NVIDIA AI proposes thinking: visual language action reasoning through enhanced visual potential plans
Estimated reading time: 5 minute
introduce
Embodied AI agents are increasingly required to interpret complex multi-modal instructions and act firmly in dynamic environments. ThinkactProposed by researchers from NVIDIA and Taiwan University, Visual Language Action (VLA) Reasoningintroduce reinforcement Vision potential plan Bridge advanced multi-mode reasoning and low-level robot control.
A typical VLA model maps raw visual and linguistic input directly to the action through end-to-end training, which limits reasoning, long-term planning, and adaptability. Recent methods have begun to be incorporated into the middle Business Chain (COT) When encountering highly variable and long robot manipulation tasks, reasoning or trying RL-based optimizations, but struggling with scalability, grounding, or generalization.
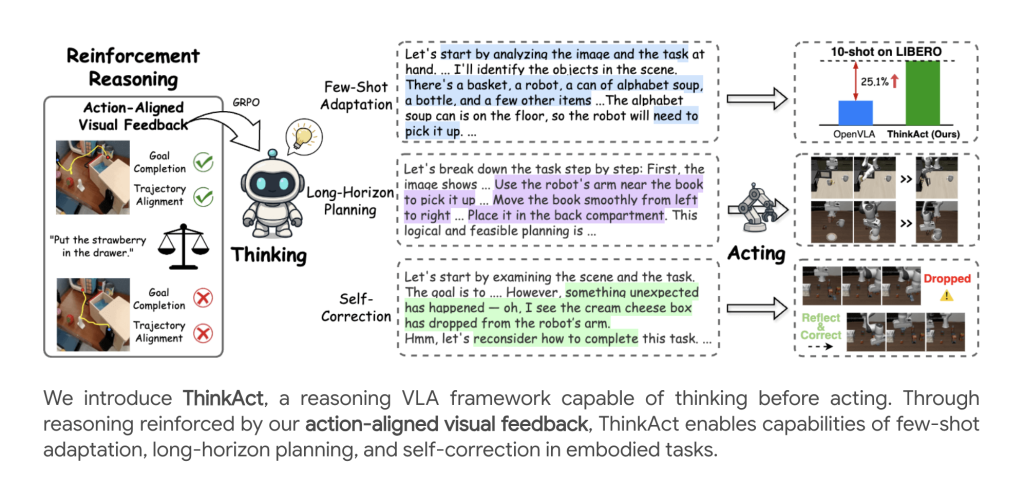
Thinkact framework
Dual system architecture
Thinkact consists of two tightly integrated components:
- Inference Multi-Mode LLM (MLLM): Perform structured, step-by-step reasoning, output on visual scenes and language descriptions Vision planning potential This codes for advanced intent and planning background.
- Action Model: Transformer-based strategy is based on visual planning, and the decoded trajectory is executed as the operation of the robot in the environment.
This design allows Asynchronous operation: LLM “thinks” and generates plans at a slow pace, while the action module is fine-grained at a higher frequency.
Enhanced vision potential program
The core innovation is Hardening Learning (RL) Methods use Visual rewards for consistent action:
- Target Rewards: The model is encouraged to align the projected start and end points in the plan with the start and final positions in the demonstration trajectory, thus supporting target completion.
- Track Reward: Normalize the predicted visual trajectory to closely match the distributed performance demonstrated by experts using dynamic time warping (DTW) distances.
Total Rewards RRR integrates these visual rewards with the correctness score of the format, pushing LLM toward not only producing accurate answers, but also planning to translate into physically reasonable robotic actions.
Training pipeline
Multi-stage training procedures include:
- Supervised fine-tuning (SFT): Cold-start visual trajectory and QA data for manual logout to teach trajectory prediction, reasoning and answer formats.
- Strengthen fine-tuning: RL optimization (using group relative strategy optimization, GRPO) further inspires high-quality reasoning by maximizing the rewards consistent with newly defined actions.
- Movement adaptation: Downstream action strategies were trained using imitation learning, using the potential plan output of frozen LLM to guide controls across various environments.
reasoning
When reasoning, given the observed scenario and language instructions, the inference module generates a visual plan, and then adjusts the operation module to execute the full trajectory, which can perform robust performance on the constant trajectory even in new, previously invisible settings.

Experimental results
Robot manipulation benchmark
experiment Simple and Libero Benchmarks show the advantages of Thinkact:
- SimplerEnv: Performance over powerful baselines (e.g. OpenVLA, DIT-Policy, TraceVla) in various environments, especially outstanding in long-distance and visually diverse tasks.
- free: The highest overall success rate (84.4%) was achieved, and outstanding in space, objects, goals and long-term challenges, thus confirming their ability to generalize and adapt to novel skills and layouts.

Reflected reasoning benchmarks
exist egoplan benchmark2,,,,, Robovqaand OpeneqaThinkact proof:
- Excellent multi-step and accuracy of long horse planning.
- The state-of-the-art BLEU and LLM-based quality inspection scores reflect the semantic understanding and fundamental improvements to the visual question answering task.
Almost no adaptations
Thinkact can be effective Almost no adaptations: With just 10 demos, it can achieve a lot of success rates improves other methods, highlighting the power of reasoning guidance programs to quickly learn new skills or environments.
Self-reflection and correction
Beyond the mission success, Thinkact exhibition Emergency behavior:
- Failed detection: Identify execution errors (for example, deleting objects).
- Re-master: Thanks to the reasoning of recent visual input sequences, the plan for restoring and completing tasks is automatically modified.
Ablation studies and model analysis
- Reward melting: Both Target and trajectory Rewards are essential for structured planning and generalization. Deletion either significantly reduces performance and rely solely on QA-style rewards limit multi-step reasoning capabilities.
- Reduce update frequency: ThinkAct strikes a balance between reasoning (slow, planning) and action (fast, control), allowing robust performance without excessive computational requirements1.
- Smaller models: The method is summarized as a smaller MLLM skeleton to maintain strong reasoning and mobility capabilities.
Implementation details
- Main backbone: QWEN2.5-VL 7B mllm.
- Datasets: diverse robot and human demonstration videos (Open X-Embodiment, Somethings v2), and multimodal QA suite (Robovqa, Egoplan-Bench, Video-R1-Cot, etc.).
- Connect the inference output to the action policy input using the visual encoder (Dinov2), text encoder (clip), and Q forms.
- Extensive experiments on real and simulated settings prove scalability and robustness.
in conclusion
Nvidia’s Thinkact is Embodied AI agentprove this Enhanced vision potential program– Where the agent “think before action” – gives powerful, scalable and adaptable performance in complex, real-world reasoning and robot manipulation tasks. Its dual-layer system design, reward molding and strong experience results pave the way for general-purpose robots that can plan for long-term, with little adaptability and self-correction in different environments.
Check Paper and project. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
You may also like NVIDIA’s open source cosmic diffuser [Check it now]
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.



