Intel Laboratory explores low -level adapter and neurological architecture search LLM compression

For various natural language processing applications, including machine translation, text abstract and dialogue AI, large language models (LLM) have become essential. However, the increasing complexity and size of their complexity have led to huge challenges for computing efficiency and memory consumption. With the growth of these models, resource demand makes it difficult for them to deploy in an environment with limited computing power.
The main obstacles of LLMS are their huge computing requirements. Training and fine -tuning these models involve billions of parameters, so that it has resource -intensive and limited accessability. Existing methods that improve efficiency, such as effective fine -tuning (PEFT), provide some relief, but usually damage performance. The challenge is to find a method that can greatly reduce calculation requirements, while maintaining the accuracy and effectiveness of the model under actual situation. Researchers have been exploring methods that allow effective model adjustments that allow a large number of computing resources.

Researchers at Intel Lab and Intel introduced a method that combines low -level adaptation (LORA) with neurological architecture search (NAS) technology. This method is designed to solve the limitations of traditional fine -tuning methods while improving efficiency and performance. The research team has developed a framework that optimizes memory consumption and calculation speed by using structured low -level representations. This technology involves a shared super network that dynamically adjusts the sub -structure to improve training efficiency. This integration makes the model effectively fine -tuning while maintaining the smallest calculation footprint.
