NVIDIA AI has just released a streaming sorting format: Live spokesperson diagnosis, figuring out who speaks at a meeting and call immediately
Nvidia released Streaming sorting forma breakthrough in real-time spokesperson diagnosis, even in noisy, multi-speaker environments, can immediately identify and mark participants participating in conferences, call and voice applications. Designed for low latency GPU driver reasoningThe model is optimized for English and Mandarin and can track up to four simultaneous speakers with millisecond precision. This innovation marks an important step in conversational AI to enable a new generation of productivity, compliance and interactive voice applications.
Core features: real-time, multi-speaker tracking
Unlike traditional diagnostic systems that require batch processing or expensive professional hardware, Streaming sorting form implement Frame-level diagnostics real time. This means that each vocabulary is marked with a speaker tag (e.g., SPK_0, SPK_1) and is timestamped as the conversation expands. The model is Low latencyprocess audio in small, overlapping blocks, which is a key feature of real-time transcription, smart assistant and contact center analysis, in which every millisecond is.
- Tags 2–4+ speakers instant: Up to four participants can be steadily tracked in each conversation and assigned consistent labels as each spokesperson enters the stream.
- GPU accelerated reasoning: Fully optimized for NVIDIA GPUs, seamlessly integrated with NVIDIA NEMO and NVIDIA RIVA platforms for scalable production deployments.
- Multilingual support: When tuning in English, the model shows strong results on Mandarin conference data or even Callhome (such as Callhome), indicating that language compatibility exceeds its core goals.
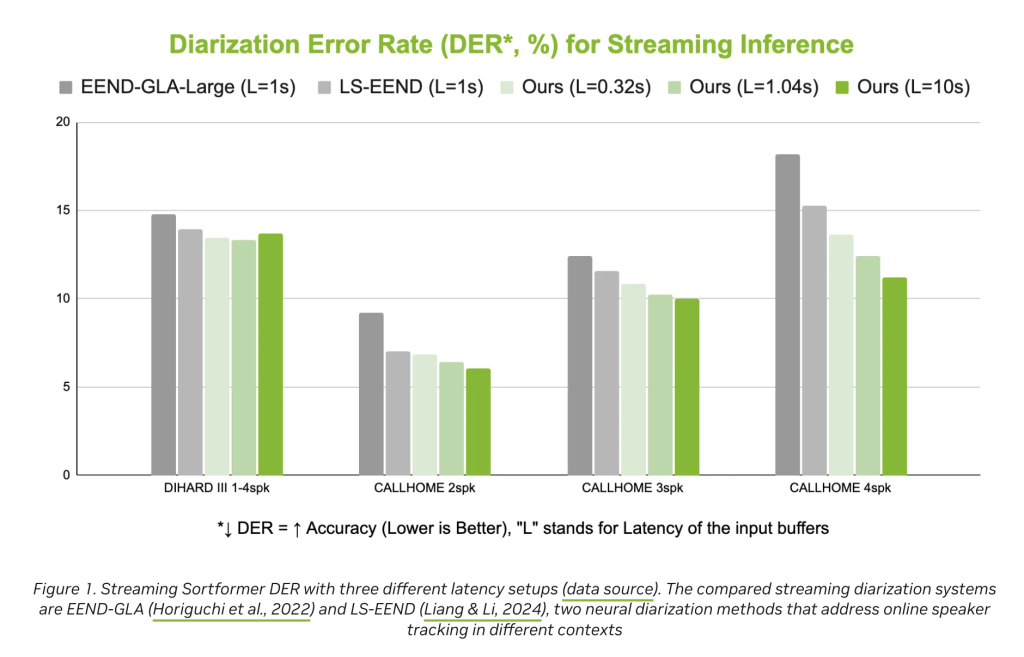
- Accuracy and reliability: Provides competitive diagnostic error rate (DER), which outperforms Eend-GLA and LS-EEND in real-world benchmarks (e.g. Eend-GLA and LS-eend).
These functions enable streaming sorting to be immediately correct On-site meeting transcript,,,,, Contact Center Compliance Records,,,,, VoiceBot Turn,,,,, Media Editorand Corporate Analysis– All situations where you know “who said what, when” are essential.
