Memory R1: Enhancement Learning How to Enhance LLM Memory Proxy
Large Language Models (LLM) are now at the center of countless AI breakthroughs – chatbots, coding assistants, Q&A, creative writing, and more. But despite their talents, they still Stateless: Every query arrives, no memory of the past. They’re fixed Context window Meaning they cannot accumulate continuous knowledge during long conversations or multi-course tasks, and they have difficulty in inferring complex history. Recent solutions such as retrieval-generating generation (RAG) append past information to the prompts, but this often results in noisy, unfiltered environments – filling the model with too many irrelevant details or lack of critical facts.
Researchers from the University of Munich, University of Munich, University of Cambridge and University of Hong Kong have introduced Memory R1a framework for teaching LLM agents to decide what to remember and how to use it. Its LLM agents learned Actively manage and utilize external memory– When answering questions, please introduce what to add, update, delete or ignore and filter for noise. breakthrough? It uses Strengthening Learning (RL)only results-based rewards are used, so minimal supervision is required and Across models and tasks.
But why LLM struggles in memory?
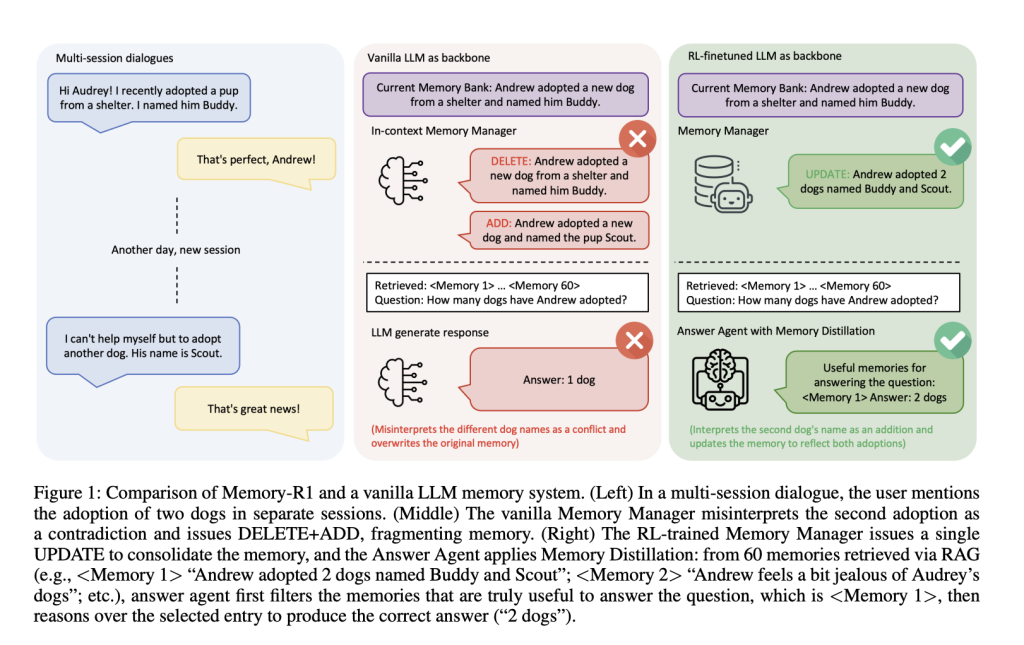
Imagine a multi-section conversation: In the first session, the user said, “I adopted a dog named Buddy.” Later, they added, “I adopted another dog named Scout.” It should be a system replace The second statement merge They, or neglect renew? Vanilla memory pipes often fail – they may delete “friends” and add “scouts”, misunderstanding new information as conflict rather than merge. Over time, this system loses coherence and destroys user knowledge rather than continues to evolve.
Rag system Retrieve information, but don’t filter: irrelevant entries pollute the reasoning, and the model is distracted by noise. HumanBy comparison, retrieve, but Selectively filter What’s important is. Most AI storage systems are Stillrely on handmade heuristics to remember what, rather than learning from feedback.
