LongCat-Flash-Omni: SOTA open source full-modal model, 560B parameters, 27B activation, good at real-time audio-visual interaction
How to design a single model that can listen, see, read and respond in real time across text, images, video and audio without losing efficiency? Released by Meituan My Neighbor Totoro Team Changmao Flash Omnian open source full-modal model with 560 billion parameters and approximately 27 billion actives per token, built on the quick connection expert hybrid design launched by LongCat Flash. The model extends the text backbone to visual, video, and audio and preserves 128K context, so it can run long conversations and document-level understanding in a single stack.
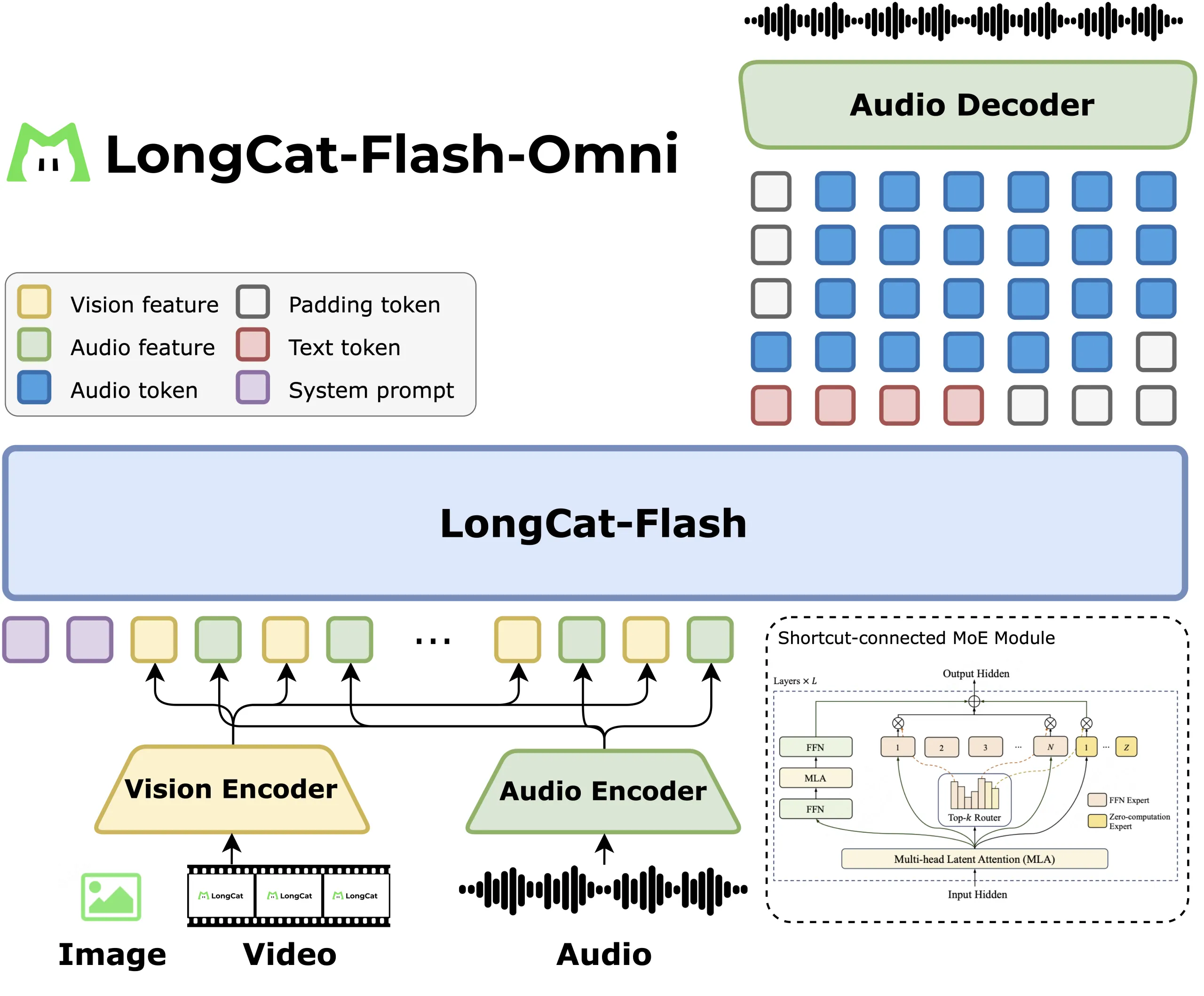
Schema and modal attachments
LongCat Flash Omni keeps the language model unchanged and then adds the perception module. The LongCat ViT encoder processes images and video frames simultaneously, so there are no separate video towers. The audio encoder, together with the LongCat audio codec, converts speech into discrete tokens, and the decoder can then output the speech from the same LLM stream, enabling real-time audio-visual interaction.
