Meta AI launches DreamGym: a text experience synthesizer for reinforcement learning RL agents
Reinforcement learning RL for large language model LLM agents looks attractive on paper, but in practice it is undermined by cost, infrastructure, and reward noise. Training an agent to click on a web page or complete a multi-step tool usage can easily require tens of thousands of real interactions, each of which is slow, brittle, and difficult to reset. Meta’s new framework, DreamGym, redefines this bottleneck as a modeling problem. Rather than running RL directly in environments such as WebShop, ALFWorld, and WebArena Lite, it learns inference-based experience models and simulates them entirely in textual form.
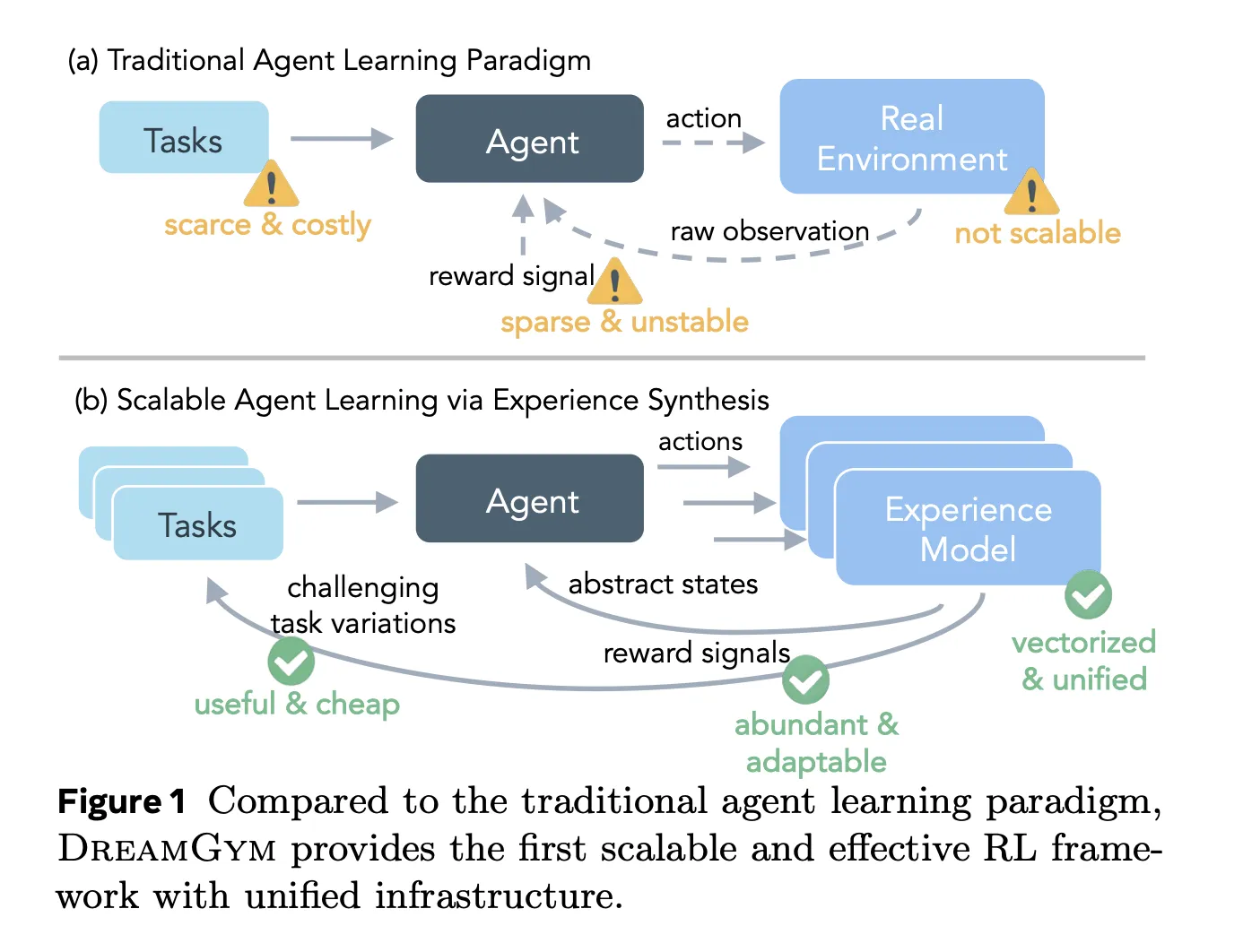
Why doesn’t real-world reinforcement learning of agents scale?