The method introduced by Intel Labs is concentrated in Lona (search for low -level neural architecture). This method uses elastic LoRa adapter for models to fine -tune. Unlike the conventional methods that need to be fully investigated in LLM, Lona can selectively activate the model sub -structure, thereby reducing redundancy. The key innovation is the flexibility of the elastic adapter. This elastic adapter is dynamically adjusted according to the model. This method is supported by inspirational network search, which further simplifies the fine -tuning process. By paying attention to only related model parameters, this technology can reach a balance between calculating efficiency and performance. The structure of this process is to allow the low -level structure while maintaining a high reasoning speed.
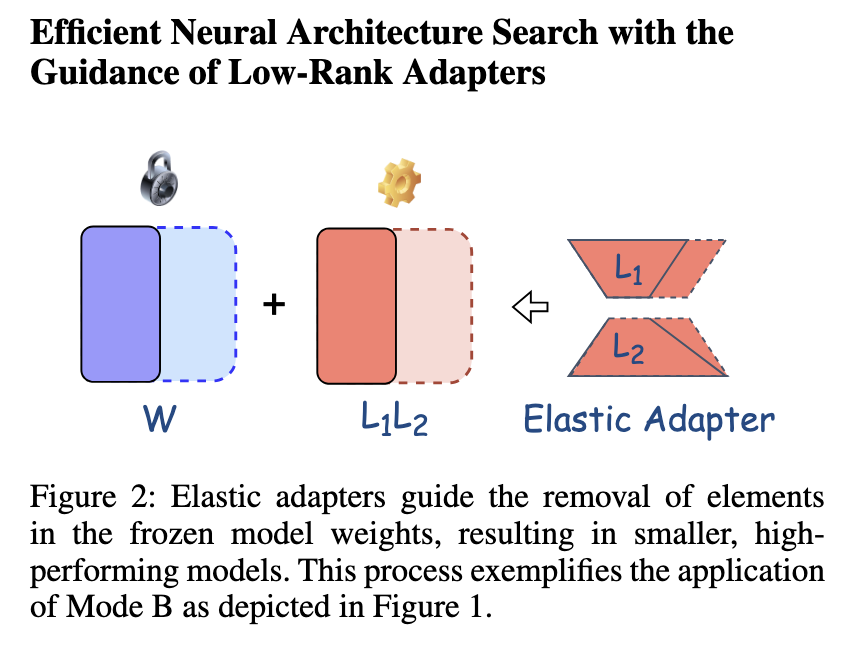
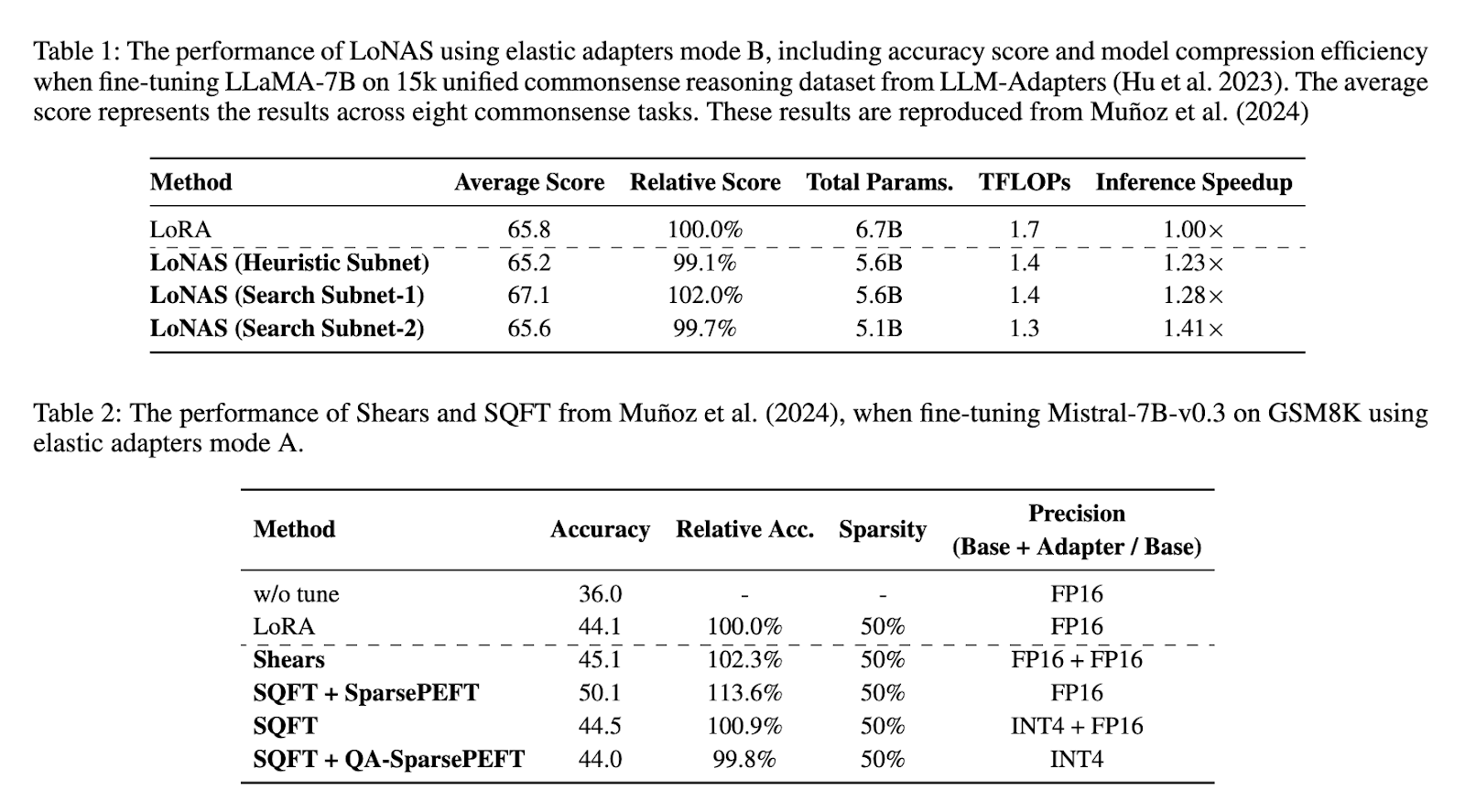
The performance assessment of the proposed method highlights its major improvement in traditional technology. The experimental results show that Lona’s reasoning speed is 1.4 times, and the model parameters are reduced by about 80 %. When the 15K unified common sense reasoning data set was applied to fine-tuning LLAMA-7B, the average accuracy score of Lonas was 65.8 %. The comparative analysis of different LONAS configuration shows that the optimization of inspirational network has reached 1.23 times the reasoning speed, while the search subnet configuration generates 1.28 times and 1.41X acceleration. In addition, the Mistral-7B-V0.3 of Lona in the GSM8K mission increases the accuracy from 44.1 % to 50.1 %, thereby maintaining the efficiency of different models. These findings confirm that the proposed methods can significantly improve the performance of LLM while reducing computing requirements.
