Learn about OpenTSLM: A family of time series language models (TSLM) revolutionizing medical time series analysis
Major developments are about to change Artificial Intelligence in Healthcare. Researchers are at Stanford Universityin partnership with ETH Zurich and technology leaders including google research and Amazon have launched OpenTSLMa novel family of time series language models (TSLM).
This breakthrough addresses a key limitation of current LL.M.s, allowing them to explain and reason about complex, sequential issues. Medical time series datasuch as electrocardiogram, electroencephalogram, and wearable sensor streams, a feat that even cutting-edge models like GPT-4o struggle to achieve.
Critical Blind Spot: Limitations of the LL.M. in Time Series Analysis
Medicine is fundamentally temporary. Accurate diagnosis relies heavily on tracking the evolution of vital signs, biomarkers, and complex signals. Despite the spread digital health technologytoday’s most advanced artificial intelligence models have struggled to process this raw continuous data.
The core challenge lies in the “modal gap,” the difference between a continuous signal (such as a heartbeat) and the discrete textual tokens that the LLM understands. Previous attempts to bridge this gap by converting signals into text have proven inefficient and difficult to scale.
Why visual language models (VLM) fail when processing time series data
A common solution is to convert time series data into static images (line plots) and feed them into a high-level visual language model (VLM). However, OpenTSLM research shows that this approach is surprisingly ineffective for accurate calculations. Medical data analysis.
VLMs are primarily trained on natural photos; they recognize objects and scenes rather than the dense, continuous dynamics of data visualizations. When high-frequency signals such as electrocardiograms are rendered into pixels, critical fine-grained information is lost. Subtle time-dependence and high-frequency changes that are critical for identifying cardiac arrhythmias or specific sleep stages are obscured.
This study confirms that VLM encounters significant difficulties in analyzing these plots, emphasizing that time series must be viewed as a unique data pattern and not just a picture.
Introduction to OpenTSLM: Native Modal Approaches
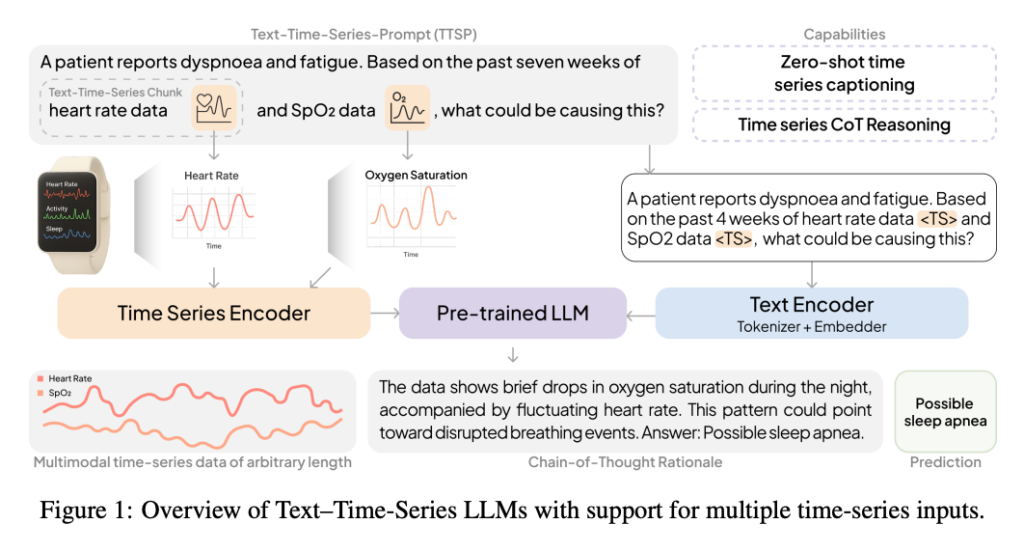
OpenTSLM integrates time series into local modality Direct entry into pre-trained LLMs (such as Llama and Gemma) to enable natural language querying and reasoning on complex health data.
