MiniMax launches MiniMax M2: a mini open model built for Max encoding and proxy workflows, at 8% the price and about 2x faster Claude Sonnet
Can an open source MoE truly support agent coding workflows at a fraction of the cost of the flagship model, while maintaining long-term tool usage across MCP, shell, browser, retrieval, and code? The MiniMax team just released MiniMax-M2a hybrid of expert MoE models, optimized for encoding and agent workflows. Published under the MIT license on Hugging Face, the model is positioned for end-to-end tool usage, multi-file editing, and long-term planning. It lists 229B total parameters with about 10B activity per token, which controls memory and latency during the agent cycle.
Architecture and why activation size matters?
MiniMax-M2 is a compact MoE with each token routed to approximately 10B active parameters. Smaller activations can reduce memory pressure and tail latency in plan, act, and verify loops, and allow for more concurrent runs in CI, browse, and retrieval chains. This is the performance budget to achieve speed and cost claims relative to dense models of similar quality.
MiniMax-M2 It is an intertwined mode of thinking. Research team incorporates internal reasoning
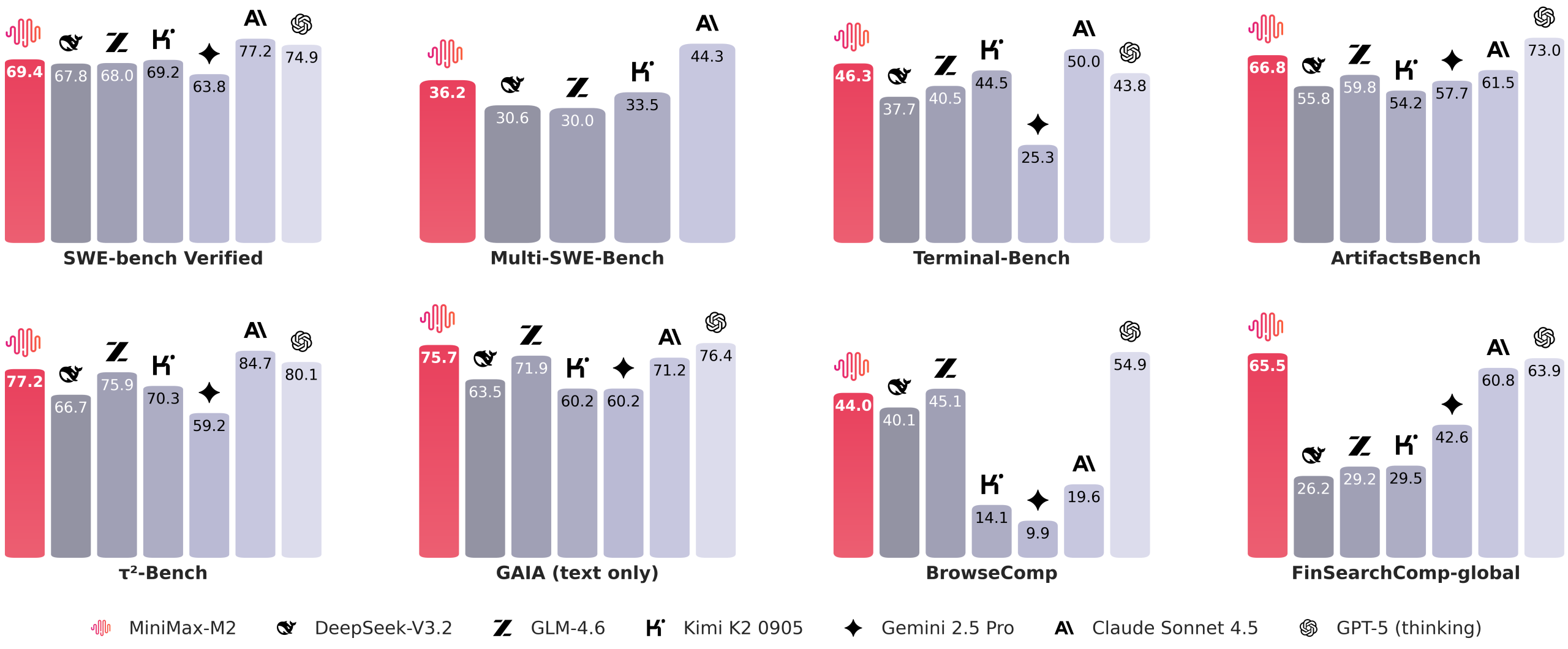
Benchmarks for encoding and proxies
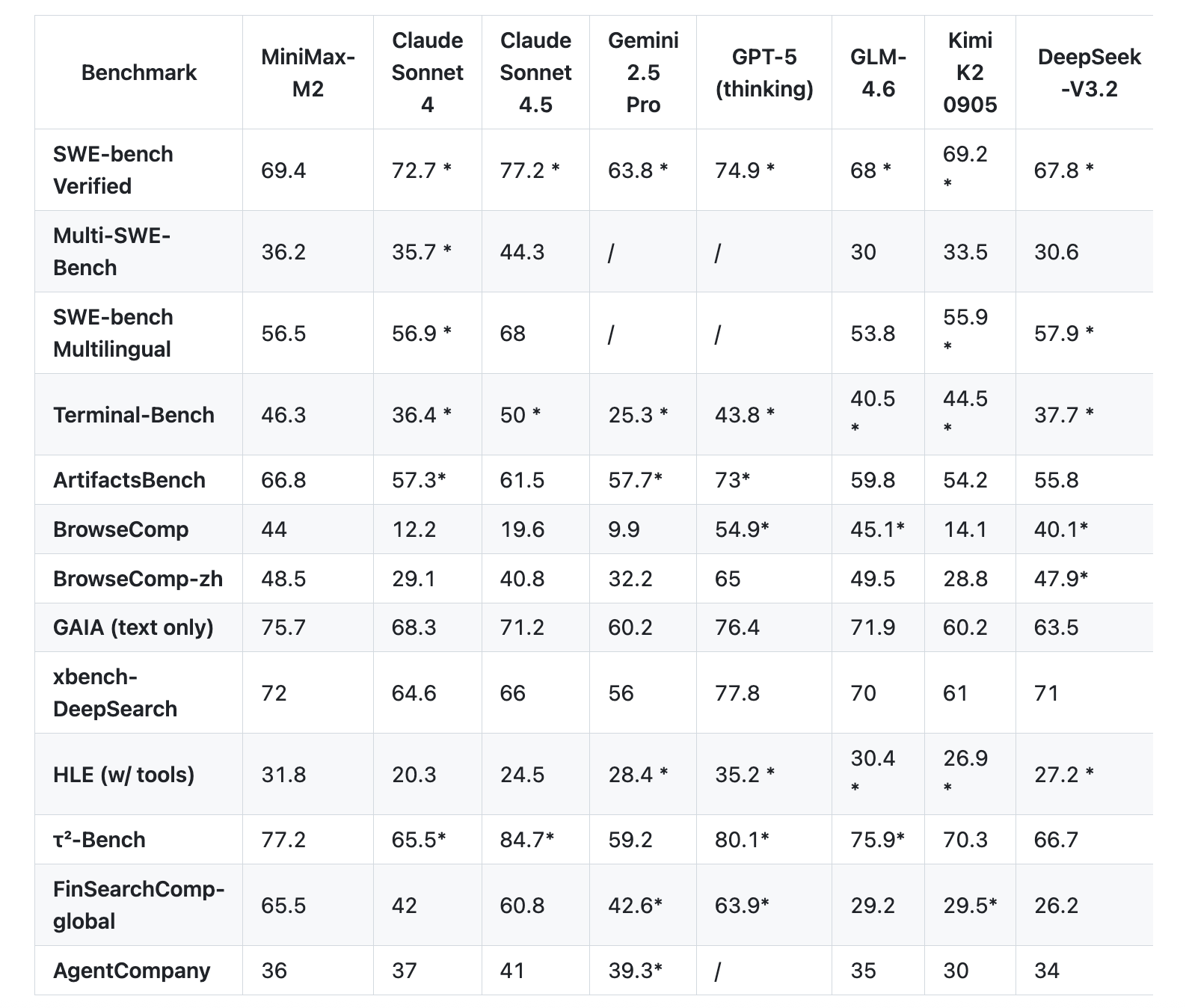
The MiniMax team reports that a set of agents and code evaluations are closer to the developer workflow than static QA. On Terminal Bench, the table shows 46.3. On Multi SWE Bench, it shows 36.2. On BrowseComp it shows 44.0. SWE Bench Verified has a scaffold detail of 69.4 and OpenHands has 128k contexts and 100 steps.
MiniMax’s official announcement highlights 8% of Claude Sonnet’s pricing and nearly 2x the speed, plus a free access window. The same note also provides specific token prices and trial periods.
M1 vs. M2 comparison
| aspect | Mini Max M1 | Mini Max M2 |
|---|---|---|
| Total parameters | Total 456B | The model card metadata is 229B, and the model card text displays a total of 230B. |
| Activity parameters for each token | 45.9B active | 10B active |
| core design | A mixture of expert and lightning concerns | A sparse mix of experts for coding and agency workflows |