Streaming and functionality intertwined
The research team describes chunked audiovisual feature interleaving, where audio features, video features, and timestamps are packed into 1-second segments. Videos are sampled at 2 frames per second by default and then adjust the rate based on the length of the video. The report does not tie the sampling rules to user or model speaking phases, so the correct description is duration conditional sampling. This keeps latency low and still provides spatial context for GUI, OCR, and video QA tasks.
Courses range from text to comprehensive
Training follows a staged curriculum. The research team first trained the LongCat Flash text backbone, each token activated 18.6B to 31.3B parameters, with an average of 27B, then applied text-to-speech continuous pre-training, and then used images and videos for multi-modal continuous pre-training, then the context was extended to 128K, and then the audio encoder was aligned.
System design, modal decoupling parallelism
Since the encoder and LLM have different computing modes, Meituan uses modal decoupling parallelism. The visual and audio encoders run with hybrid sharding and activation recomputation, LLM runs in parallel with pipelines, contexts and experts, and ModalityBridge aligns embeddings and gradients. The research team reports that multimodal supervised fine-tuning maintains more than 90% of the throughput of plain text training, which is the main system result of this release.
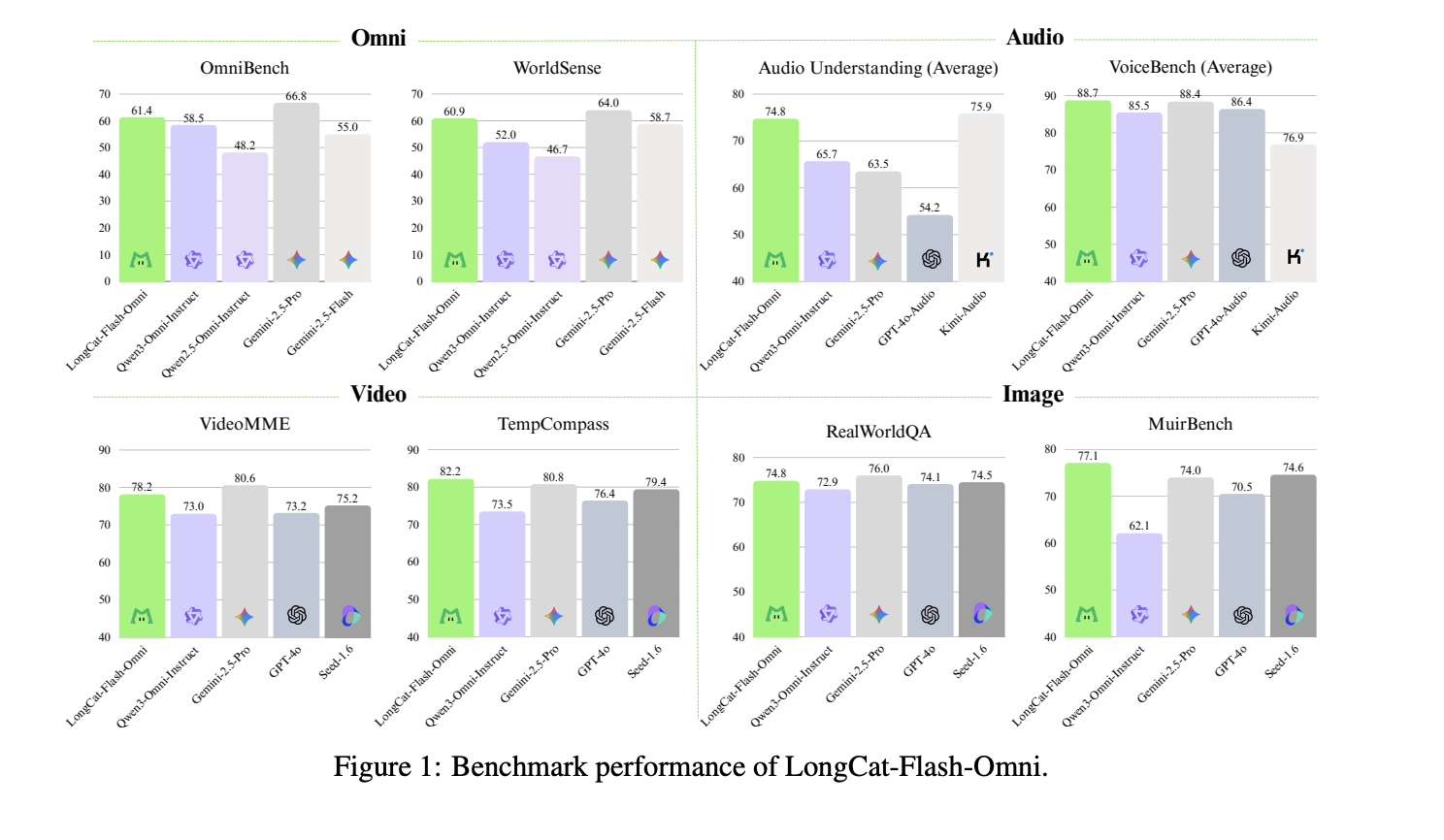
datum and positioning
The LongCat Flash Omni reached 61.4 on OmniBench, which is higher than the Qwen 3 Omni Instruct’s 58.5 and the Qwen 2.5 Omni’s 55.0, but lower than the Gemini 2.5 Pro’s 66.8. On VideoMME it scores 78.2, close to GPT 4o and Gemini 2.5 Flash, and on VoiceBench it reaches 88.7, slightly higher than GPT 4o Audio in the same table.
