NVIDIA AI releases new jet hybrid: faster 53x hybrid architecture language model series, which reduces the size of 98% cost reduction
NVIDIA researchers break down long-term efficiency barriers to large language model (LLM) inference Jet new hybrid– Model families provided (2b and 4b) Up to 53.6× higher generation throughput More attention than leader when matching even exceeds its accuracy. Most importantly, this breakthrough is not the result of new pre-training from scratch, but Retrofit of existing pre-trained models Using a novel technique is called Postner architecture search (Postnas). The impact on businesses, practitioners and researchers is transformative.
Speed requirements in modern LLM
While today’s state-of-the-art (SOTA) LLMs, such as Qwen3, Llama3.2 and Gemma3, set new benchmarks for accuracy and flexibility, they o(n²) Self-attention Mechanisms can incur high costs – compute and in memory – especially for novel tasks. This makes them expensive to deploy at scale, making it nearly impossible to run on edge or memory-constrained devices. So far, efforts to replace full attention transformers with more efficient architectures (MAMBA2, GLA, RWKV, etc.) have been working to close the accuracy gap.
Postnas: Surgery, capital efficiency overhaul
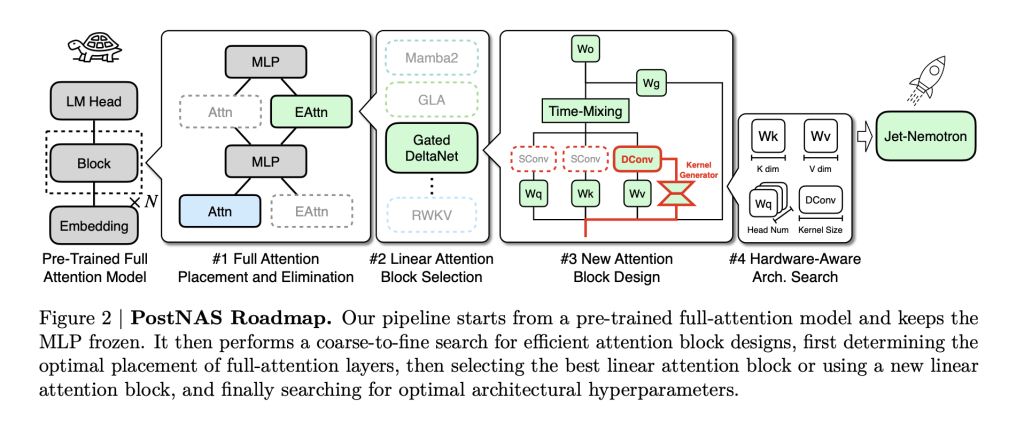
The core innovation is Postnas: A specially designed neural building search pipeline Effectively transform pre-trained models. Here is how it works:
- Freeze knowledge: Start with the SOTA full attention model (e.g. QWEN2.5). Freeze it MLP layer– This preserves the intellectual intelligence of the model and greatly reduces the training costs.
- Surgical replacement:use pierThis is a new hardware-effective linear attention block designed for NVIDIA’s latest GPUs.
- Hybrid, hardware-aware design: use Super Network Training and Beam Search Automatically confirm Best location and smallest full attention layer set Maintaining the accuracy of critical tasks (retrieval, math, MMLU, coding, etc.) is necessary. This step is Task-specific and Hardware understanding: Search maximizes the throughput of the target hardware, not just parameter counts.
- Proportion and deployment:turn out Hybrid architecture LLM inherits the backbone intelligence of the original model, but cuts down on latency and memory footprints.
pier Especially noteworthy: It introduces Dynamic causal convolution kernel Conditional on input (unlike the static kernel in previous linear attention blocks) and eliminates redundant convolution for increased streamline efficiency. Through hardware-aware hyperparameter search, it not only maintains throughput with previous linear attention designs, but it actually is Improve accuracy.
