Nearly 80% of training data sets may pose legal harm to corporate AI
A recent paper from LG AI research suggests that “open” datasets used to train AI models may provide a false sense of security – found that in five AI datasets, nearly four datasets marked “commercially used” actually contain hidden legal risks.
These risks range from the inclusion of undisclosed copyrighted material to restrictive licensing terms buried deep in the dependencies of the dataset. If the findings in this article are accurate, companies relying on public data sets may need to rethink their current AI pipeline, or expose them in downstream laws.
Researchers have proposed a fundamental and potentially controversial solution: AI-based compliance agents that can scan and review dataset history faster and more accurately than human lawyers.
The paper points out:
“This article argues that legal risks to AI training datasets cannot be determined entirely by reviewing surface-level licensing clauses; thorough end-to-end analysis of dataset redistribution is essential to ensure compliance.
“Because such analysis exceeds human capabilities due to its complexity and scale, AI agents can bridge this gap with higher speed and accuracy. Without automation, critical legal risks remain largely unchecked, which endangers the development of ethical AI and regulatory compliance.
“We urge the AI research community to view end-to-end legal analysis as a fundamental requirement and adopt an AI-driven approach as a viable avenue for scalable data collections.”
Studying 2,852 popular datasets that are commercially used under their separate licensing, the researchers’ automation system found that once all components and dependencies were tracked, only 605 (about 21%) were legally safe to commercialize.
The title of the new paper is Don’t trust the licenses you see – Data collection rules require large-scale AI-driven lifecycle trackingand eight researchers from LG AI research.
Rights and errors
The author highlights the challenges faced by companies that drive AI development in an increasingly uncertain legal landscape – as the former academic “fair use” mentality surrounding dataset training gives way to a broken environment where legal protection is unclear and no longer guarantees a safe harbor.
As one publication recently pointed out, companies are becoming increasingly defensive about the source of their training data. Author Adam Buick Comment*:
‘[While] Openai disclosed the main data sources of GPT-3, and the paper introduces GPT-4 reveal Only the data from the training model is a “mixture of publicly available data (such as Internet data) and data licensed from a third-party provider”.
“AI developers have not shed light on the motivation for this shift in any detail, and in many cases, they have no explanation at all.
“For part of it, Openai proved that its decision not to publish more details about GPT-4 based on concerns about “the security implications of competitive landscape and large-scale models” without further explanation in the report.
Transparency can be an unwise term or a wrong term; for example, Adobe’s flagship Firefly Generation Model has been trained in stock data that Adobe has the right to use, and is said to assure customers that their legality of using the system. Later, there was some evidence that Firefly Data Pot had “enriched” copyrighted data from other platforms.
As we discussed earlier this week, there are growing plans to ensure license compliance in the dataset, including scratching YouTube videos with only flexible Creative Commons licenses.
The problem is that, as the new research shows, these licenses may be wrong in themselves or they may be wrong.
Check open source datasets
It is difficult to develop an evaluation system, such as the author’s connection, when the context keeps changing. Therefore, this article points out that the Nexus data compliance framework system is based on “various precedents and legal reasons at this time.”
Nexus’ AI-powered proxy is called Automatic compliance For automatic data compliance. Automatic symbols consist of three key modules: a navigation module for web exploration; a question-asking (QA) module for information extraction; and a scoring module for legal risk assessment.
Automatic symbols start with a user-provided webpage. AI extracts key details, searches for relevant resources, determines license terms and dependencies, and assigns legal risk scores. Source: https://arxiv.org/pdf/2503.02784
These modules are powered by fine-tuned AI models, including the Exaone-3.5-32b-Instruct model trained with synthetic and human labeled data. Automatic compliance also uses databases to cache results for efficiency.
Automatic symbols start with the user-provided dataset URL and treat it as the root entity, search for its license terms and dependencies, and then recursively track the linked dataset to build a license dependency graph. Once all connections are mapped, it calculates compliance scores and assigns risk classification.
The data compliance framework outlined in the new work identifies various† The types of entities involved in the data life cycle, including Datasetwhich constitutes the core input of AI training; Data processing software and AI modelsused to convert and utilize data; and Platform service providerhelps in data processing.
The system evaluates legal risks overall by considering these various entities and their interdependencies rather than rote assessments of dataset licenses to include a broader ecosystem of components involved in AI development.