Current reinforcement learning pipelines for agents face four coupling problems. Real deployments are costly, have limited task diversity, unstable reward signals, and complex infrastructure stacks. Network environments change frequently, rewards depend on fragile crawlers, and many actions are irreversible. Reset mechanisms and event control are also difficult to implement, so long-term tasks become noisy and sample inefficient.
The benchmarks are divided into two groups. WebShop and ALFWorld are RL ready, but expensive as they still require about 80,000 real conversions to reach a strong baseline using PPO or GRPO. WebArena Lite is not RL ready at all, since resets and automatic reward checks are unreliable, so online RL in a real environment is virtually unfeasible.
DreamGym as a reasoning-based simulator
DreamGym surrounds three componentsinference-based empirical models, empirical replay buffers, and adaptive course task generators. Together they define a comprehensive Markov decision-making process in which the environment exists in the form of text.
this Inference-based empirical model medium sizeexperience value Operates in an abstract textual state space. The status is a concise description of what’s important for the task, such as cleaned page elements rather than raw HTML. At each step, the agent provides current status, actions, task instructions, and interaction history. The system retrieves the top k similar past transitions from the replay buffer and then uses thought chain reasoning to generate the inference trajectory, next state, and reward.
Conceptually, you can look at Mexperience value A model of the LLM world as a network and tool task, but defined purely through text. It is trained by supervised fine-tuning of offline trajectories, with the common goal of learning to generate inference trajectories and next states conditioned on that trajectory. This forces the model to encode causal structures rather than just local textual statistics.
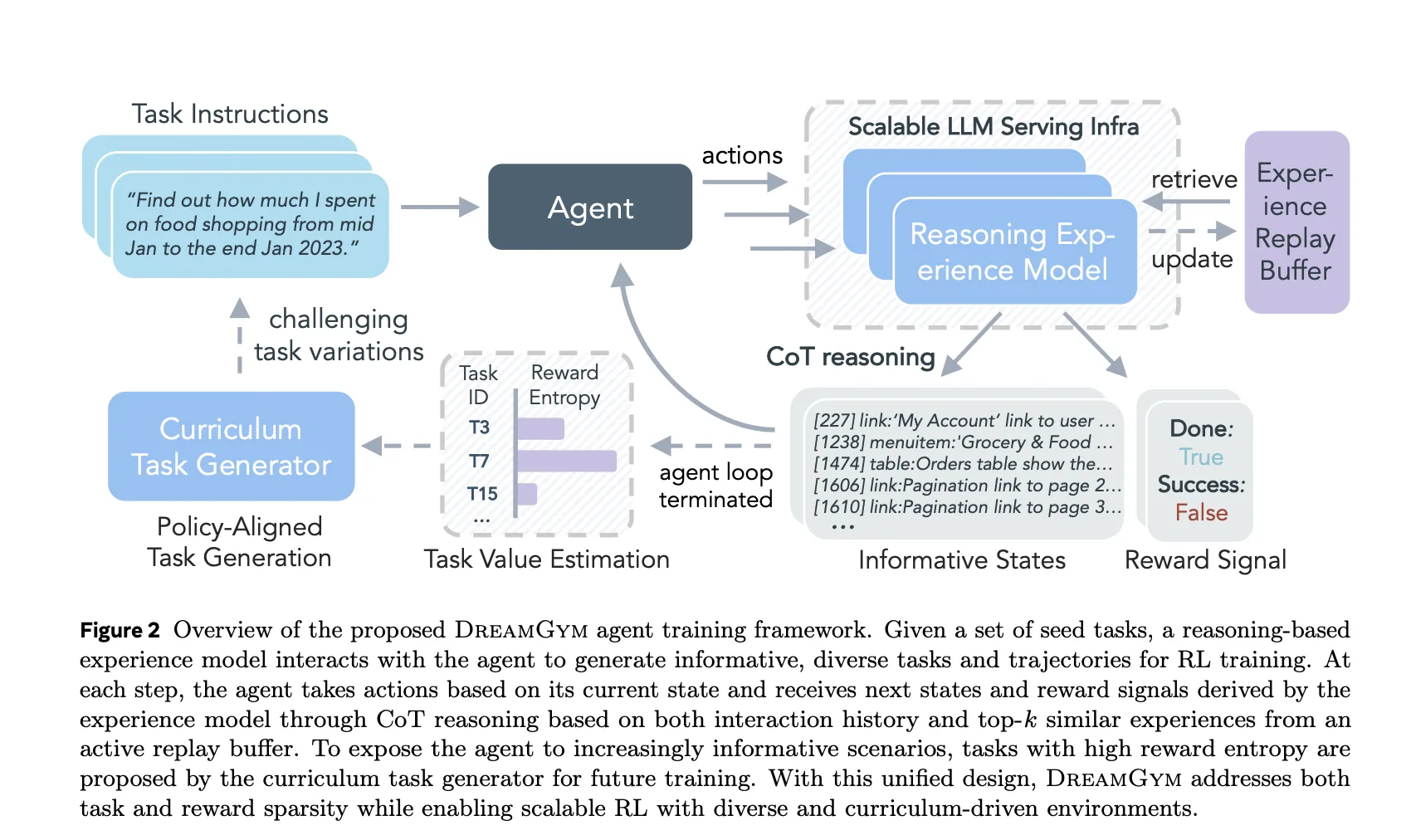
Replay buffer as underlying memory
this Experience replay buffer Initialized using offline real-world data from WebShop, ALFWorld and WebArena Lite. When DreamGym trains the policy in the synthetic environment, it writes new trajectories back to the buffer. Each prediction step in Mexperience value When generating inferences and next states, an encoder is used to retrieve a small set of similar transitions and their conditions from this memory.
