NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI
How do you create 3D datasets to train AI’s robotics without expensive traditional methods? A team of researchers from NVIDIA released theSpeed: 3D geometric perception video pose engine“Bring key improvements Space AI. It addresses the central pain bottleneck that has limited the 3D computer vision field for years.
VIPE It is a powerful, versatile engine designed to handle original, unrestricted “out-of-field” video recordings and automatically output key elements of 3D reality:
- Inside the camera (Sensor calibration parameters)
- Accurate camera movement (posture)
- Dense, measure depth map (Real distance per pixel)

To truly understand the scale of this breakthrough, we must first understand its profound difficulties in solving the problem.
Challenge: Unlock 3D Reality from 2D Video
The ultimate goal of space AI is to make machines, robots, autonomous cars and AR glasses perceive and interact with the world in 3D. We live in a 3D world, but the vast majority of recording data from smartphone editing to movie recordings are trapped in 2D.
Core questions: How can we reliably and reliably reverse the 3D reality that engineers hide in these flat video streams?
It is well known that it is difficult to achieve this accurately from everyday videos, dynamic objects and unknown camera types, but this is An important first step For almost any advanced space application.
Existing method issues
For decades, the field has been forced to choose between 2 strong but flawed paradigms.
1. Precision Trap (Classic Grand Slam/SFM)
The traditional method is similar Simultaneous Positioning and Mapping (SLAM) and Structure – Trigger (SFM) Rely on complex geometric optimization. They are able to determine accuracy under ideal conditions.
Fatal flaw: fragility. These systems generally consider the world to be static. Introducing mobile cars, textured walls or using unknown cameras, the entire reconstruction can be broken. They are too subtle to the messy reality of everyday videos.
2. Scalability wall (end to end deep learning)
Recently, powerful deep learning models have emerged. By training on a wide range of datasets, they learn a powerful “priori” about the world and are impressively resilient to noise and vitality.
Fatal flaw: stubbornness. These models are computationally hungry. As the video length increases, their memory requirements explode, making processing of long videos nearly impossible. They don’t expand at all.
This deadlock has created a dilemma. The future of advanced AI requires a large number of data sets with perfect 3D geometry annotations, but the tools required to generate data are Too crisp or too slow Large-scale deployment.
Meet Speed: NVIDIA’s hybrid breakthrough breaks the mold
This is VIPE Change the game. This is not only an incremental improvement; it is a well-designed and integrated hybrid pipeline, Successfully merged the best of both worlds. It adopts the effective, mathematically rigorous optimization framework of the classic Grand Slam and injects it into the intuition of a powerful, learned modern deep neural network.
This synergy allows VIPE yes Accurate, robust, efficient and versatile At the same time. VIPE provides a solution that scales without compromise on precision.
It works: inside the engine
VIPEThe architecture uses key frame-based Bundle Adjustment (BA) Efficiency framework.
Here are the key innovations:
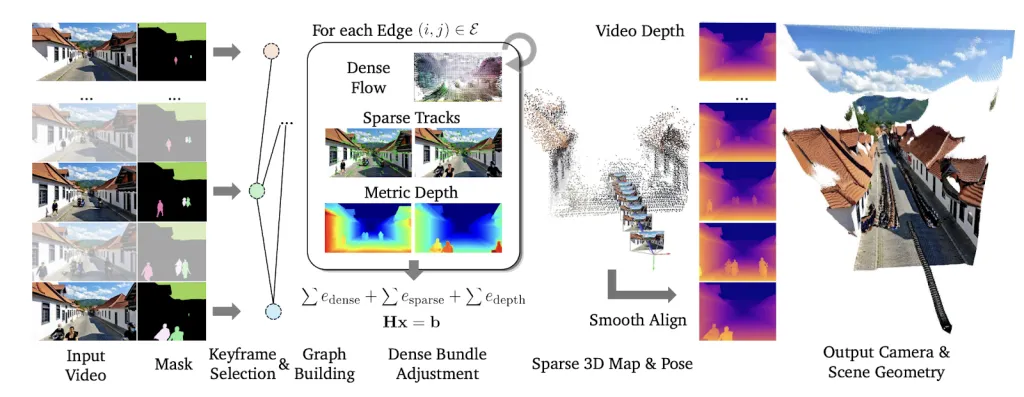
Key Innovation 1: Synergy of Powerful Constraints
VIPE achieves unprecedented accuracy by skillfully balancing three key inputs:
- Dense traffic (learning robustness): Even under difficult conditions, a learned optical flow network is used to make a robust correspondence between frameworks.
- Sparse tracks (classic precision): Combined with high resolution traditional functional tracking to capture fine-grained details, greatly improving localization accuracy.
- Metric Depth Regularization (Real World Scale): VIPE integrates the priorities of the state-of-the-art monocular depth model to produce results Real, realistic metrics.
Key Innovation 2: Mastering dynamics, real-world scenarios
To deal with the chaos of real-world videos, Vipe uses advanced basic segmentation tools. Grounding and Segmentation (SAM)identify and mask moving objects (e.g., people, cars). By wisely ignoring these dynamic areas, VIPE ensures that camera motion is calculated based on only static environments.
Key Innovation 3: Fast and General Versatility
VIPE In an extraordinary 3-5 fps on a single GPUmaking it much faster than comparable methods. In addition, Vipe is universally applicable and supports a variety of camera models including standard, wide angle/fisheye, and even 360° panoramic videos, which automatically optimize the intrinsic video of each video.
Key Innovation 4: High-Fidelity In-depth Map
The final output is enhanced by complex post-processing steps. VIPE smoothly aligns the high-tail depth map with the geometric consistency map in its core process. The results are amazing: the depth maps are all High fidelity and time stability.
The results are amazing, even complex scenarios…see below

