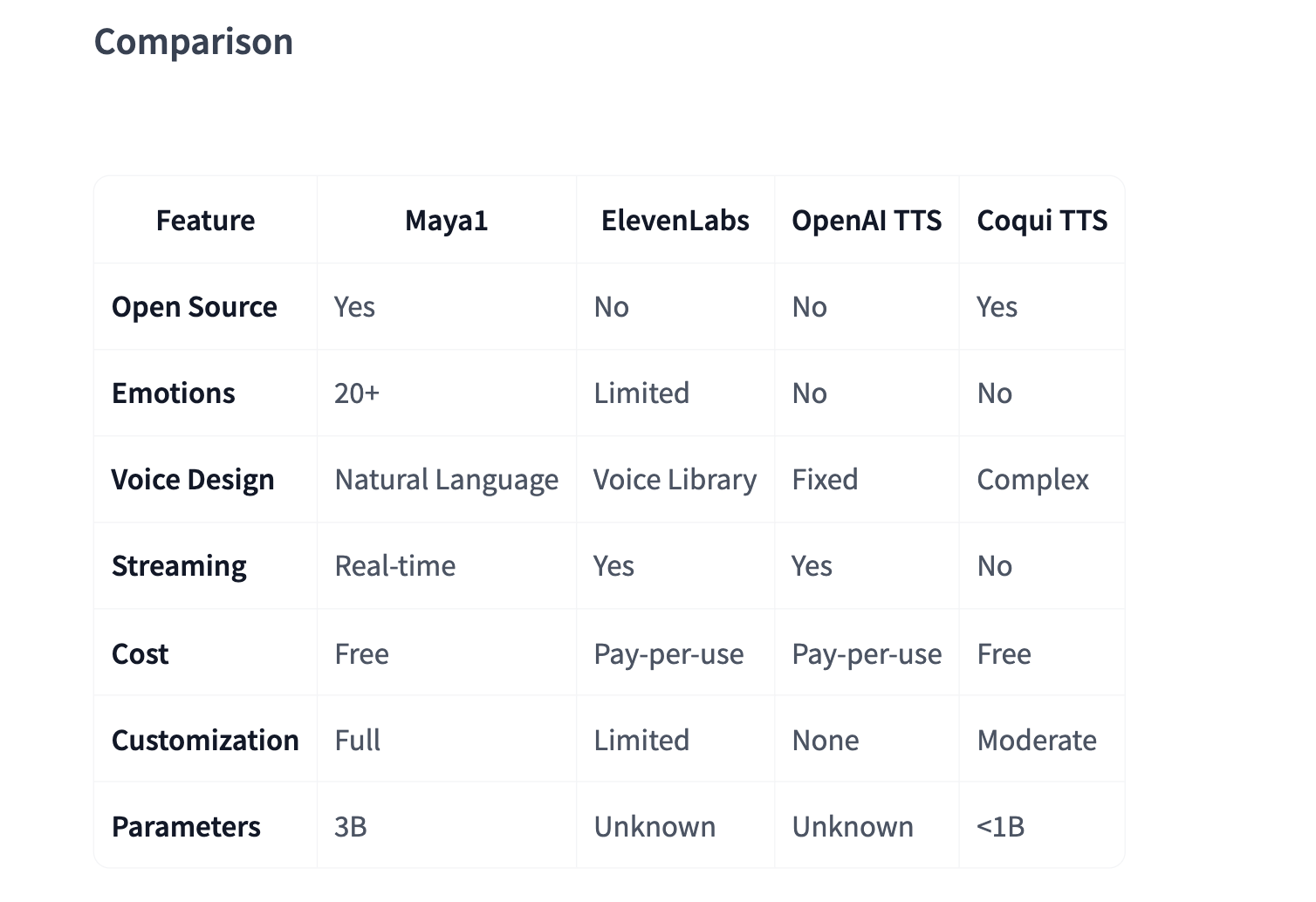
Maya1: A new open source 3B speech model enables expressive text-to-speech on a single GPU
Maya Research has released Maya1, a 3B parametric text-to-speech model that converts text plus short descriptions into controllable, expressive speech while running in real time on a single GPU.
Maya1 in action?
Maya1 is the state-of-the-art speech model for generating expressive speech. It is designed to capture real human emotions and precise voice design from text input.
The core interface has 2 inputs:
- Voice description in natural language, such as “female voice in her 20s, British accent, energetic, clear pronunciation” or “devil character, male voice, low pitch, hoarse timbre, slow rhythm”.
- words that should be said
The model combines the two signals and generates audio that matches the content and style being described. You can also insert inline sentiment tags into the text, e.g.