Jet New Hybrid: Performance by Numbers
The key indicators of NVIDIA technical papers are amazing:
| Model | MMLU-PRO ACC. | Generate throughput (token/s, h100) | KV cache size (MB, 64K context) | notes |
|---|---|---|---|---|
| qwen3-1.7b Basics | 37.8 | 61 | 7,168 | Pay attention to baseline |
| JET-NEMOTRON-2B | 39.0 | 2,885 | 154 | 47× throughput, 47× smaller cache |
| JET-NEMOTRON-4B | 44.2 | 1,271 | 258 | 21× throughput, still sota acc. |
| MAMBA2-2.7B | 8.6 | 2,507 | 80 | Fully linear, much lower accuracy |
| RWKV7-1.5B | 13.4 | 3,050 | twenty four | Fully linear, much lower accuracy |
| DeepSeek-V3-small (MOE) | – | – | – | 2.2b activation, total 15B, lower ACC. |
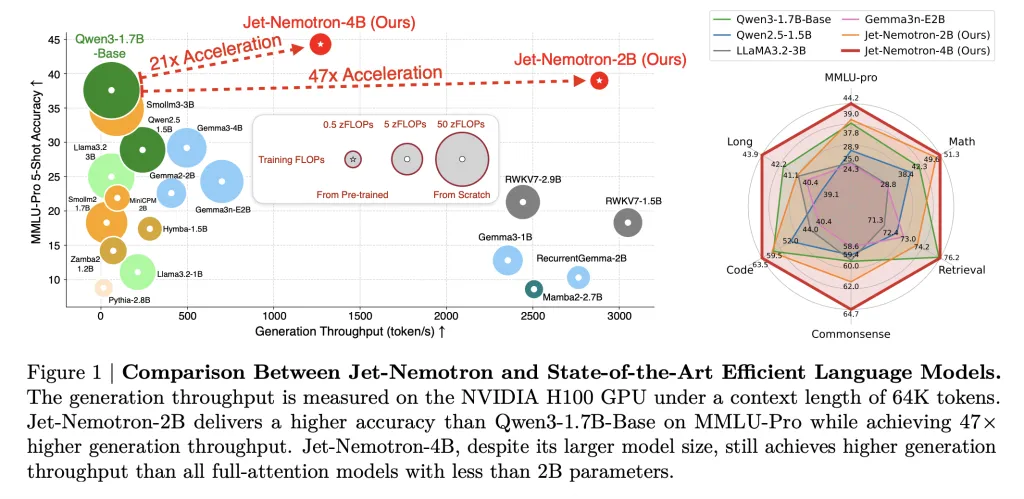
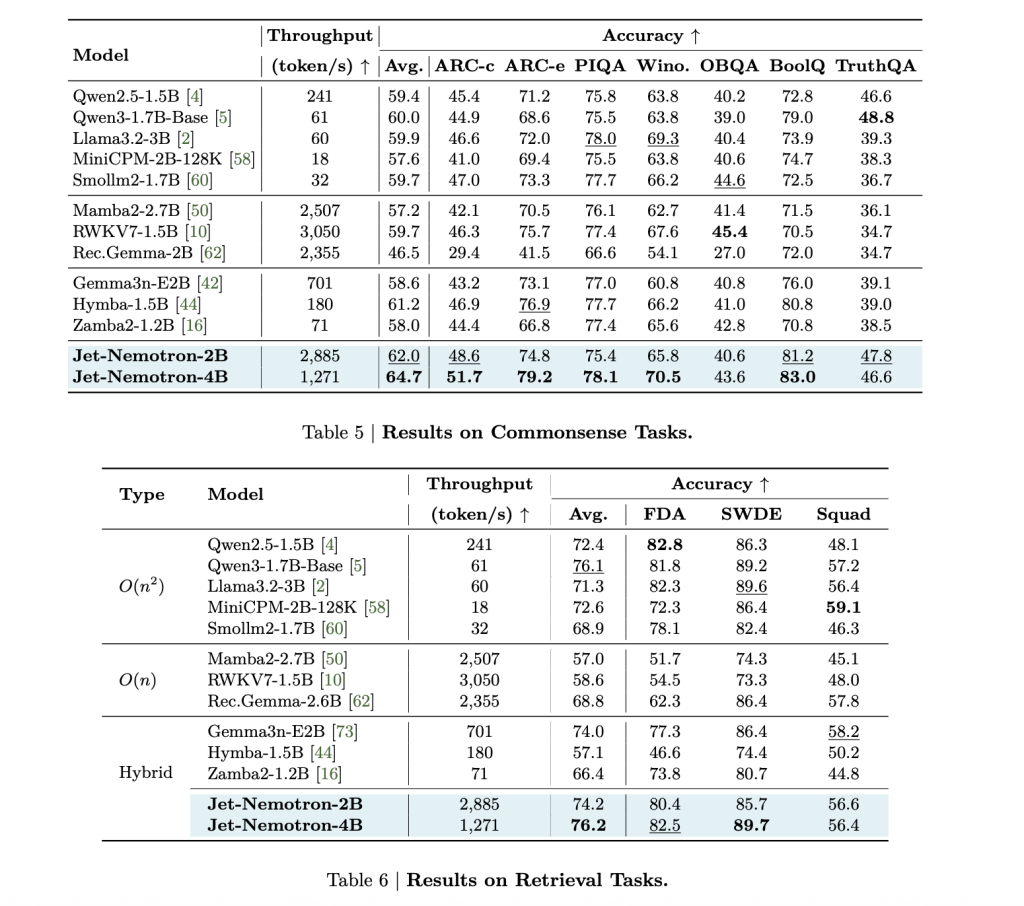
JET-Nemotron-2b matches or exceeds each major benchmark (MATH, COMINSENSESSENS, encoding, retrieval, lowercase) of the QWEN3-1.7B benchmark, while delivering 47 times higher generation throughput.
This is not a small profit: 53.6× acceleration decoded on 256K context length Meaning Reduce the cost of reasoning by 98% For the same token. The pre-filling speed is also eye-catching: 6.14× Faster in 256K context.
Memory footprint shrinks by 47 times (QWEN3-1.7B cardinality is 154MB cache vs. 7,168MB). This is a Game Changeers who change the edge deployment: Jet-Nemotron-2b is 8.84× and 6.5× On Jetson Orin and RTX 3090, the Qwen2.5-1.5b is fast.
Apply
For business leaders: better ROI $$
- Scale inference is now affordable. 53× Throughput Gain Mean USD vs. USD, you can provide services to 53× more users-or Cut 98% of hosting costs.
- Operational efficiency change: The incubation period decreases, batch size increases, and memory constraints disappear. Cloud providers can SOTA AI is available at commodity prices.
