Meta’s ARE + Gaia2 sets a new standard for asynchronous, event-driven AI agent evaluation
Yuan artificial intelligence launched Agency Research Environment (ARE)a modular simulation stack for creating and running agent tasks, and Gaia 2a follow-up benchmark to GAIA for evaluating agents in a dynamic, writable setting. ARE provides abstraction Applications, environments, events, notifications, and scenes; Gaia2 runs on ARE and focuses on functions other than search and execution.
Why move from sequential to asynchronous interaction?
Most previous agent benchmarks have the model pause the world while it “thinks”. ARE decouples agent and environment time: The environment changes as the agent reasonsinject scheduled or random events (e.g., replies, reminders, updates). This forces capabilities such as initiative, interruption handling, and deadline awareness that cannot be measured in a synchronous environment.
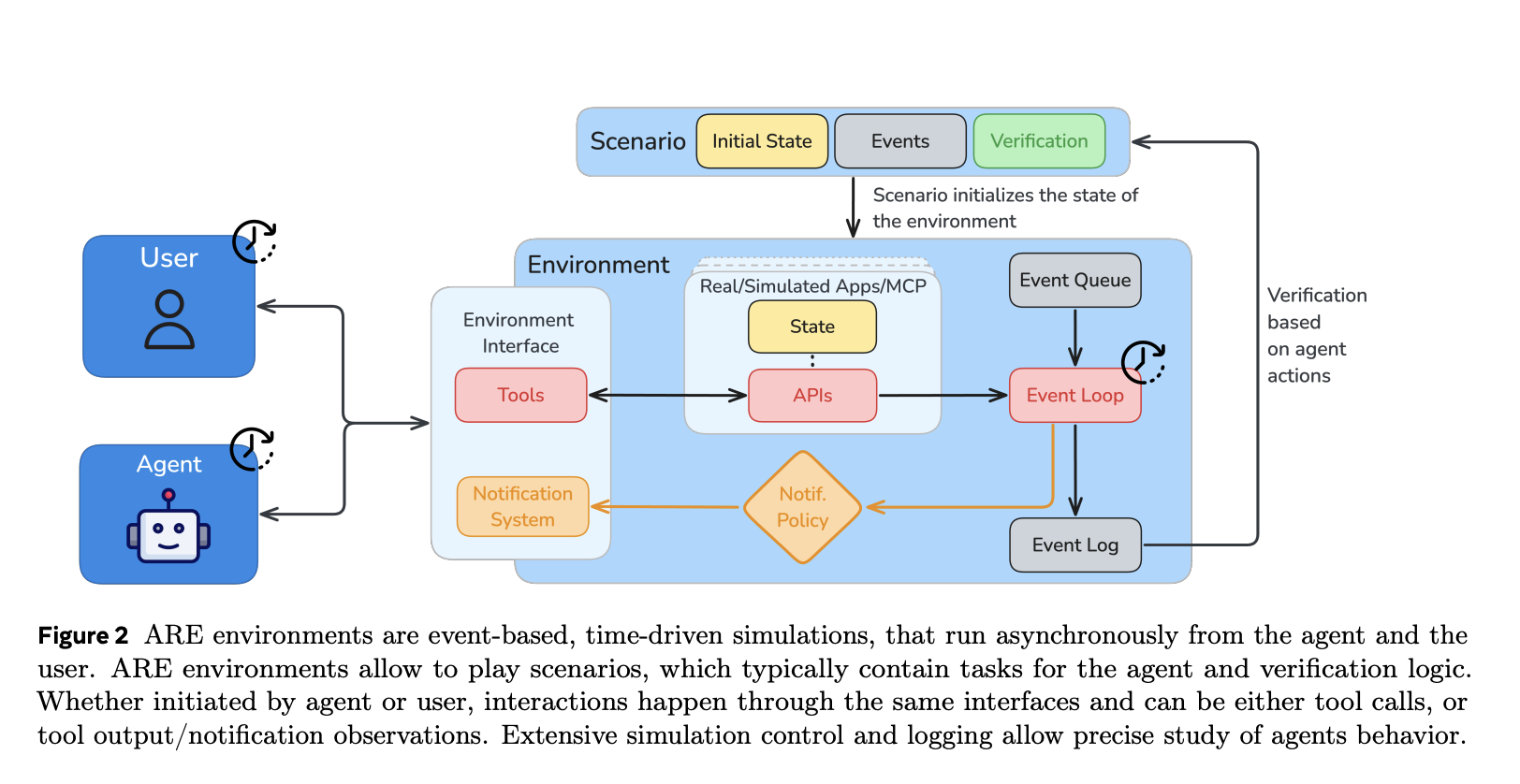
How is the ARE platform structured?
