How powerful is the Diffusion LL.M.? Rethinking the generation of mask diffusion models using any process
Once you think of generation as an algorithm with time and space complexity and not just a decoding trick, how powerful is diffusion LLM compared to classical autoregressive LLM? A new research paper published by a team of researchers from the Toyota Institute of Technology in Chicago and MIT provides a formal answer. The new study compared Autoregressive Model (ARM), Mask Diffusion Model (MDM)and a new family called Any Process MDM (AP-MDM)using complexity theory and controlled reasoning tasks.
ARM and MDM: same expressive power, different parallel times
ARM uses next tag predictions in strict left-to-right order. Previous work has shown that, with sufficient intermediate steps, ARM Turing completeso it can in principle represent any computable function given sufficient context and computation.
MDM is the discrete diffusion style used in the Diffusion LLM and works on the principle of mask sequence. The model starts with a fully masked sequence and iteratively unveils tokens. It can update multiple locations in parallel in any order. The MDM is modeled as an encoder-only Transformer, for an input of size (n), with context length (S(n)) and decoding step (T(n)).
The research team stated:
- MDM can simulate any PRAM (Parallel Random Access Machine) algorithm with parallel time (T(n)) using (O(T(n))) diffusion steps and context proportional to the total work (S(n)).
- This makes MDM Turing complete And let it match the ideal parallel time for problems in NC, such as graph joins and some context-free language tasks, where ARM requires time linearly related to the sequence length.
Master of Laws in Diffusion thus obtained efficiency Solving problems that are parallelizable, rather than having additional expressive power per se.
Arbitrary order generation has limited benefits
A natural question is whether Generate in any order Strictly speaking more powerful than the left-to-right generation.
To isolate this, the research team defined a Any Order MDM (AO-MDM) and corresponding Masked ARM Has the same architecture and similar token budget, but decodes in a fixed left-to-right manner on a sequence padded with a mask.
Key results:
- Any computation performed by AO-MDM using one token per step and context (S(n)) can be reorganized into a left-to-right plan and simulated by a Masked ARM with sequence length (O(S(n))) plus a constant number of extra layers.
In other words, once you control parallelism and architecture, Any order generation by itself will not expand the problem class beyond what ARM can already handle.
ARM and AO-MDM also have space constraints. Due to the context length (S(n)) they cannot efficiently solve problems that require more than a rough (S(n))3) serial time. In the polynomial context, they are effectively restricted to P-type problems and cannot handle general NP-hard tasks just by testing time scaling.
Arbitrary process generation and AP-MDM
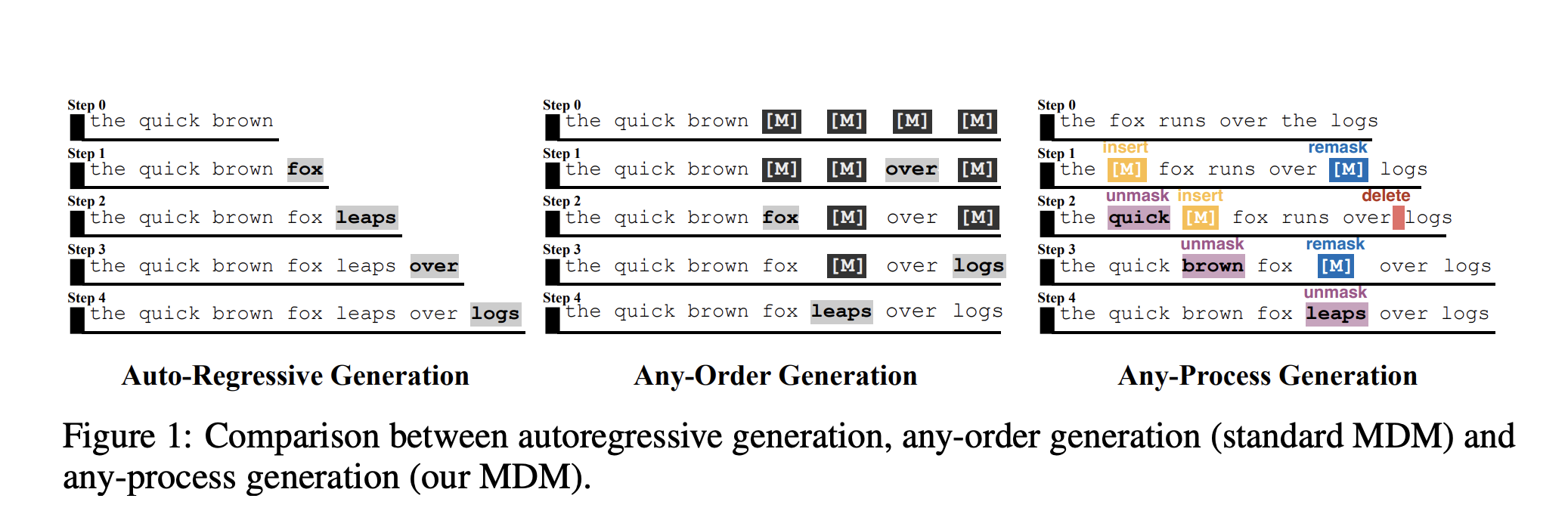
To transcend these limitations, the research team proposed Arbitrary process generationinstantiated as Any Process MDM (AP-MDM).
