MEDHELM: A comprehensive medical benchmark for language models for evaluating real-world clinical tasks using actual electronic health records

Large Language Models (LLMs) are widely used in medicine, facilitating diagnostic decision-making, patient classification, clinical reporting and medical research workflows. Although they are excellent in controlled medical testing, such as the US Medical License Examination (USMLE), their practicality for real-world use has not been well tested. Most existing assessments depend on synthetic benchmarks that cannot reflect the complexity of clinical practice. In a study last year, they found that only 5% of LLM analyses relied on real-world patient information, revealing a huge difference between testing real-world availability and demonstrating their role in determining their reliability in medical decision making and therefore also questioning safety and safety used in real-world clinical settings.
The most advanced evaluation method mainly uses synthetic data sets, structured knowledge tests and regular physical examinations to score language models. Although these exams test theoretical knowledge, they do not reflect actual patients with complex interactions. Most tests produce single metric results without focusing on key details such as the correctness of facts, clinical applicability, and the possibility of response bias. Furthermore, the widely used public data sets are homogeneous, impairing generalizations of different medical professions and patient populations. Another major setback is that most models targeting these benchmarks exhibit over-fitting test paradigms and thus lose most of their performance in dynamic healthcare environments. The lack of a system-wide framework that encompasses real-world patient interactions has further eroded their confidence in practical medical uses.
The researchers developed Medhelm, an exhaustive evaluation framework designed to test LLM to prevent actual medical tasks, polynomial assessments and expert-revised benchmarks to address these gaps. It builds on Stanford’s overall assessment of the language model (Helm) and performs systematic evaluations in five major areas:
- Clinical decision-making support
- Clinical notes generated
- Patient communication and education
- Medical research help
- Management and workflow
A total of 22 subcategories and 121 specific medical tasks ensure wide coverage of critical healthcare applications. Compared with earlier criteria, MedHelm uses actual clinical data, uses structured and open task evaluation models, and applies a variety of scoring paradigms. Overall coverage allows it to measure not only the recall of knowledge, but also clinical applicability, reasoning accuracy and general daily practicality.
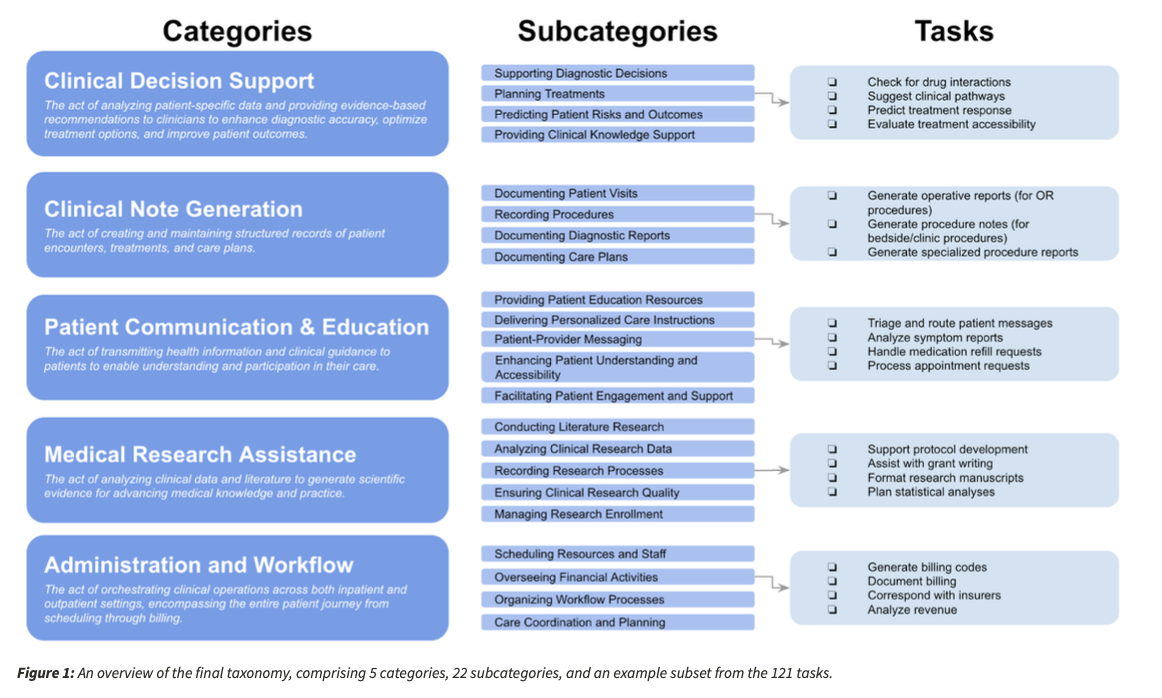
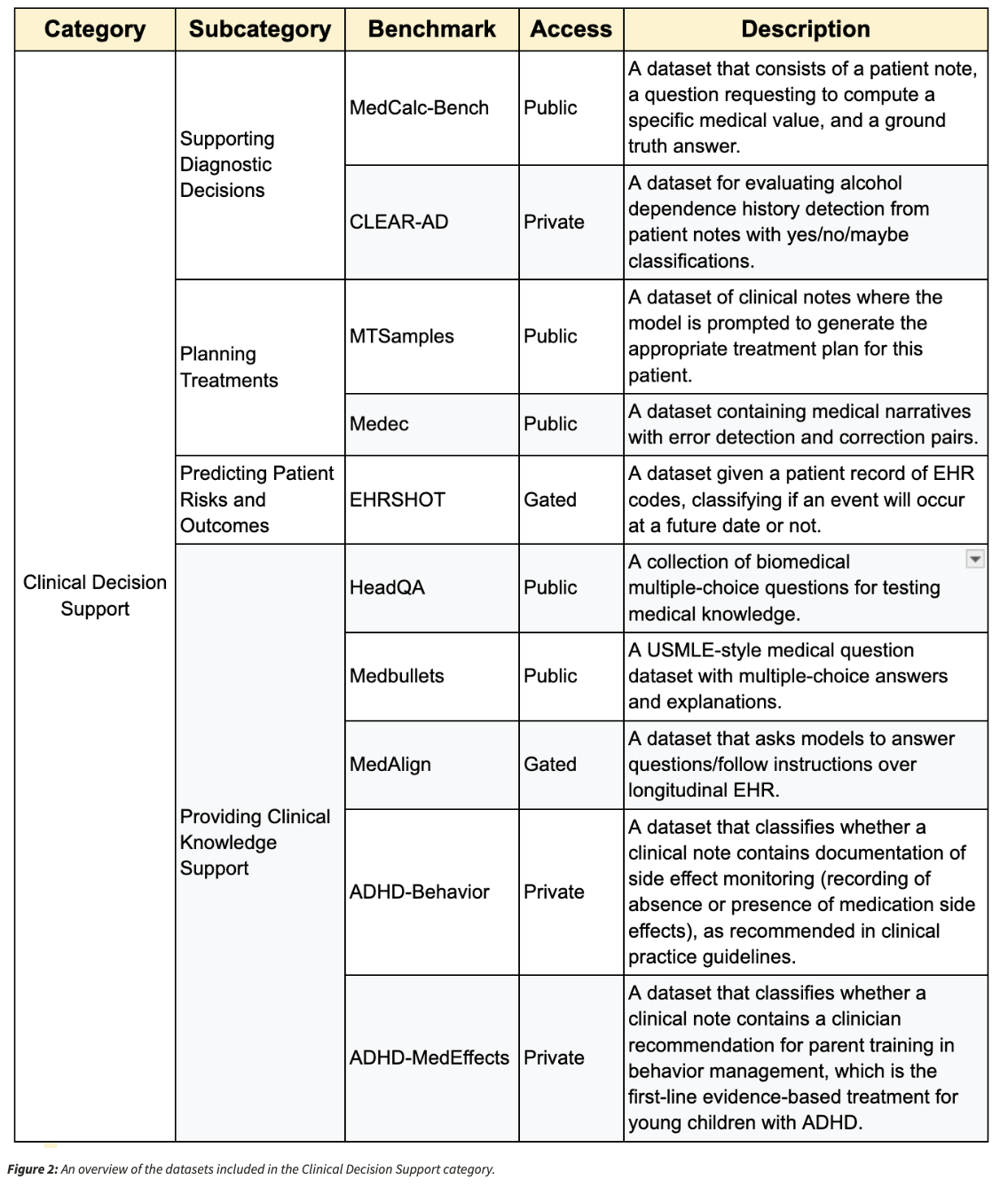
An extensive dataset infrastructure is the basis of the benchmarking process, including 31 datasets. The series includes 11 newly developed medical data sets and 20 obtained from existing clinical records. The dataset covers a variety of medical fields, ensuring that assessments accurately represent real-world medical challenges rather than artificial testing scenarios.