yes time driven and treat “everything as an event.” Five core concepts of organizational simulation: app (stateful tool interface), environment (a collection of applications, rules, data), Activity (record what happened), notify (configurable observability to agents), and Application scenarios (Initial state + scheduled event + validator). The tool type is read or Writecan accurately verify operations that change state. initial environment, mobilemimicking a smartphone with apps like email, messaging, and calendaring.
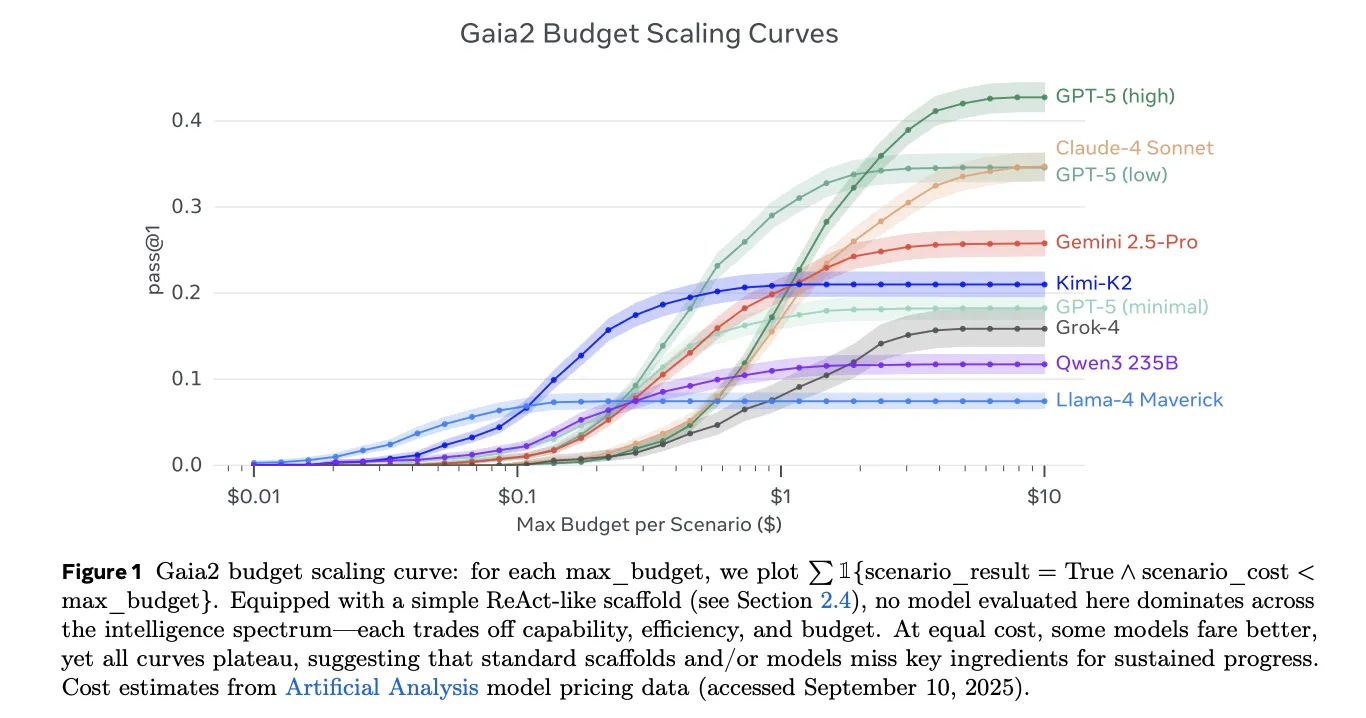
What does Gaia2 actually measure?
Gaia2’s goal is general agent capabilities under realistic pressure: Adaptability Response to and treatment of the environment Ambiguity, noise robustness, time constraints (actions within tolerances), and inter-agent collaboration (Coordinates subagents representing applications). The scene is Verifiable and reproducible Through seeds of certainty and traces of prophecy.
