Nebius AI enhances open LLM with enhanced learning from powerful SWE agents
Driven by advances in large language models (LLMS), the landscape of software engineering automation is developing rapidly. However, most agents’ approaches to training competence rely on proprietary models or expensive teacher approaches, while in the real world, open weighted LLMs have limited functionality. A team of researchers from Nebius AI and Humanoid proposed an enhanced learning framework for training novels, multi-turn software engineering agents, using improved decoupling advantage strategy optimization (DAPO) algorithms. Research explains the breakthrough in applied technology Strengthening Learning (RL) Open source LLM to complete a truly multi-turn software engineering mission, transcends the dominant single-turn, robber-style setting of today’s LLM.
Beyond single transfer Reinforcement learning RL
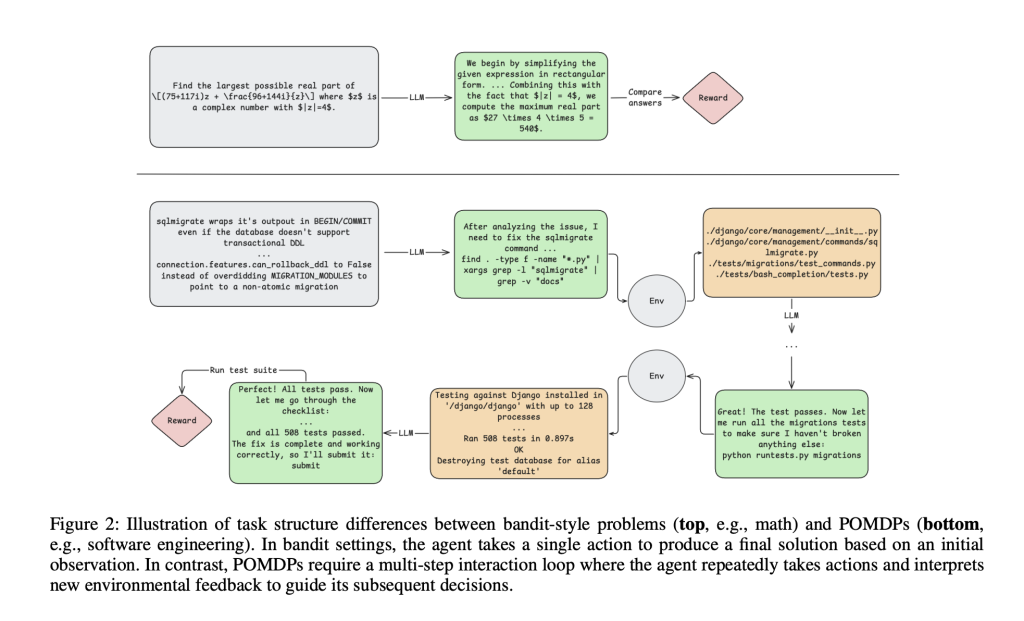
Most RL methods of LLM are optimized for tasks such as mathematical reasoning or single-tone code generation, where proxy operations are rewarded only in conclusions and the environment does not provide intermediate feedback. However, Software Engineering (SWE) The fundamental difference: It requires an agent to operate Long sequenceexplain rich feedback (compiler errors, test logs), and maintain the context of hundreds of thousands of tokens, exceeding the typical single-step interactive loop.
SWE’s RL core challenge
- Long horse reasoning: The proxy must maintain logical coherence in many steps, often requiring context windows of more than 100k tokens.
- National environmental feedback: Actions produce meaningful non-trivial observations (e.g., Shell command output, test suite results) that guide subsequent decisions.
- Sparse/delay rewards: Success signals usually appear only at the end of a complex interaction, complicating credit allocation.
- Assess complexity: The measurement progress requires full trajectory expansion and can be noisy due to the test sheet.
Technical formula: Modified DAPO and agent design
The research team demonstrated Two-stage learning pipeline Used to train QWEN2.5-72B teachers:
1. Reject Fine Tweak (RFT)
The journey begins with fine-tuning of supervision. The proxy spans 7,249 strictly filtered SWE tasks (from the SWE-Rebench dataset). Successful interaction trajectories (through the environment test suite of agents) are used to fine-tune the model, especially to mask ineffective environmental formation actions during training. This alone alone improves the baseline accuracy from 11% to 20% from the SWE board-based validation benchmark.
2. Hardening learning with modified DAPO
Based on the separation advantage optimization (DAPO), several key modifications have been introduced for scalability and stability:
- Asymmetrical clip: Prevent policy entropy collapse to keep exploring.
- Dynamic sample filtering: Focus on trajectories with actual learning signals.
- Length penalty: Dissuading the attacks to be too long and helping agents avoid falling into a loop.
- Average value of token level: Each token in each trajectory contributes the gradient equally, thus giving longer trajectories to affect updates.