Main points
- LongCat Flash Omni is an open source full-modal model based on Meituan’s 560B MoE backbone, which activates about 27B parameters per token through the shortcut MoE of zero computing experts, so it maintains high-capacity but inference-friendly calculations.
- This model attaches a unified visual video encoding and streaming audio path to the existing LongCat Flash LLM, uses 2 fps default video sampling and duration scaling adjustments, and packages audiovisual functions into 1 second chunks for simultaneous decoding, enabling any real-time interaction.
- The LongCat Flash Omni scored 61.4 on OmniBench, which is higher than the Qwen 3 Omni Instruct’s 58.5, but lower than the Gemini 2.5 Pro’s 66.8.
- Meituan uses modal decoupling parallelism, with visual and audio encoders running in hybrid sharding, and LLM running in pipeline, context, and expert parallelism, and reports over 90% text-only throughput for multimodal SFT, which is the main system contribution of this release.
This release shows that Meituan is working hard to make full-modal interaction practical rather than experimental. It keeps the 560B Shortcut-connected Mixture of Experts active with 27B, so the language backbone remains compatible with earlier LongCat versions. It increases the visual perception of streaming audio with 2 fps default video sampling and duration adjustment adjustments so latency remains low without losing spatial grounding. It reports over 90% text-only throughput in multi-modal supervised fine-tuning via modal decoupling parallelism.
Check Paper and model weight and GitHub repository. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.

: Practical voice AI tools built into the real world")