The research team explored two different architectures:
Architecture Deep Dive: SoftPrompt and Flamingo
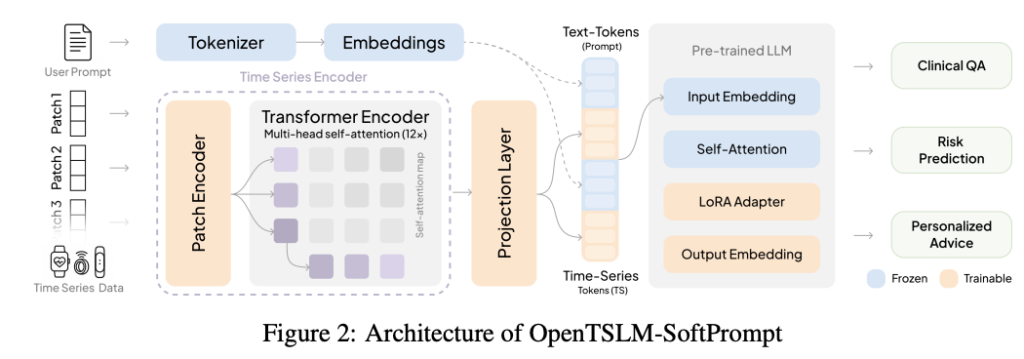
1.OpenTSLM-SoftPrompt (implicit modeling)
This approach encodes time series data into learnable markers, which are then combined with text markers (soft cues). While this approach is effective for short bursts of data, it scales poorly. Longer sequences require exponentially more memory, making comprehensive analysis impractical.
2.OpenTSLM-Flamingo (explicit modeling)
Inspired by the Flamingo architecture, this is a breakthrough solution for scalability. It explicitly models time series as separate modalities. It uses specialized encoders and perceptron resamplers to create a fixed-size representation of the data (regardless of its length) and fuses it with the text using: Gated cross-attention.
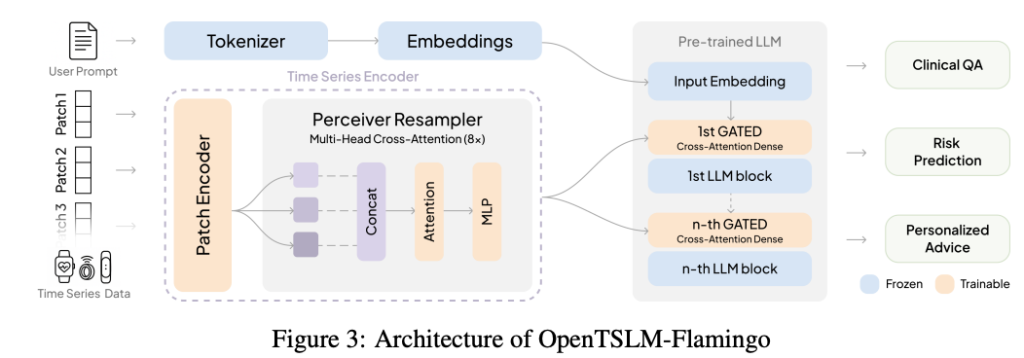
OpenTSLM-Flamingo maintains stable memory requirements even with large data streams. For example, in a complex training process ECG data analysisthe Flamingo variant requires only 40 GB VRAM, while the SoftPrompt variant using the same LLM backbone requires 110 GB.
Performance breakthrough: beyond GPT-4o
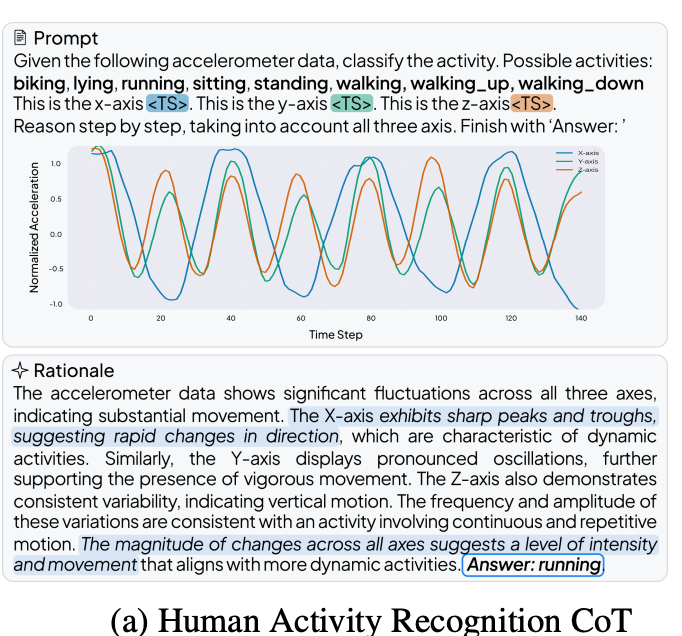
The results demonstrate the clear superiority of the specialized TSLM approach. To benchmark performance, the team created three new chain-of-thought (CoT) datasets focused on medical reasoning: HAR-CoT (activity recognition), Sleep-CoT (electroencephalogram sleep staging), and ECG-QA-CoT (electrocardiogram question answering).