This search plays a fundamental role. It brings synthetic transformations close to empirical data distributions and reduces hallucinations in long-term deployments. The research team shows that removing history or retrieval reduces the consistency, informativeness, and authenticity of generated states when judged by external evaluators, and also reduces downstream success rates on WebShop and WebArena Lite.
Lessons that reward entropy
this Course task generator Use the same backbone as the experience model. It selects seed tasks whose outcomes have high reward variance under the current policy, which corresponds to moderately difficult tasks that the agent sometimes solves and sometimes fails. For each such task, the model generates variants that retain the action type but change the constraints, goals, or context.
The selection heuristic is based on the reward entropy calculated for batch deployment of each task. Tasks with non-zero variance and a balance of success and failure are preferred. Ablation shows that turning off this adaptive class degrades WebShop and WebArena Lite performance by approximately 6 percentage points and causes an early plateau as the replay buffer becomes saturated with simple, low-entropy trajectories.

RL and theoretical guarantees within DreamGym
Internally within DreamGym, this strategy uses standard RL algorithms. The research team evaluated proximal policy optimization and group-relative policy optimization. Rollout alternates between policy selection operations and an experience model that synthesizes next states and rewards. From the perspective of the RL code, this is just another environment interface.
The research team also derived trust domain-style refinement bounds to link policy performance in a comprehensive MDP to policy performance in real environments. This bound contains an error term that depends on the reward prediction error and the difference between the real and synthetic transition distributions. As these errors are reduced, improvements in DreamGym mean improvements in the underlying practical tasks.
Experimental results on WebShop, ALFWorld and WebArena Lite
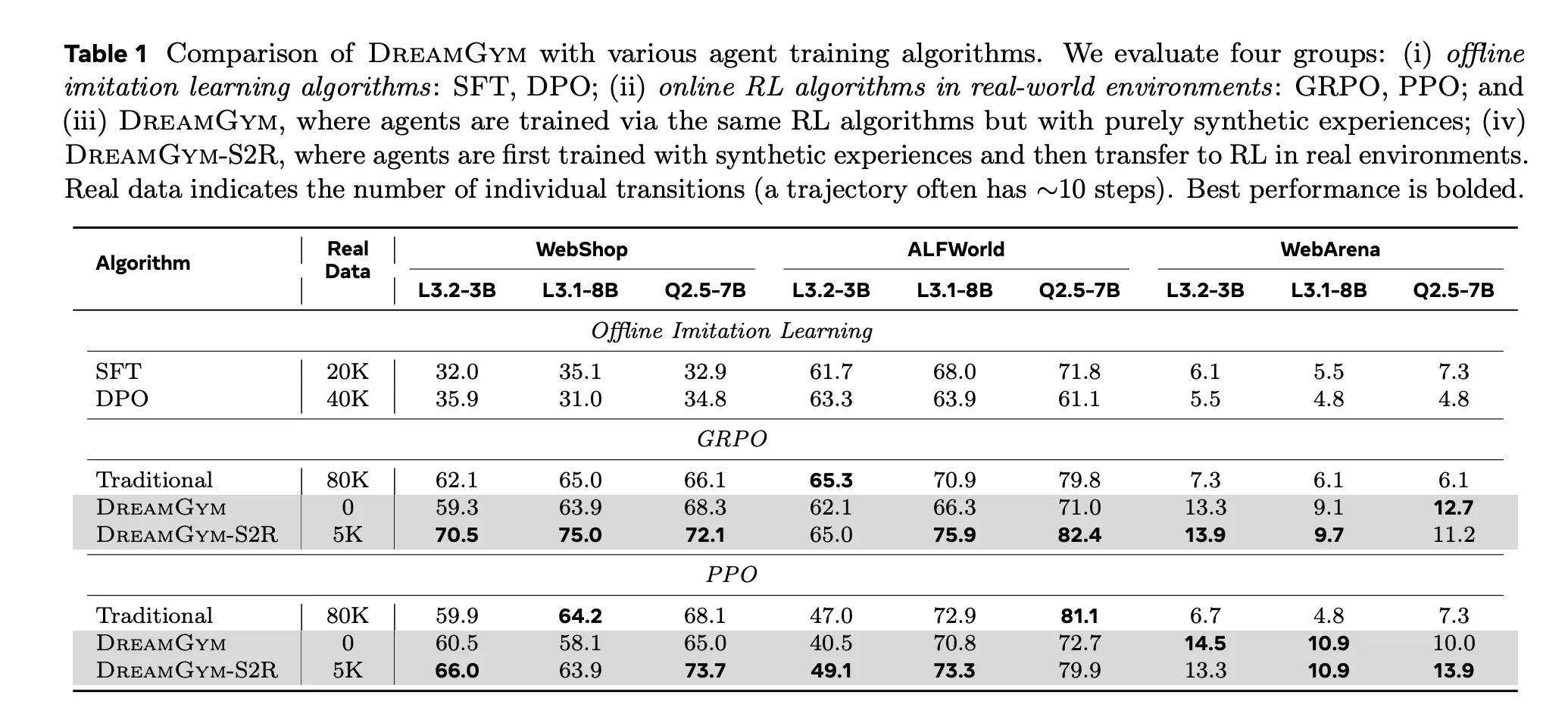
DreamGym was tested on WebShop, ALFWorld and WebArena Lite using Llama and Qwen based proxies. The results are divided into three situations.
firstexist Reinforcement learning-ready but expensive environment WebShop and ALFWorld are agents trained within DreamGym using PPO or GRPO, using only synthetic transformations, matching the performance of the PPO and GRPO baselines using approximately 80,000 real-world interactions. This suggests that inference-based empirical synthesis can provide sufficient signals for stable policy improvements.