- Reshaping AI business model: Once expensive tasks (real-time document AI, novel agents, mentally retarded co-pilots) suddenly became feasible.
For practitioners: Sota is on the edge
- Forget quantification, distillation or pruning compromise. Jet new nemotron’s tiny KV cache (154MB) and 2B parameters Suitable for Jetson Orin, RTX 3090, and even mobile chips– No more offloaded to the cloud.
- No retraining, no data pipeline changes: Just renovated. Your existing QWEN, LLAMA or GEMMA checkpoint can be upgraded No loss of accuracy.
- AI services in the real world (Search, Side Effects, Summary, Encoding) Now Instant scalable.
For researchers: lower barriers, higher innovation
- Postnas cuts the cost of LLM Architecture Innovation. Instead of months and millions of pre-training, Architectural search takes place on frozen backbone models A small part.
- Hardware realizes that NAS is the future: JET-Nemotron Process Consideration KV cache size (not only parameters) as a key factor in real-life speed. This is a Paradigm transfer In terms of how we measure and optimize efficiency.
- The community can iterate faster: PostNAS is a quick test. If there is a new dysconsistency here, it is worth pre-training. If not, it will filter before the big spending.
Summary
Open source Jet new hybrid and pier (Code on GITHUB) means that a wider AI ecosystem can now revamp its models to improve efficiency than ever before. Postnas Not a one-time trick: This is a universal framework To accelerate any transformer, the cost of future breakthroughs is reduced.
Check Paper and Github page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