Architecture and Innovation
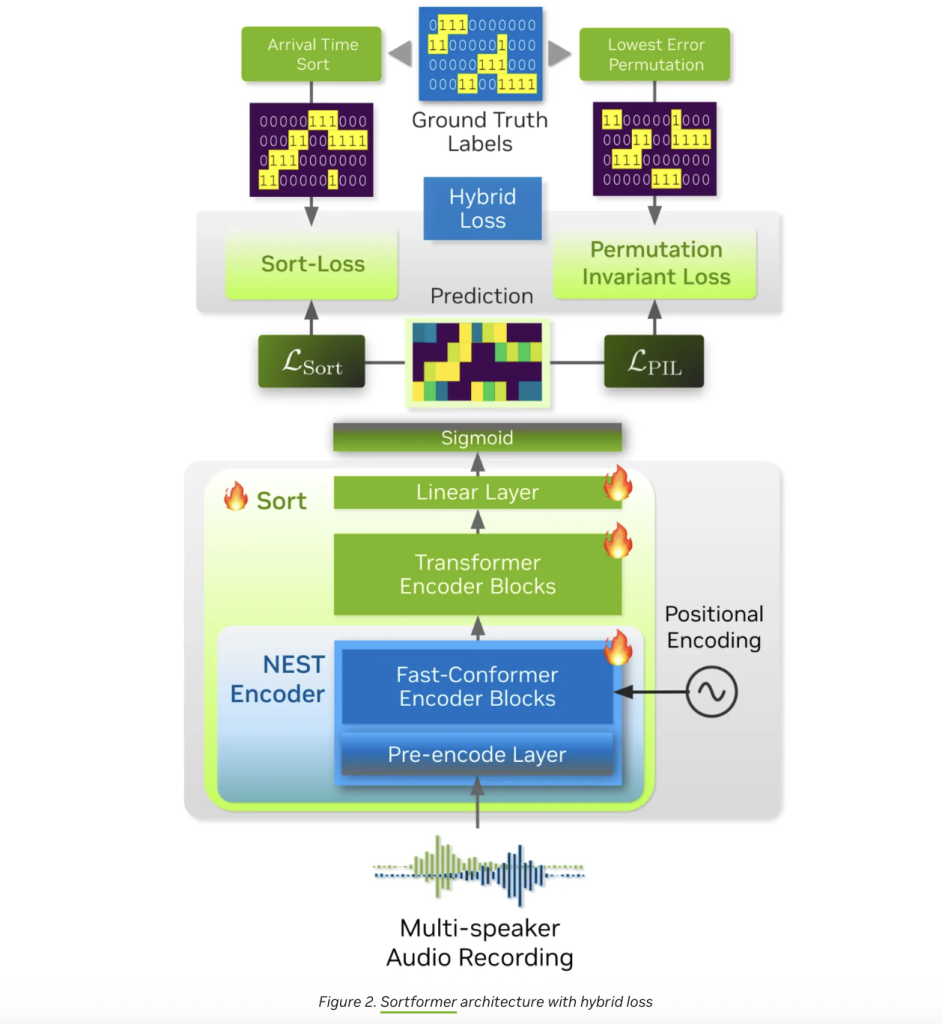
Take this as the core Streaming sorting form It is a hybrid neural structure combined with Convolutional Neural Network (CNN),,,,, Conformationand transformer. Here is how it works:
- Audio preprocessing: The convolutional precode module compresses the original audio into a compact representation, retaining key acoustic features while reducing computational overhead.
- Context-aware classification: Multi-layer fast constructor encoder (17 layers in the streaming variant) handles these functions, thereby extracting speaker-specific embeddings. They are then fed into an 18-layer transformer encoder with a hidden size of 192, followed by two feed layers, each frame with a sigmoid output.
- Arrival Level Speaker Cache (AOSC): The real magic happens here. Streaming sorting format maintains a dynamic memory buffer (AOSC) that stores embeddings of all speakers detected to date. As new audio blocks arrive, the model compares them to this cache, ensuring that each participant retains a consistent label throughout the conversation. The elegant solution to “speaker arrangement problem” is enabled Real-time, multi-speaker tracking No expensive recalculation.