secondexist An environment not ready for reinforcement learning For example, WebArena Lite and DreamGym can realize reinforcement learning training that would otherwise be unrealistic. The framework achieves more than 30% improvement in success rate compared to all baselines, including supervised fine-tuning and direct behavioral cloning.
thirdexist Simulated to real transferthe DreamGym-S2R configuration first trains the policy entirely on a synthetic environment and then fine-tunes it with a small number of real-world deployments. Compared to training from scratch in a real environment, this setup delivers over 40% additional gains while using less than 10% of the real data and cutting the total training cost to approximately one-third to one-fifth of the baseline.
Main points
- DreamGym replaces fragile real-world environments with an inference-based experience model that operates in an abstract textual state space, predicting next states and rewards from history, tasks, and similar transitions retrieved.
- The framework combines 3 components: an inference experience model, an experience replay buffer seeded with real trajectories, and a course task generator that uses the reward entropy heuristic to select and change tasks, which together stabilize and diversify RL training.
- In WebShop and ALFWorld, which are RL-ready but expensive, agents trained entirely within DreamGym using synthetic interactions for PPO or GRPO matched the performance of the PPO and GRPO baselines using approximately 80,000 real-world transformations.
- In WebArena Lite, which is not yet RL ready, DreamGym supports online RL and achieves over 30% higher success rates than all non-RL baselines, including supervised fine-tuning and behavioral cloning.
- In a simulation-to-real configuration, policies pretrained in DreamGym and then fine-tuned with a small number of real-world deployments can achieve over 40% additional improvement while using less than 10% of the real-world interaction budget and reducing the total training cost to about one-third to one-fifth of standard reinforcement learning.
DreamGym is an important step toward practical reinforcement learning for LLM agents, as it restructures the environment into an inference-based experience model, based on experience replay buffers and reward entropy-driven lessons, rather than a brittle browser stack. Reported gains from WebArena Lite, WebShop and ALFWorld with PPO and GRPO indicate that combined experience plus Sim to Real adaptation can become a standard model for large-scale agent training. Overall, DreamGym uses experience models (rather than policies) as the primary lever for scaling RL agents.
Check full text. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