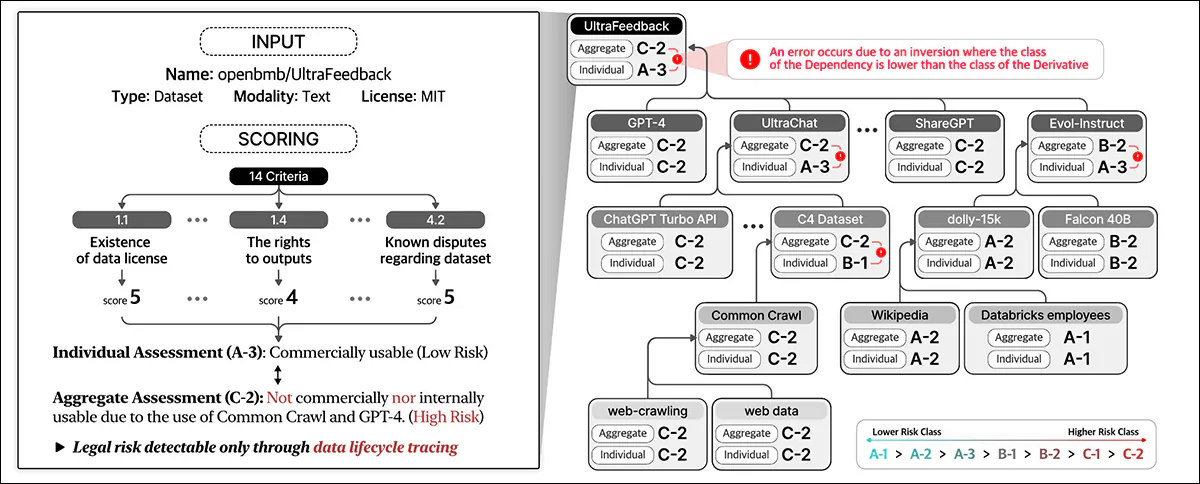
Data compliance assesses legal risks throughout the data life cycle. It assigns scores based on dataset details and 14 criteria, classifies individual entities and summarizes risks across dependencies.
Training and indicators
The author extracted the URLs of the top 1,000 most downloaded datasets on the hug surface and randomly sampled 216 items to form the test set.
The Exaone model is fine-tuned on the author’s custom dataset, and uses synthetic data for navigation modules and problem absorption modules, and uses human-labeled data for scoring modules.
The Ground Truth Tag was created by five legal experts who trained for at least 31 hours on similar tasks. These human experts manually identified the dependencies and licensing terms for 216 test cases, and then summarized and refined their findings through discussion.
More dependencies are found in license terms through a trained, trained, artificially calibrated automatic symbology for Chatgpt-4O and Confusion Pro:
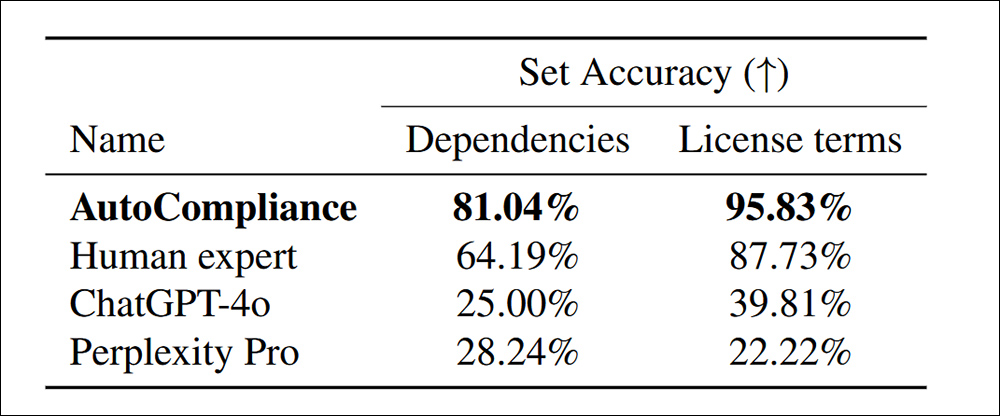
Determine the accuracy of the dependencies and license terms of the 216 evaluation datasets.
The paper points out:
“Automatic symbols greatly outperform all other agents and human experts, with accuracy of 81.04% and 95.83% in each task. In contrast, both Chatgpt-4O and Confusion Pro show relatively low accuracy for source and license tasks, respectively.