How big is the benchmark – 800 or 1,120 scenes?
Public data set card designation 800 scenes pass through 10 universes. References for the experimental part of the paper 1,120 verifiable, annotated scenarios in a mobile environment (reflecting the extended/enhanced configuration used in the study). Practitioners will commonly encounter the 800 scenario versions on Hugging Face, with papers showing how the suite can be expanded.
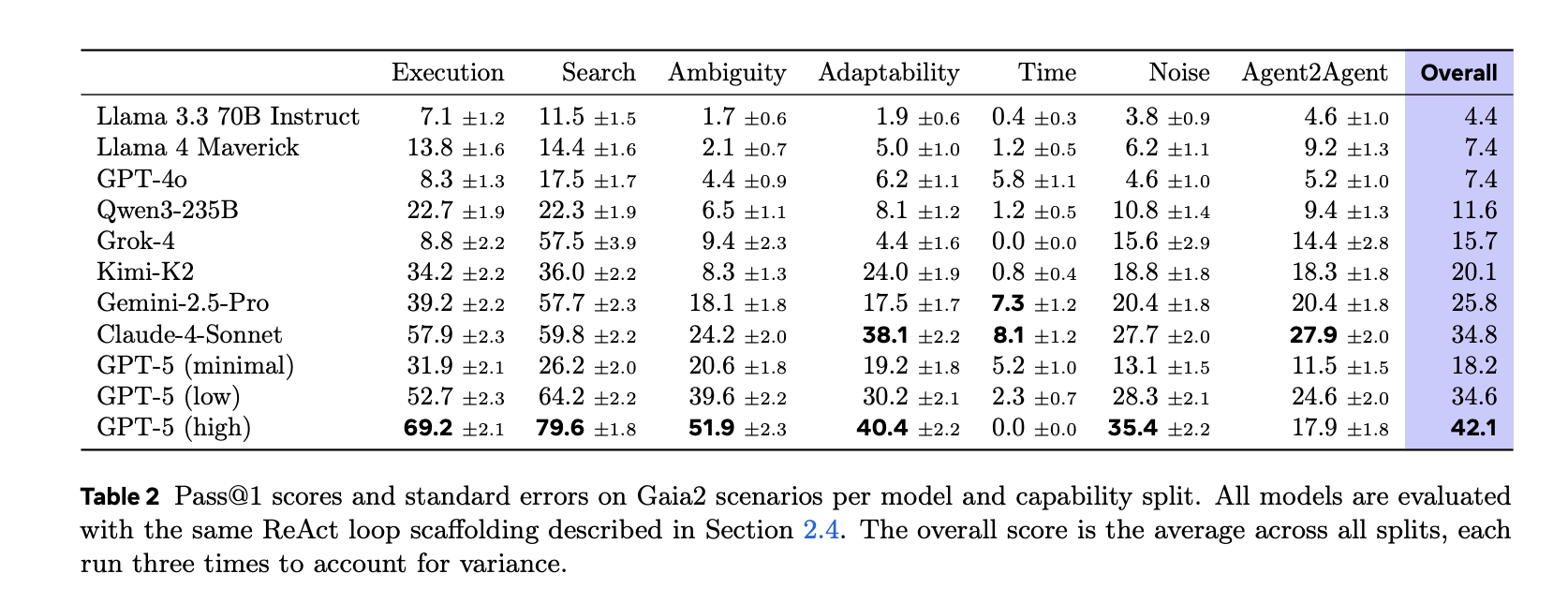
If the world is changing, how are agents rated?
Gaia 2 Assessment write sequence Opposition to Oracle Parameter level checks. Parameters passed verification difficult (accurate) or soft (LL.M. Judge) Comparison by Type, Maintenance causation and respect relative time limit. This avoids the pitfall of judging solely on the final state when many trajectories are unsafe or violate policy.
generalize
ARE + Gaia2 shifts the goal from static correctness to Correctness under change. If your agent claims to be production ready, then it should handle asynchronous, Ambiguity, noise, timingand multi-agent Coordination – and with Verifiable traces of write operations. This release offers: a controllable simulator, a challenging benchmark, and a transparent evaluation loop to emphasize real-world behavior.
Check Paper, GitHub code and Technical details.. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