Proven performance
VIPE Shows excellent performance, estimating baselines by surprising performance over existing uncalibrated postures:
- 18% of the TUM dataset (Indoor Dynamics)
- 50% of Kitti dataset (Outdoor driving)
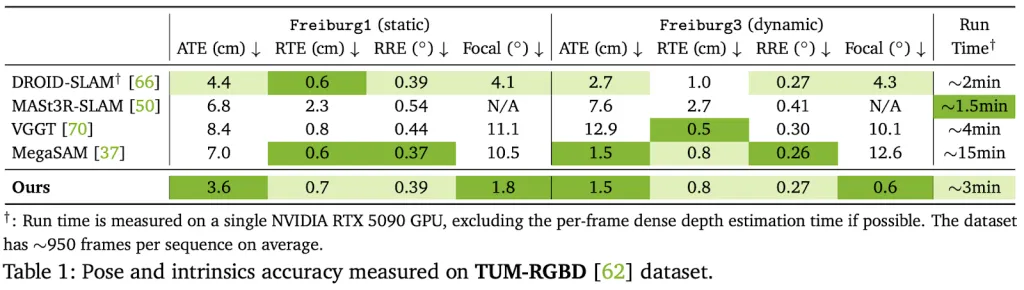
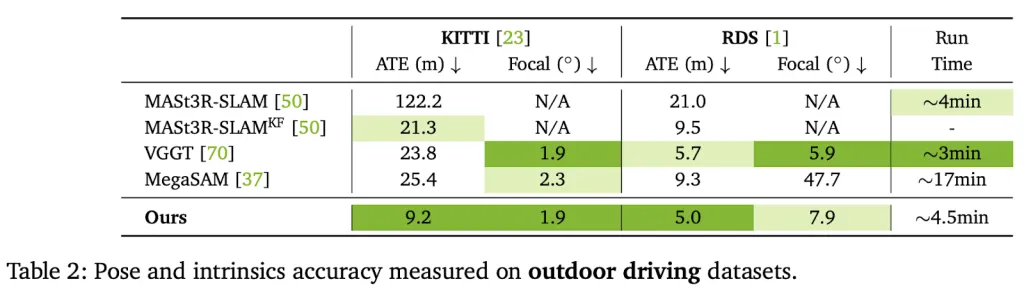
It is crucial that the assessment confirms that VIPE provides Accurate metricswhile other methods/engines often produce inconsistent unavailable scales.
Real innovation: Data explosion in space AI
The most important contribution of this work is not only the engine itself, but also its deployment as Large-scale data annotation factory Boost the future of AI. The lack of large, diverse, geometric annotated video data has been the main bottleneck in training powerful 3D models. VIPE Solve this problem!
The research team used VIPE Create and release an unprecedented dataset, total 96 million annotated frames:
- DYNPOSE-100K ++: Nearly 100,000 real-world internet videos (15.7 million frames) feature high-quality poses and dense geometry.
- WILD-SDG-1M: A large number of 1 million high-quality AI-generated videos (78 million frames) were collected.
- Web360: A dedicated dataset for annotated panoramic videos.
This large-scale launch of next-generation 3D geometric fundamentals provides the necessary fuel and has proven to play an important role in training advanced world-generation models such as Nvidia’s gen3c and universe.
By resolving the fundamental conflict between accuracy, robustness, and scalability, Vipe provides the practical, efficient and universal tools needed for 3D structures of nearly all videos. Its release is expected to accelerate innovation dramatically throughout the landscape Space AI, Robotics and AR/VR.
Nvidia ai released The code is here
Source/Link
Dataset:
Thanks to the NVIDIA team for their thought leadership/resources in this article. The NVIDIA team supports and sponsors this content/article.

Jean-Marc is a successful AI business executive. He led and accelerated the growth of AI Power’s solutions and founded a computer vision company in 2006. He is a recognized spokesperson for the AI conference and holds an MBA from Stanford University.