“These results highlight the excellent performance of automatic symbols, demonstrating its effectiveness in handling both tasks, and also demonstrating a large performance gap between AI-based models and human experts in these domains.”
In terms of efficiency, the automatic compliance method takes only 53.1 seconds to run, compared to the 2,418 seconds of equivalent human evaluation for the same task.
Additionally, the price for the assessment run is $0.29, while for the human expert, it is $207. However, it should be noted that this is based on the monthly rental of GCP A2-megagpu-16 GPU nodes of $14,225 per month, meaning that this cost-effectiveness is primarily related to large operations.
Dataset Survey
For the analysis, the researchers selected 3,612 datasets that combined 3,000 easiest datasets to sell from 612 datasets in the 2023 datasets.
The paper points out:
Starting from 3,612 target entities, we identified a total of 17,429 unique entities, of which 13,817 emerged as direct or indirect dependencies of the target entity.
“For our empirical analysis, if an entity does not have any dependencies and multi-layer structure, we will have an entity and its license dependency graph with a single-layer structure if it has one or more dependencies.
“In the 3,612 target datasets, 2,086 (57.8%) have multi-layer structures, while the other 1,526 (42.2%) have single-layer structures without dependencies.”
Copyright-protected datasets can only be redistributed with legal authority, which may come from licenses, copyright law exceptions, or contractual terms. Unauthorized redistribution may result in legal consequences, including copyright infringement or contractual breach. Therefore, it is essential to clearly identify violations.
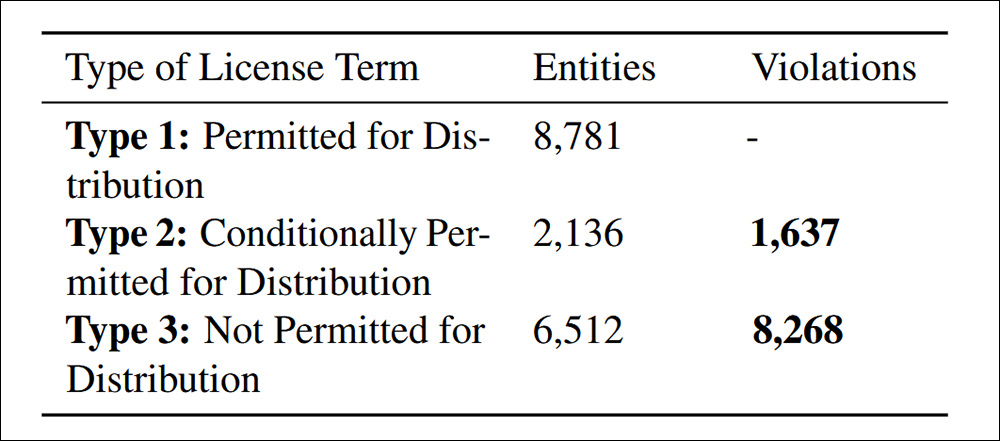
Distribution violations found in accordance with Standard 4.4 cited in this article. Data compliance.
The study found that there were 9,905 non-compliant data set redistributions, which were divided into two categories: 83.5% were explicitly banned under the licensing clause, which made the reallocation a clear violation of the law; 16.5% of the data sets involved data sets with conflicting licensing conditions, which theoretically allowed reallocation but failed to meet the required clauses, posed a downstream legal risk.
The author acknowledges that the risk standards proposed by Nexus are not universal and may vary by jurisdiction and AI applications, and that future improvements should focus on adapting to changing global regulations while refining AI-driven legal reviews.
in conclusion
This is a ProLix and largely unfriendly paper, but addresses the biggest obstacles to the adoption of AI in the current industry – obviously, the possibility of various entities, individuals and organizations clearly demanding “open” data.
Under DMCA, violations can result in high legal fines per capita Base. In the case where researchers found that violations can fall into millions of places, potential legal liability is indeed important.
Furthermore, at least in the U.S.-powered market, companies that can prove to be (as usual) ignorant. They also don’t have any realistic tools to penetrate the meaning of the maze buried in the alleged open source dataset license agreement.
The problem with developing a system like Nexus is that it challenges it on every country within the United States or every basis within the EU. The prospect of creating a true global framework (a kind of “Interpol from which data sets come from”) is not only undermined by conflict motives from the various governments involved, but also the fact that these governments and current laws are constantly changing in this regard.
* I replaced the hyperlink with the author’s citation.
† Six types are specified in the paper, but the last two are undefined.
First published on Friday, March 7, 2025