The agent uses a reactive loop that allows it to combine inference steps with tool usage. Its supported toolkit includes arbitrary shell commands, precise code editing, navigation/search utilities, and submit operations to complete signal plot completion. Each interaction is based on a powerful sandbox environment, initialized from a real repository snapshot and supported by github-style question prompts.
Extended to long context and real benchmarks
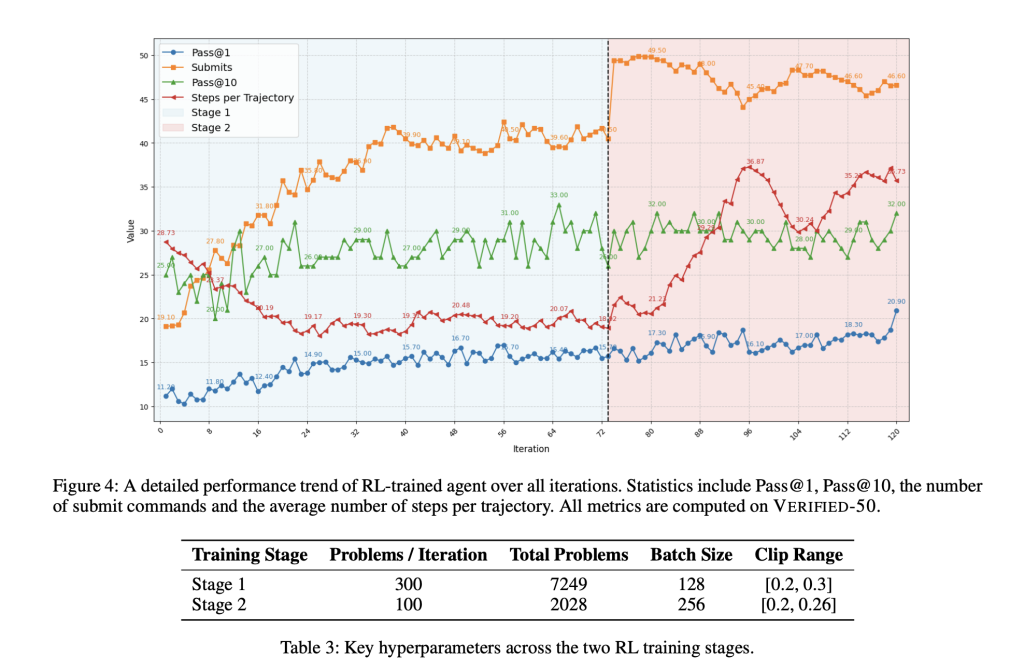
The initially accepted context length is 65K tokens (already double the tokens for most open models) and the performance stall is 32%. The second RL phase extends the context to 131k tokens and doubles the upper limit of plot length, thus focusing subsequent training on the most beneficial tasks in the pool. This allows scaling to scale debug and patch tasks inherent in stacking trajectories and differences history.
Results: Use baseline to narrow the gap
- The final RL training agent reaches 39% by @1 The accuracy of the benchmark test for SWE basic verification, double The rejected fine-tuning baseline and matches performance of cutting-edge open models such as DeepSeek-V3-0324, all without teacher-based supervision.
- In the held SWE-REBCHENCH split, the score remained competitive (May 35%, June 31.7%), indicating the robustness of the method.
- When head-to-head is compared to the top open baseline and a dedicated SWE agent, the RL agent matches or outperforms multiple models, thus confirming the effectiveness of the RL method in this domain.
| Verified by @1 SWE pallet | By @10 | via @1 swe-rebench possible | By @10 | |
|---|---|---|---|---|
| QWEN2.5-72B-INSTRUCT (RL, final) | 39.04% | 58.4% | 35.0% | 52.5% |
| DeepSeek-V3-0324 | 39.56% | 62.2% | 36.75% | 60.0% |
| QWEN3-235B No Thought | 25.84% | 54.4% | 27.25% | 57.5% |
| Llama4 Maverick | 15.84% | 47.2% | 19.0% | 50.0% |
Average 1 point in 10 runs by @1 point and reported as mean ± standard error.
Key Insights
- Credit distribution: In this sparse reward regime, RL is basically still challenging. This article presents future work to reward molding, step-by-step critics or prefix-based promotions to provide more granular feedback.
- Uncertainty Estimation: Real-world agents need to know when to abstain or express confidence. Techniques such as output entropy or explicit confidence scores are the next step.
- Infrastructure: Training utilizes contextual parallelism (dividing long sequences on 16 H200 nodes) and distributed orchestration through Kubernetes and Tracto AI, while VLLM performs rapid inference.
in conclusion
This study validates RL as an effective paradigm for building automated software engineers using open LLM. By conquering long horses, multi-transfer, and achieving environmental tasks, this approach paves the way for scalable, teacher-free agent development methods – leveraging the power of interaction instead of static guidance. With further improvements, this RL pipeline is expected to be effective, reliable and versatile automation for the future of software engineering.
Check The paper is here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.