- Sleep stages: OpenTSLM achieved an F1 score of 69.9%, far exceeding the best fine-tuned text-only baseline (9.05%).
- Activity recognition: OpenTSLM reaches 65.4% F1 score
This is an example of human activity recognition COT.
Here is an example of sleep activity detection:
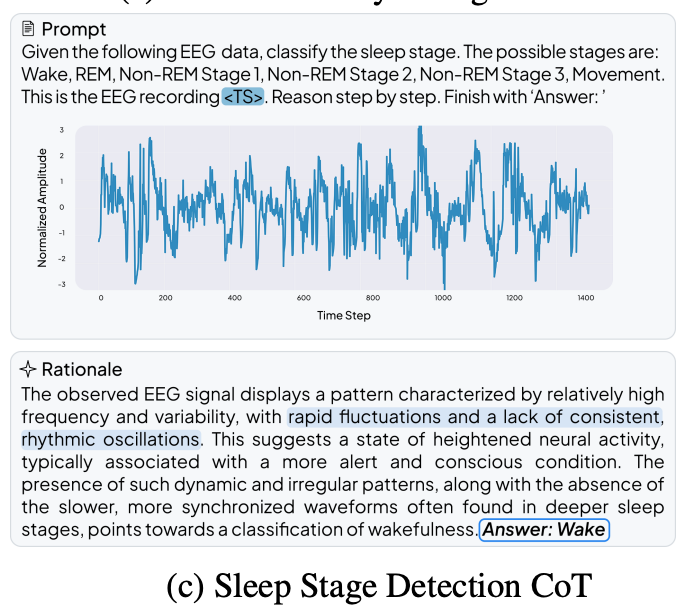
Notably, even the small-scale OpenTSLM model (1 billion parameters) significantly outperforms GPT-4o. Whether processing the data as text markup (where GPT-4o scores only 15.47% on Sleep-CoT) or images, cutting-edge models cannot match specialized TSLM.
This finding highlights that specialized, domain-adapted AI architectures can achieve superior results without scale, providing a platform for efficient, On-device medical AI deployment.
Clinical Validation at Stanford Hospital: Ensuring Trust and Transparency
A key element of medical AI is trust. Unlike traditional models that output a single classification, OpenTSLM generates human-readable rationales (chains of ideas) that explain its predictions. this AI transparency Essential for clinical settings.
To verify the quality of this reasoning, experts from five cardiologists conducted a review stanford hospital. They evaluated the basic principles of OpenTSLM-Flamingo model generation: ECG interpretation.
The evaluation found that the model provided correct or partially correct ECG interpretation in an impressive manner. 92.9% Number of cases. The model showed exceptional strength in integrating clinical context (85.1% positive evaluation), demonstrating sophisticated reasoning capabilities on raw sensor data.
The future of multimodal machine learning
The launch of OpenTSLM marks the Multimodal machine learning. By effectively bridging the gap between LL.M. and time series data, this study lays the foundation for a general-purpose TSLM capable of handling different longitudinal data, not only in the healthcare field, but also in finance, industrial monitoring, etc.
To accelerate innovation in the field, the Stanford and ETH Zurich teams have open sourced all code, datasets, and trained model weights.
Check Paper is here. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

Jean-marc is a successful artificial intelligence business executive. He has led and accelerated the development of artificial intelligence-driven solutions and founded a computer vision company in 2006. He is a recognized speaker at artificial intelligence conferences and holds an MBA from Stanford University.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