Memory R1 framework
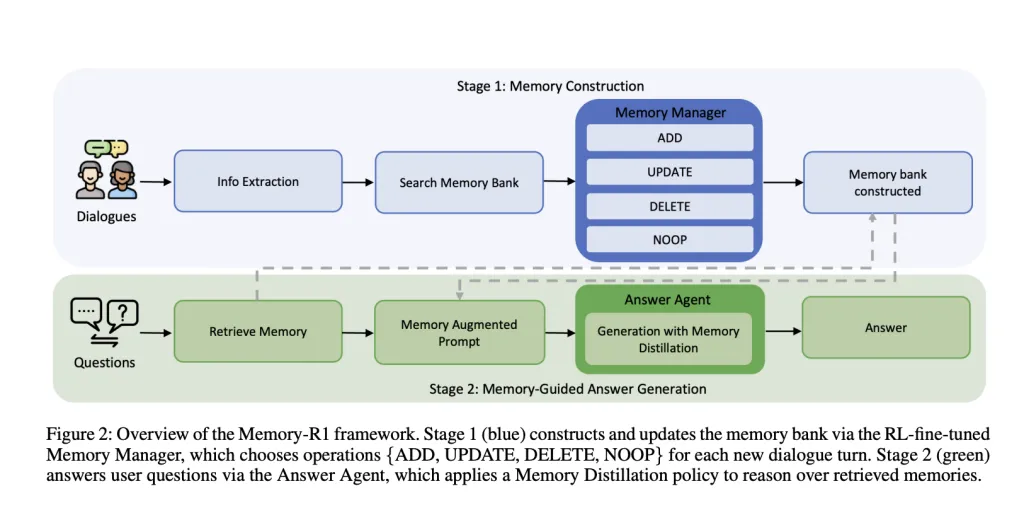
Memory r1 is around Two dedicated RL-FIN-tuning agents:
- Memory Manager: Decide which memory operations (Add to,,,,, renew,,,,, delete,,,,, No) To execute after each conversation, please update the external memory bank dynamically.
- Answer Agent: For each user question, up to 60 candidate memories are retrieved. Distillation They are the most relevant subsets and then the answer appears in this filtered context.
Both components are Receive reinforcement learning training RL– Using proximal policy optimization (PPO) or group relative policy optimization (GRPO) – Only the correctness of the question and answer is used as a reward signal. This means that agents do not need to manually tag memory operations, but learn through trial and error, optimize Final task performance.
Memory Manager: Learning Editing Knowledge
After each conversation, LLM extracts key facts. this Memory Manager Then retrieve the relevant entries from the memory bank and select an action:
- Add to: Insert new information that has not yet existed.
- renew: When blending new details into existing memory, when they specify or refine previous facts.
- delete: Delete outdated or contradictory information.
- No: If no correlation is added, leave the memory unchanged.
train: Memory manager is updated based on the answer quality generated by the answer agent from the newly edited memory bank. If memory operations enable the answer proxy to respond accurately, the memory manager will receive a positive reward. this Result-driven rewards Eliminates the need for expensive manual annotations for memory operations.
example: When the user first mentioned a dog named Buddy, later added that they adopted another dog named Scout, a vanilla system might remove “Buddy” and add “Scout” to treat it as a contradiction. However, the memory manager trained by RL renew Memory: “Andrew adopted two dogs, friends and scouts” to maintain a coherent knowledge base.
Absolute: RL fine tuning significantly improves memory management – both PPO and GRPO outperform the summary in heuristic-based managers. Systematic learning merge Instead Segmentation Knowledge.
Answer Agent: Selective Reasoning
For each problem, the system Retrieve memories of up to 60 candidates With a rag. But instead of feeding all of this to LLM, Answer Agent The first Distillation The collection – only the most relevant entries are retained. Only in this way can it produce the answer.
train: Use RL to train the answer proxy Exact match Between the answer and the golden answer as a reward. This encourages it to focus on Filter noise and Reasoning for high-quality backgrounds.
example: Q: “Does John live near the beach or near the mountains?” A vanilla LL. A MSc may output “mountains” and is affected by irrelevant memories. However, Memory-R1’s answer proxy Only surfaces only entries related to beaches Before answering, lead to the correct “beach” response.
Absolute: RL fine-tuning improves answer quality compared to static retrieval. Memory distillation (Filtering out irrelevant memories) further improves performance. The benefits are even Larger memory managershowing improvements in compound interest.
