MIT’s LEGO: Compiler for AI chips that automatically generates fast and efficient space accelerators
MIT Researchers (HAN LAB) introduces Lego, Similar to compiler Framework that requires tensor workloads (e.g., Gemm, Conv2d, Note, MTTKRP) and automatically Generate synthesizable RTL For Space Accelerator – No handwritten templates. Lego’s front end represents workload and data flow Relational-centered affine representationbuild FU (functional unit) interconnection and On-chip memory Reused layouts and support Converge multiple spatial data streams In a design. The backend lowers to the original level graph and uses Linear programming Transform the graphics into insert pipe registers, rebroadcast, extract restore trees and Contraction area and strength. LEGO generated hardware programs are evaluated across basic models and classic CNN/Transformers 3.2×acceleration and 2.4×Energy Efficiency Under matching resources, Gemmini.
Hardware generation without templates
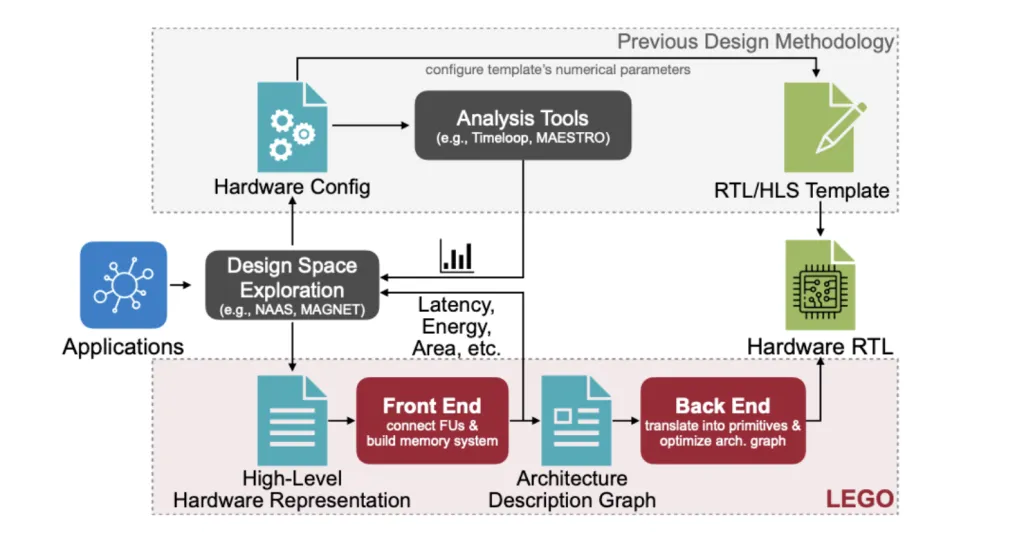
Existing traffic either: (1) analyze data flow without generating hardware, or (2) from Manual adjustment template With fixed topology. These approaches limit building space and fight against the modern workloads needed Dynamically switch data flow Cross-layer/operation (e.g. Cons vs. Depthiswise vs. Attention). Lego directly targets Any data stream and combinationgenerate both architecture and RTL from the advanced description instead of configuring some numeric parameters in the template.
Input IR: Affine, relationship-centric semantics (deconstruction)
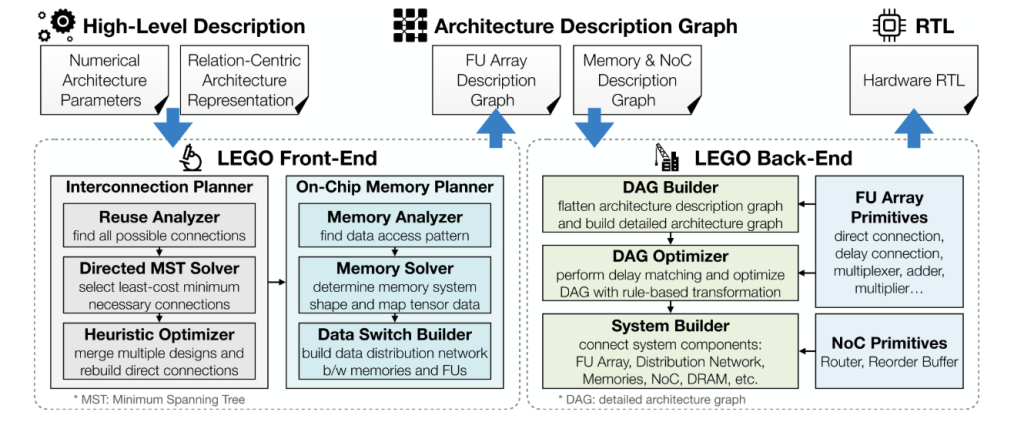
The LEGO model tensor program nests as a loop with three index classes: temporal (for-loops), space (Pole type) and calculate (Introduction to iterative domain in advance). Two affine relationship-driven compilers:
- Data Mapping FI→DF_ {I→D}: Map the computed index to the tensor index.