| thinking format | Think budget variants 40k and 80k in reinforcement learning training without think tag protocol | Cross thinking and |
| Highlighted benchmarks | AIME, LiveCodeBench, SWE benchmark verification, TAU benchmark, long context MRCR, MMLU-Pro | Terminal-Bench, Multi SWE-Bench, SWE-bench Verified, BrowseComp, GAIA Text Only, Human Analysis Intelligence Suite |
| Reasoning defaults | temperature 1.0, top p 0.95 | Model card shows temperature 1.0, top p 0.95, top k 40, boot page shows top k 20 |
| Service guidance | vLLM is recommended, and the Transformers path is also recorded | Recommend vLLM and SGLang and provide tool calling guide |
| main focus | Long-context reasoning, efficient extensions to test-time computation, CISPO reinforcement learning | Agent and code-native workflows across shell, browser, retrieval and code runners |
Main points
- M2 is released as an open weight on MIT’s Hugging Face, and the security tensors are F32, BF16 and FP8 F8_E4M3.
- The model is a compact MoE with 229B total parameters and ~10B activity per token, which the card ties together with lower memory usage and more stable tail latency in the agent’s typical plan, act, verify loop.
- The output contains internal reasoning
... - The reported results cover Terminal-Bench, (Multi-)SWE-Bench, BrowseComp, etc., with reproducible scaffolding annotations, and record Day-0 services of SGLang and vLLM as well as specific deployment guides.
Editor’s Note
MiniMax M2 landed under MIT as an open-weight, expert-designed hybrid with 229B total parameters and ~10B activation per token, targeting proxy loops and encoding tasks with lower memory and more stable latency. It ships on Hugging Face as a safetensor in FP32, BF16 and FP8 formats, and provides deployment instructions and chat templates. The API documents Anthropic compatible endpoints and lists pricing with a limited free evaluation window. vLLM and SGLang recipes are available for local serving and benchmarking. Overall, the MiniMax M2 is a very solid open build.
Check API documentation, weights, and repositories. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