- End-to-end training: Unlike some diagnostic pipelines that rely on separate speech activity detection and clustering steps, Sortformer is end-to-end trained to unify speaker separation and labeling in a single neural network.
Integration and deployment
Streaming sorting form is Open, production-grade, ready for integration Enter the existing workflow. Developers can deploy it through Nvidia Nemo or Riva, making it a replacement for traditional diagnostic systems. The model accepts standard 16KHz single-channel audio (WAV file) and outputs a matrix of speaker activity probability for each frame – ideal for building custom analysis or transcription pipelines.
Real-world applications
The actual impact of streaming sorting is great:
- Conference and productivity: Generate real-time, speaker tag transcripts and summary to make following discussions and assigning operational items easier.
- Contact Center: Independent agents and customers audio streams to compliance, quality assurance and real-time coaching.
- Dubbing robots and AI assistants: Enables more natural, context-aware dialogue by accurately tracking speaker identity and twist modes.
- Media and broadcast: Automatically mark speakers in recordings for editing, transcription and modest workflow.
- Corporate Compliance: Create auditable, speaker-resolved logs to meet regulatory and legal requirements.
Benchmark performance and limitations
In benchmarks, streaming sorting forms are implemented Lower diagnostic error rate (DER) It is more accurate than the recent ejaculation system. However, the model is currently targeted Scene with up to four speakers;Expanding to larger groups is still the field of future research. Performance may also vary in challenging acoustic environments or underrepresented languages, although the flexibility of the architecture implies a space for adaptability as new training data is available.
A clear technical highlight
| feature | Streaming sorting form |
|---|---|
| Maximum speaker | 2–4+ |
| Incubation period | Low (real-time, framework-level) |
| language | English (optimized), Mandarin (verified), other possible |
| architecture | CNN + Fast Constructor + Transformer + AOSC |
| Integration | Nvidia Nemo, Nvidia Riva, embrace the face |
| Output | Frame-level speaker tags, accurate timestamps |
| GPU support | Yes (NVIDIA GPU is required) |
| Open source | Yes (pretrained model, code base) |
Looking to the future
Nvidia’s streaming sorting form is not only a technical demonstration, but also a Production-ready tools Has changed how businesses, developers and service providers handle multispeaker audio. With GPU acceleration, seamless integration and robust performance across languages, it is expected to become the de facto standard for real-time speaker diagnosis in 2025 and beyond.
For AI managers, content creators and digital marketers, focusing on conversational analytics, cloud infrastructure or voice applications, Streaming sorting is a platform that must be evaluated. Its combination of speed, accuracy and ease of deployment makes it a compelling choice for anyone who builds the next generation of voice products.
Summary
NVIDIA’s streaming sorting format provides instant, GPU-accelerated speaker diagnosis to up to four participants and provides reliable results in English and Mandarin. Its novel architecture and open accessibility use it as the fundamental technology for real-time voice analysis – meetings, contact centers, AI assistants and other leaps in the region.
FAQ: NVIDIA Streaming Sort Format
How to handle multiple speakers in real time in streaming sorting?
Streaming sorting forms process audio in small overlapping blocks and assign consistent labels (e.g., spk_0 – spk_3), each speaker enters the conversation. It maintains a lightweight memory of the detected speakers, allowing immediate, frame-level diagnosis without waiting for a full record. This supports real-time transcripts, contact centers and voice assistants for fluid, low latency experience.
What hardware and settings are recommended for best performance?
It is designed for NVIDIA GPUs to enable low latency inference. A typical setup uses 16 kHz mono input and has an integrated path through NVIDIA’s voice AI stack (e.g., Nemo/riva) or a pre-trial pre-performed model available. For production workloads, the closest NVIDIA GPU is allocated and stream-friendly audio buffering is ensured (e.g., 20-40 millisecond frames, with slight overlap).
Does it support languages other than English and how many speakers can be tracked?
The current release targets English and has proven performance in Mandarin and can be tagged with two to four speakers at any time. Although it can be extended to other languages to some extent, accuracy depends on acoustic conditions and training coverage. For scenarios with more than four concurrent speakers, consider the development of session segmentation or evaluation pipeline adjustment as a model variant.
Check Model embracing face and Technical details are here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