- Data flow mapping fts→if_{ts→i}: Map time/spatial index to computed index.
this Affine only Indicates that modulus/splitting is eliminated in core analysis Reuse detection and Address generation Linear algebra problem. Lego Off-control flow From the data stream (vector c Encoding control signal propagation/delay), enable Shared control Between FUS, the control logic overhead is greatly reduced.
Front-end: FU graphics + memory co-design (architect)
The main purpose is to maximize the use of reuse and chip bandwidth while minimizing interconnect/MUX overhead.
- Interconnect synthesis. LEGO will reuse it as a linear system to solve affine relationship to discover linear systems Direct and Delay (FIFO) Connection between FUS. Then calculate Branches with minimum span (Chu-Liu/Edmonds) Only the necessary edges are retained (cost = FIFO depth). one BFS-based heuristics Rewrite Direct When is the interconnection Multiple data streams Must coexist, prioritizing reuse of chains and nodes that have been connected through delays to cut Muxes and data nodes.
- Store memory synthesis. Given a set of FUSs that must read/write tensors in the same cycle, Lego calculates Bank counts each tensor size From the maximum index delta (optionally divided by GCD to reduce banking). Then instantiate Data distribution switch To route between the bank and FUS, reuse Fu-to-Fu with interconnect.
- Data flow convergence. The interconnection of different spatial data streams is combined into a single FU level Architecture Description Diagram (ADG); Careful planning avoids naive Mux Hevy merges and generates ~20% energy growth Compared with childish fusion.
Backend: Compile and optimize to RTL (compile and optimize)
Lower ADG to Detailed Architecture Diagram (DAG) Primitives (FIFOS, MUXES, ADDER, Address Generator) Lego applies multiple LP/Graph pass:
- Delay matching via LP. Linear program selection output delay DVD_V to Minimize insertion pipe registers ∑(dv-du-lv)Hotsum(d_v-d_u-l_v)cdotcdottext{bitwidth}Span-Align with the minimum storage time.
- The broadcast pin is rewired. Two-stage optimization (virtual cost shaping between destinations + MST-based rewiring) converts expensive broadcasts to Forward Chainenable register sharing and reduce latency; the final LP rebalancing latency.
- Restore tree extraction + dowel reuse. Sequential addition chain becomes The balanced tree;one 0-1 ILP Reconstruction reducer input across data streams, so fewer physical pins (MUX instead of adding). This reduces both Logical depth and Registration Count.
The focus of these passing is DataPathit dominates the resources (e.g., fu-array registration amount ≈ 40% area,,,,, 60% power) and produce ~35% area savings With the childish generation.
result
set up. Lego uses High as the C++ implementation of the LP solver and emits spinalhdl→Verilog. The evaluation covers tensor kernel and end-to-end models (Alexnet, MobilenetV2, Resnet-50, EditionNetV2, Bert, Gpt-2, Gatnet, Coatnet, DDPM, Stable Diffusion, Llama-7b). one LEGO – Minnik Use accelerator instances across models; mappers select per capita tile/data stream. Gemmini is the main baseline Matching resources (256 Mac, 256 KB tablet buffer, 128-bit bus @ 16 GB/s).