Maya1 outputs 24 kHz mono audio and supports live streaming, making it suitable for assistants, interactive agents, games, podcasts, and real-time content.
The Maya research team claims the model outperforms top proprietary systems while remaining fully open source under the Apache 2.0 license.
Architecture and SNAC codec
Maya1 is a 3B parametric decoder transformer with only Llama style backbone. Instead of predicting raw waveforms, it predicts markers from a neural audio codec called SNAC.
The power generation process is
text → tokenize → generate SNAC codes (7 tokens per frame) → decode → 24 kHz audio
SNAC uses multi-scale hierarchical structures at approximately 12, 23 and 47 Hz. This keeps the autoregressive sequence compact while preserving detail. This codec is designed for live streaming at approximately 0.98 kbps.
The important point is that the transformer operates on discrete codec tokens rather than raw samples. For example, a separate SNAC decoder hubertsiuzdak/snac_24khzreconstruct the waveform. This separation makes the generation more efficient and easier to scale than direct waveform prediction.
Training data and speech conditioning
Maya1 is pre-trained on an internet-scale corpus of English speech to learn broad acoustic coverage and natural pronunciation. It is then fine-tuned based on a carefully curated proprietary dataset of studio recordings, which includes human-verified voice descriptions, more than 20 emotion labels per sample, multiple English accents, and personas or character variations.
The recorded data pipeline includes:
- 24 kHz mono resampling, loudness is approximately minus 23 LUFS
- Voice activity detection and silence trimming between 1 and 14 seconds
- Force alignment to phrase boundaries using Montreal force aligner
- MinHash LSH text deduplication
- Audio deduplication based on Chromaprint
- SNAC encoding using 7 token frames
The Maya research team evaluated several ways to tune the model based on phonetic descriptions. Simple colon formats and key-value tag formats either cause the model to speak descriptively or not generalize well. The best performing formats use XML style attribute wrappers to encode descriptions and text in a natural way while maintaining robustness.
In practice, this means developers can describe sounds in free-form text, similar to how they would describe a voice actor, rather than learning a custom parameter pattern.
Inference and deployment on a single GPU
The reference Python script on Hugging Face loads the model using the following command AutoModelForCausalLM.from_pretrained("maya-research/maya1", torch_dtype=torch.bfloat16, device_map="auto") and use the SNAC decoder SNAC.from_pretrained("hubertsiuzdak/snac_24khz").
The Maya research team recommends using a single GPU with 16 GB or more of VRAM, such as the A100, H100, or consumer RTX 4090-class card.
For production they offer vllm_streaming_inference.py Scripts to integrate with vLLM. It supports automatic prefix caching of repeated speech descriptions, WebAudio ring buffers, multi-GPU scaling, and sub-100ms latency targets for real-time use.
In addition to the core repository, they also released:
- Embracing Facespace, showing off an interactive browser demo where users can enter text and voice descriptions and listen to the output
- GGUF quantizes a variant of Maya1 for more lightweight deployment, using
llama.cpp - ComfyUI node wrapping Maya1 as a single node, with emotion tag helper and SNAC integration
These projects reuse official model weights and interfaces so they are consistent with the main implementation.
Main points
- Maya1 is a 3B parameter, decoder-only, Llama-style text-to-speech model that predicts SNAC neural codec signatures instead of raw waveforms and outputs 24 kHz mono audio with streaming support.
- The model takes 2 inputs, natural language speech description and target text, and supports more than 20 inline emotion labels, e.g.
- Maya1 is trained using a pipeline that combines large-scale English pre-training and studio-quality fine-tuning with loudness normalization, voice activity detection, forced alignment, text deduplication, audio deduplication, and SNAC encoding.
- The reference implementation runs on a single 16GB+ GPU using
torch_dtype=torch.bfloat16integrates with the SNAC decoder and has a vLLM-based streaming server with automatic prefix caching for low-latency deployment. - Maya1 is released under the Apache 2.0 license with official weights, Hugging Face Space demos, GGUF quantization variants and ComfyUI integration, which makes expressive, emotive, and controllable text-to-speech available for commercial and local use.
Maya1 pushes open source text-to-speech into a space previously dominated by proprietary APIs. The 3B parameter Llama style decoder predicts SNAC codec tokens, runs on a single 16 GB GPU with vLLM streaming and automatic prefix caching, and exposes over 20 inline emotions via natural language speech design, making it a practical building block for real-time agents, games, and tools. Overall, Maya1 demonstrates that expressive, controllable TTS can be both open and production-ready.
Check Model weight and Demo. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