The conversion of data sets into standardized reference is a systematic process involving:
- Context definition: Specific data segments The model must be analyzed (e.g., clinical annotation).
- Tip strategy: A predefined guide to guide the behavior of a model (e.g., “Determine the patient’s blood sac fraction”).
- Reference Response: Compared clinically validated output (e.g., classification tags, numerical values, or text-based diagnosis).
- Scoring metrics: An exact match for text similarity assessment, classification accuracy, a combination of BLEU, ROUGE and BERTSCORE.
An example of this approach is in the Medcalc pedestal, which tests that the model is able to perform clinically important numerical calculations. Each data input contains the patient’s clinical history, diagnostic problems, and expert-verified solutions, which rigorously tests of medical reasoning and accuracy.
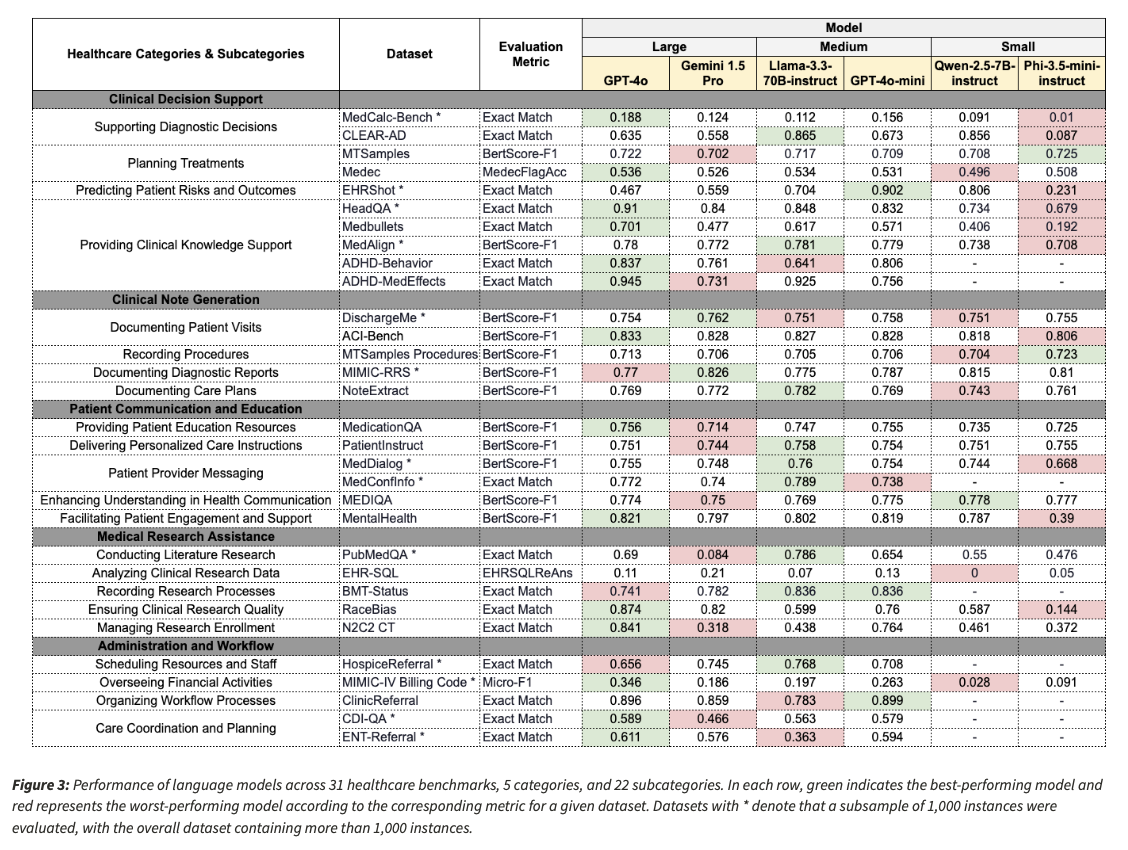
Evaluations conducted on six different sizes of LLM reveal unique advantages and disadvantages based on task complexity. Large models such as GPT-4O and Gemini 1.5 Pro perform well in medical reasoning and computing tasks, and show improved accuracy in tasks such as clinical risk estimation and bias recognition. Medium-sized models such as Llama-3.3-70B teaching are performed competitively in predictive health care tasks, such as hospital readmission risk prediction. Small models such as PHI-3.5-MINI-Instruct and Qwen-2.5-7b-Instruct performed poorly in field-intensive knowledge testing, especially in mental health counseling and advanced medical diagnosis.
In addition to accuracy, the response compliance to structured problems is also different. Some models do not answer medically sensitive questions, nor answer in the required format, but at the expense of their overall performance. The test also found disadvantages of current automatic metrics, as the conventional NLP scoring mechanism tends to ignore actual clinical accuracy. In most benchmarks, performance differences between models are still negligible when using BertScore-F1 as a metric, suggesting that current automated evaluation procedures may not fully capture clinical availability. The results highlight the need for a stricter assessment procedure that includes fact-based scores and clear clinician feedback to ensure reliability in the assessment.
