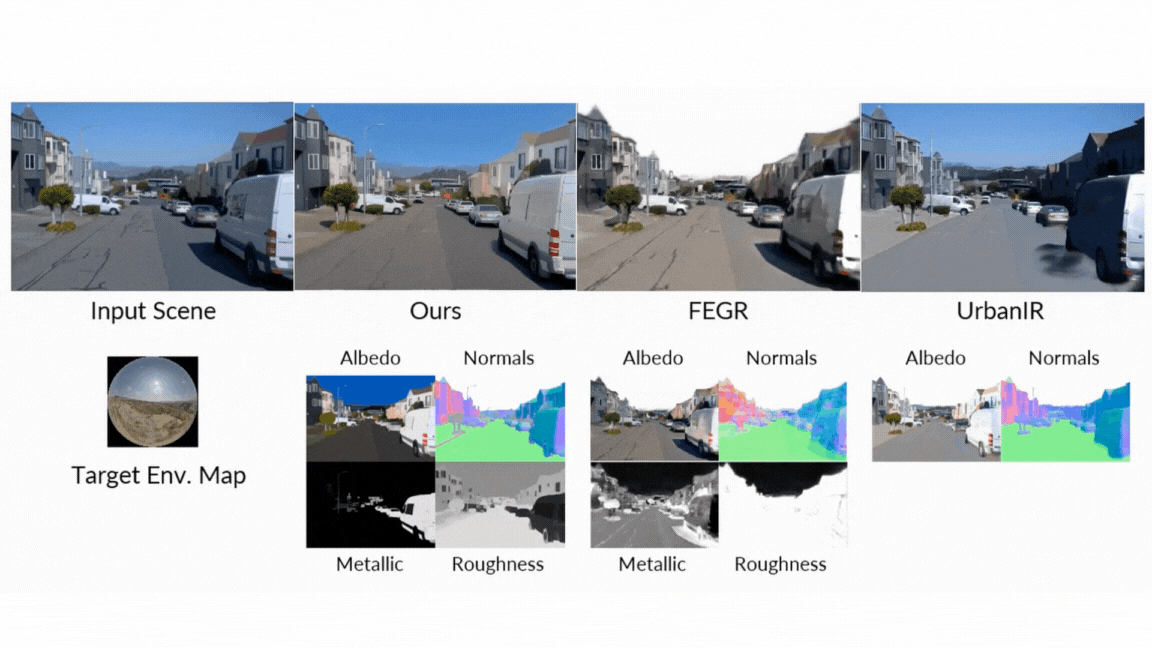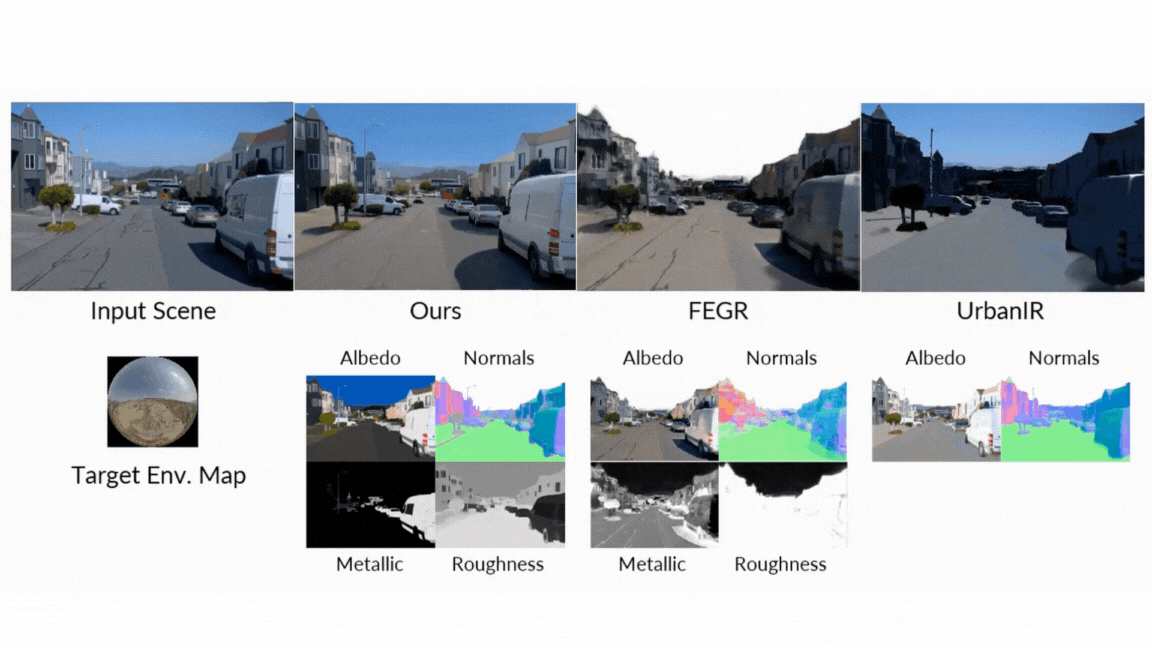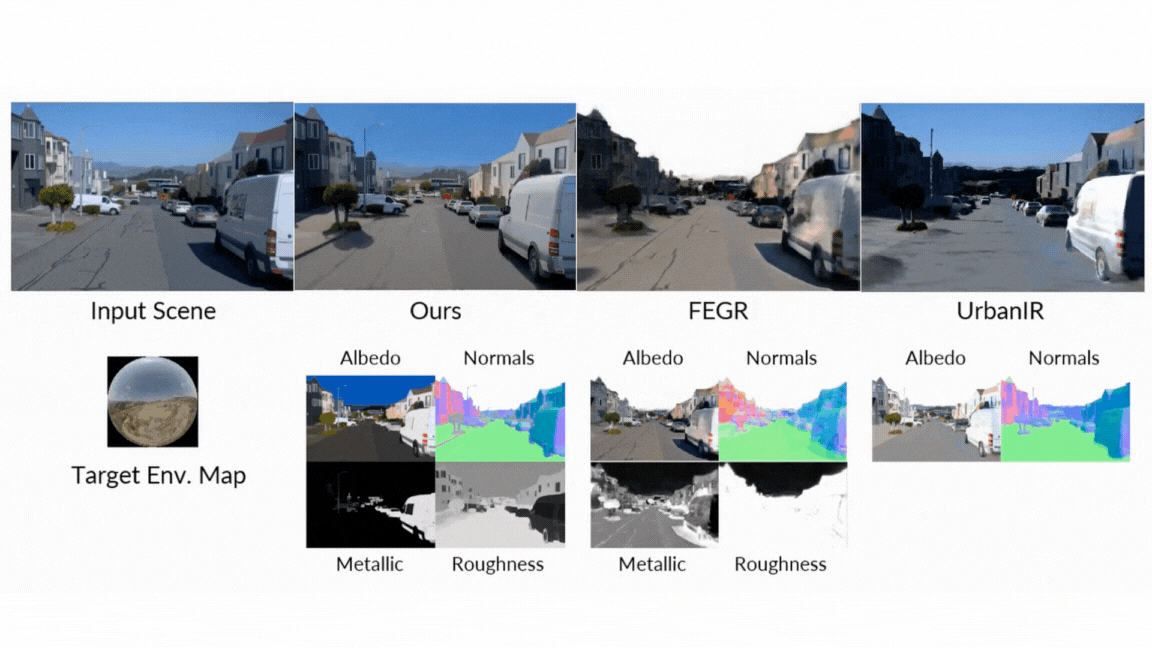
As a result, he talked to himself. In a rigorous face-to-face comparison with classical and neuro-standard approaches, the diffuser always appears in all assessed tasks:
- Render forward: When generating images from G-buffers and Lighting, diffusion Renderer significantly outperforms other neural methods, especially in complex multi-object scenes where real reflections and shadows are critical. Neural rendering performs significantly better than other methods.