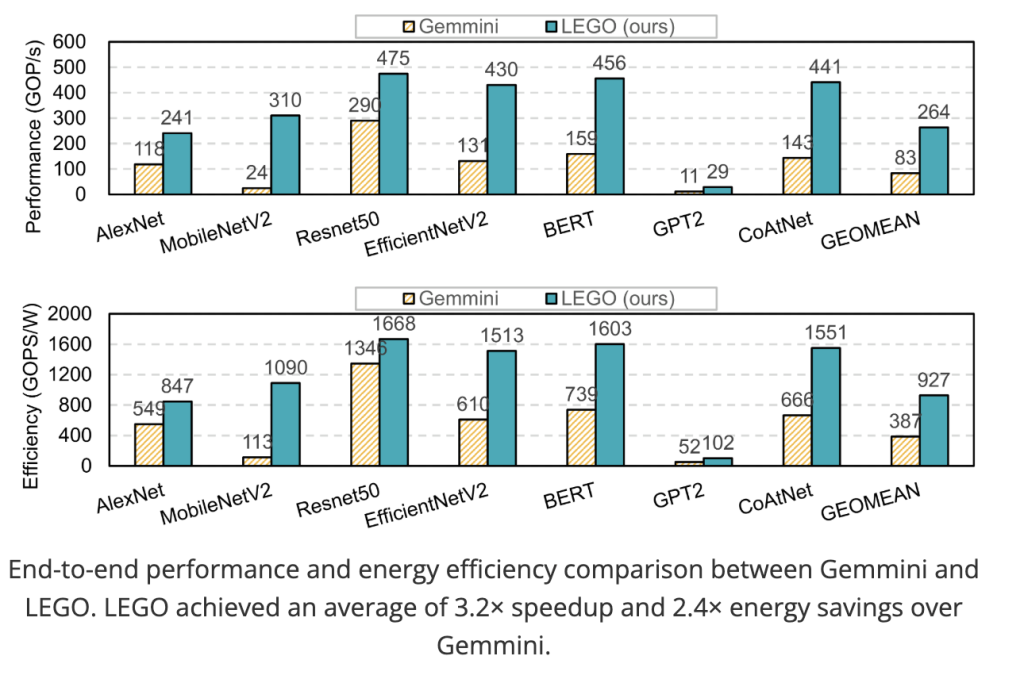
End-to-end speed/efficiency. LEGO Achievements 3.2× Accelerate and 2.4× Energy efficiency average with Gemmini. The benefits come from: (i) Fast and accurate performance models Guidance mapping; (ii) Dynamic spatial data flow switching Enable via the generated interconnect (e.g., select OH – OW –IC – OC for the depth conversion layer). Both designs are bandwidth limits on GPT-2.
Resource decomposition. Sample SOC style configuration display fu array and noc Dominant/Strength, PPU Contribution ~2–5%. This supports the decision to actively optimize data diameter and control reuse.
Generate the model. In larger 1024-FU configuration, LEGO maintains > 80% utilization rate For DDPM/stable diffusion; Llama-7b remains bandwidth-limited (expected for low operating intensity).
Importance to each segment
- For the researchers: Lego offers Basics of Mathematics From loop nest specification to Space Hardware and Proofable LP optimization. It abstracts low levels of RTL and exposes meaningful leverage (tiling, spatialization, reuse mode) for systematic exploration.
- For practitioners: This works Hardware – Code. You can locate Any data stream and fuse They are in an accelerator, allowing the compiler to derive interconnects, buffers and controllers while reducing MUX/FIFO overhead. This has improved vitality and support Multi-level pipeline No manual template redesign.
- For the product owner: go through Reduce barriers to custom siliconLEGO enabled Task adjustment, power efficiency Edge accelerators (wearable devices, IoT) keep in sync with fast-moving AI stacks –Silicon adaptation model, not the other way around. The end-to-end results for state-of-the-art generators (Gemmini) quantify the upstream space.
How “AI Chip Compiler” works – Step by step?
- Deconstruction (Aggine IR). Writing tensor op as loop nest; supplying affine f_ {i→D} (Data map), f_ {ts→i} (Data flow) and control flow vector c. This specifies What Calculate and how It is spatial and has no templates.
- Architect (photo synthesis). Solve the reused equation → FU interconnect (Direct/Delay) → MST/heuristic approach For the smallest edge and converged data streams; Bank memory and Distribution switch There are no conflicts in order to satisfy concurrent access.
- Compilation and optimization (LP + Graphic Transformation). Lower to original dag; running Delay matching LP,,,,, Broadcast Rewiring (MST),,,,, Restore tree extractionand PIN-REUSE ILP;fulfill Bit width inference and optional Power Door. These are delivered together ~35% area and ~28% energy Savings and childish code.
Does it land in the ecosystem?
Compared with analysis tools (Timeloop/Maestro) and template binding generators (Gemmini, DNA, magnets), Lego No template,support Any data stream and Their combination,issue Comprehensive RTL. Results show Comparable or better In similar data streams and technologies, the area/power with expert handwritten accelerator is provided A structural model deploy.
Summary
LEGO Operations Hardware generation as compilation For tensor program: affine front end Reused interconnect/memory synthesis and the backend of LP driver DataPath Minimization. Measurement of the frame 3.2× Performance and 2.4×Energy Gain profits on leading open generators ~35% area Reduce backend optimization and position it as a practical approach Application-specific AI accelerator On the edge and beyond.
Check Paper and project page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