With the advent of a clinically-guided polynomial assessment framework, Medhelm provides a holistic and trustworthy approach to assessing language models in the healthcare field. Its approach ensures that LLM can be evaluated based on actual clinical tasks, organized reasoning tests and various data sets, rather than manual testing or truncated benchmarks. Its main contributions are:
- Structural taxonomy of 121 real-life medical tasks improves the scope of AI assessment in clinical settings.
- Use real patient data to enhance model evaluation beyond theoretical knowledge tests.
- Strictly evaluate six state-of-the-art LLMs to identify the strengths and areas that need improvement.
- Call for improvements in assessment methods, emphasizing fact-based scoring, operability adjustments and direct clinician validation.
Subsequent research efforts will focus on MEDHELM improvements by introducing more specialized data sets, simplifying the evaluation process, and implementing direct feedback from healthcare professionals. Overcoming the significant limitations of AI evaluation, the framework lays a solid foundation for the safe, effective and clinically relevant integration of large language models with contemporary healthcare systems.
Check Complete rankings, details and GitHub page. All credits for this study are to the researchers on the project. Also, please keep an eye on us twitter And don’t forget to join us 80k+ ml subcolumn count.
 Recommended Reading – LG AI Research Unleashes Nexus: An Advanced System Integration Agent AI Systems and Data Compliance Standards to Address Legal Issues in AI Datasets
Recommended Reading – LG AI Research Unleashes Nexus: An Advanced System Integration Agent AI Systems and Data Compliance Standards to Address Legal Issues in AI Datasets
MEDHELM: A comprehensive health care benchmark for linguistic models for evaluating real-world clinical tasks using actual electronic health records, first appeared on Marktechpost.