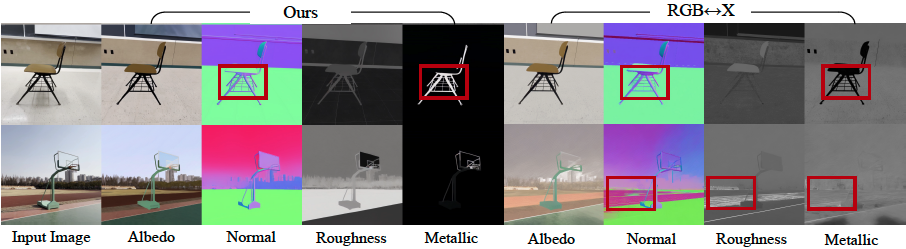
- Reverse rendering: This model proves superior in estimating the inherent characteristics of the scene in video, achieving higher accuracy in albedo, material and normal estimation than all baselines. The use of display video models (versus single image models) is particularly effective, and since it utilizes motion to better understand view-dependent effects, it reduces errors in metal and roughness predictions by 41% and 20%, respectively.


- Reconsider: In the final test of the unified pipeline, diffusion renderer produces superior quantitative and qualitative redetermination results compared to dilution networks and neural gaffers such as diluents and neural gaffers, resulting in more accurate specular reflections and high-efficiency lighting.

You can use dixFusionRender: Powerful editing!
This study unlocks a practical, powerful set of editing applications run by single, everyday videos. The workflow is simple: the model first performs inverse rendering to understand the scene, the user edits the properties, and the model then performs forward rendering to create a new photorealistic video.
- Dynamic reconsideration: Change the time of day, swap the studio lights for sunsets, or completely change the mood of the scene by simply providing a new environmental map. The framework actually re-renders the video with all the corresponding shadows and reflections.
- Intuitive material editing: Want to see what that leather chair will look like in chrome? Or make the metal statue look like it is made of rough stone? Users can adjust the material buffers directly (adjust roughness, metal properties, and color properties) and the model will present changes to photoreistisiss.
- Seamless object insertion: Put new virtual objects into the real world. By adding properties of a new object to the scene’s G-buffers, the forward renderer can synthesize the final video, where the object is naturally integrated, discarding realistic shadows and picking up accurate reflections from its surroundings.


New foundations of graphics
The diffusion renderer represents a clear breakthrough. By solving the reverse and forward rendering overall within a robust, data-driven framework, it tear off long-term obstacles to traditional PBR. It makes light realistic renderings transform it from the exclusive realm of VFX experts with powerful hardware to a more accessible tool for creators, designers and AR/VR developers.
In a recent update, the authors further improved video delighting and re-illumination by leveraging Nvidia Cosmos and enhanced data curation.
This shows a promising expansion trend: as the basic video diffusion model grows stronger, the output quality will improve, resulting in sharper results.
These improvements make the technology more attractive.
New models are released by Apache 2.0 and Nvidia Open Model license, IS Available here
Source:
Thanks to the NVIDIA team for their thought leadership/resources in this article. The NVIDIA team supports and sponsors this content/article.

Jean-Marc is a successful AI business executive. He led and accelerated the growth of AI Power’s solutions and founded a computer vision company in 2006. He is a recognized spokesperson for the AI conference and holds an MBA from Stanford University.