Training data efficiency
MOMEME-R1 is Data efficiency: It only passes 152 Q&A Carry out training. This is possible because the agent from resultnot from thousands of manually tagged memory operations. Minimum of supervision, the system extends to large real-world dialogue history.
this Locomotive benchmarkfor evaluation, including multi-transfer conversations (about 600 times per conversation, with an average of 26,000 tokens) and related QA pairs, spanning single-hop, multi-hop, open domain and time reasoning, for testing Longma memory management.
Experimental results
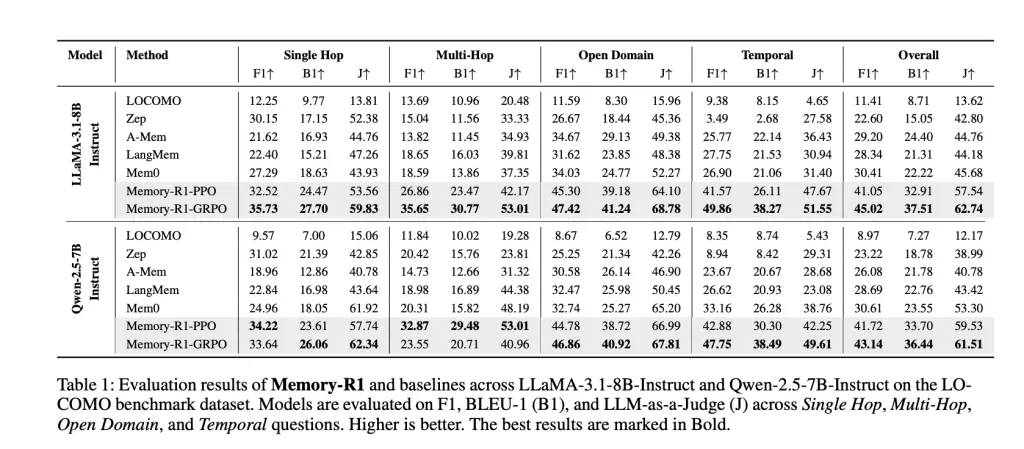
Memory-R1 is Llama-3.1-8B Teaching and QWEN-2.5-7B Teaching Backbone against competitive baselines (Locomotive, ZEP, A-MEM, Langmem, MEM0). The key indicators are:
- F1: Measuring overlap between prediction and correct answers.
- bleu-1: Capture vocabulary similarity at the umigram level.
- llm-as-aaa gudge: Use separate LLM to evaluate factual accuracy, relevance and integrity, which is a representative of human judgment.
result: MOMEMER-R1-GRPO implementation Best overall performanceMEM0 (previous best baseline) was increased by 48% in F1, 69% in BLEU-1, and 37% in Llama-3.1-8B. Similar gains can be seen on QWEN-2.5-7B. Improvements are Based on a wide range ofspanning all problem types, and Cross-model architecture overview.
Why this matters
Memory-R1 means Can learn memory management and utilization-LLM proxy does not need to rely on fragile heuristics. Through the decision of the result-driven RL, the system:
- Automatically consolidate knowledge As the conversation develops, not to disperse or cover it.
- Filter noise Improve factual accuracy and reasoning quality when answering.
- Learn effectively Almost no supervision, scales A long horse mission to the real world.
- Cross-model summarymaking it a promising foundation for next-generation proxy, memory-aware AI systems.
in conclusion
Memory R1 Unlocking the stateless limitations of LLM agents, allowing them to effectively manage and use long-term memory by strengthening their strength. Operation through architecture memory and filtered into RL problemit has achieved success The most advanced performance and Minimum supervision and Strong summary. This marks an important step forward in AI systems, not only talking fluently, but also remembering, learning and rationality, like humans, to provide users everywhere with a richer, longer lasting and more useful experience.
FAQ
FAQ 1: What makes memory R1 better than a typical LLM memory system?
Memory-R1 uses reinforcement learning to actively control memory (introduce information to add, update, delete or retain) than static heuristic-based approaches to merge with smaller fragmentation.
FAQ 2: How does memory R1 improve the quality of answers through long conversation history?
The answer agent adopts a “memory distillation” strategy: it filters up to 60 retrieved memories to show those most relevant to each question, thereby reducing noise and improving factual accuracy with just passing all contexts to the model.
FAQ 3: Is the training data of memory R1 valid?
Yes, Memory-R1 uses only 152 QA training to achieve state-of-the-art benefits, as its results-based RL reward eliminates the need for expensive manual annotations for each memory operation.
Check The paper is here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