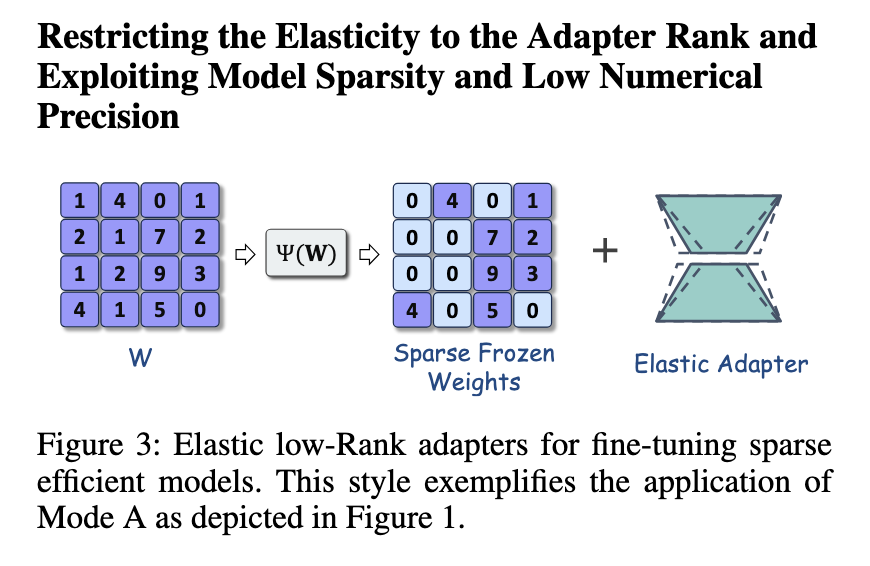
The further improvement of this framework includes the introduction of shear, which is a high -level fine -tuning strategy based on Lona. The scissors use the neurotransmal oriental ornament search (NLS) to limit the elasticity to the adapter level, thereby reducing unnecessary calculations. This method uses a predefined indicator to apply sparseness to basic models to ensure that fine -tuning is still effective. While reducing the number of activity parameters, this strategy is particularly effective in maintaining the accuracy of the model. Another extension of SQFT contains sparseness and low value accuracy to enhance fine -tuning. Using quantitative sensing technology, SQFT ensures that the sparse model can be fine -tuned without losing efficiency. These improvements highlight the adaptability of Lona and its further optimization potential.
Integrated LoRa and NAS provides a changeable method for optimization of large language models. By using the low -level level of structure, research shows that computing efficiency can be significantly improved without damage performance. Studies conducted by Intel Labs confirmed that combined with these technologies to reduce the burden of fine -tuning and ensure model integrity. Future research can explore further optimization, including enhanced sub -network selection and more effective inspiration strategies. This method provides a precedent for LLMS to more easily access and deployment in different environments, thereby paving the way for more effective AI models.
Check Paper and github page. All the credit of this research is researchers at the project. Also, don’t forget to follow us twitter And join us Telegraph and LinkedIn GrOutEssence Don’t forget to join us 70K+ ML ZitiditEssence
 Satisfy IntelLAGENT: An open source multi -agent framework to evaluate the complex dialogue AI system (Promotion)
Satisfy IntelLAGENT: An open source multi -agent framework to evaluate the complex dialogue AI system (Promotion)
Intel Post Intel Labs explored the low -level adapter, and Marktechpost first appeared a neurological structural search for LLM compression.