AP-MDM retains the mask diffusion view but extends the transformation function Three additional operationsin addition to the usual unblocking:
- remask:Convert decoded token back to masked token
M - insert: Insert a new mask mark at the selected location
- delete: Remove mask tokens that are no longer needed
These are controlled by a 3-bit vector per position (ct,i = (ct,i[1],ctime i[2],ct,i[3]). The same Transformer backbone predicts the content logic and these control bits.
remaskUse the first bit to decide whether to cover a positionMwhich makes backtracking and self-correction possible.insertanddeleteThe second and third bits are used to add or remove mask markers, so the sequence length can grow or shrink during decoding.
Architecturally, AP-MDM adds three small linear heads on top of an encoder-only Transformer, so it can easily be added on top of an existing MDM-style diffusion LLM.

Key theoretical results:
- AP-MDM can simulate any PRAM algorithm Optimal parallel time and optimal spaceusing a context proportional to the real space (S(n)) instead of the total workload. In a polynomial context, AP-MDM enables the following calculations: space spacewhile standard MDM and ARM under the same context budget are limited to P.
The research team also tried to prove that under standard complexity assumptions, there exists a constant-depth AP-MDM whose generation process cannot be simulated by any constant-depth ARM or Masked ARM.
Empirical results: Sudoku, Dyck, graphs, parity checks
Experiments match theory and make differences concrete.
Sudoku
Sudoku, extended to (n2 xn2) grid, is NP-complete.
- AP-MDM reaches 99.28% The accuracy is approx. 1.2 million parameters and only 100 Training examples.
- ARM baseline with ordering scope 87.18% use 1.8 million Training examples and related 5 times More parameters.
- The best AO-MDM baseline achieved 89.49% Under the same big data system.
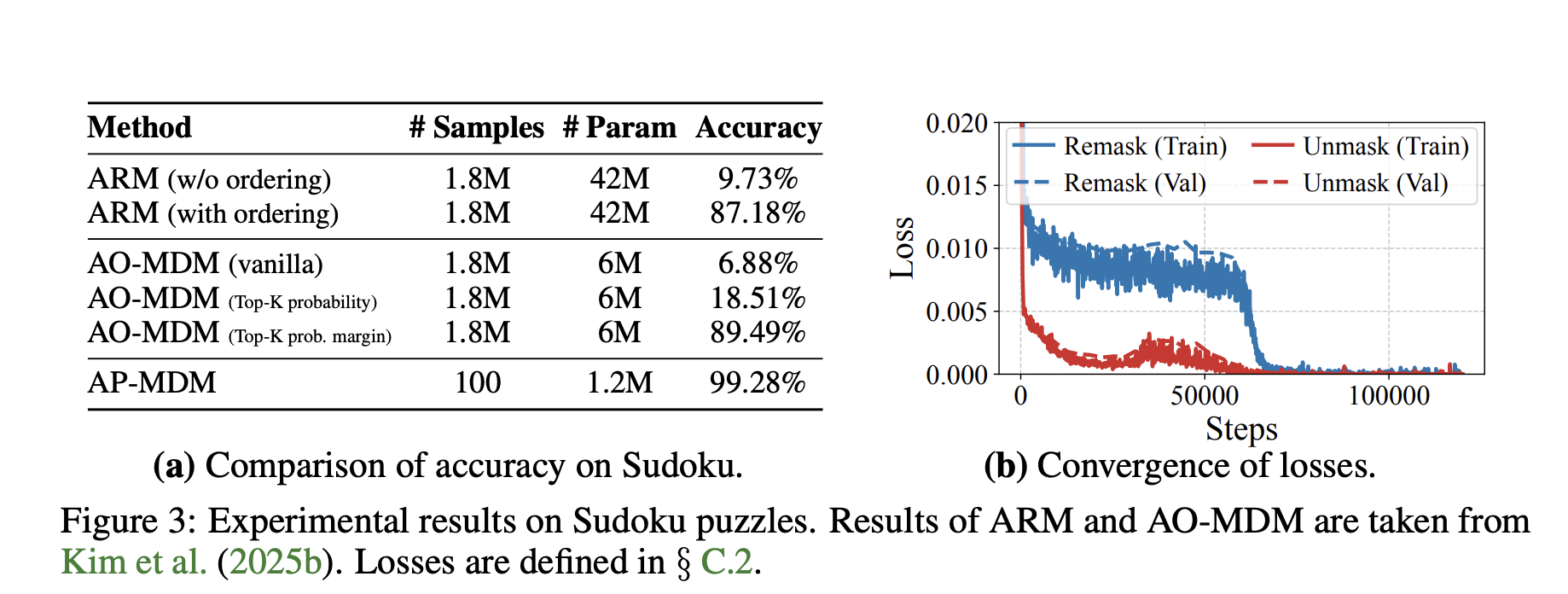
This suggests that editing operations, especially remasking, are critical to exploit test time scaling for hard inference tasks.
Dyck language and coding style constraints
Research also analyzes Reversible Dyke k language, which models matching parentheses and is the core abstraction for code syntax. It proves that the fixed ARM model cannot ensure efficient generation of arbitrary lengths, while there exists AP-MDM that uses insertion and re-masking to accurately generate Dyck languages.
This matches the way in which encoding tasks require structure-aware editing within global constraints, such as balanced brackets and consistent scope.
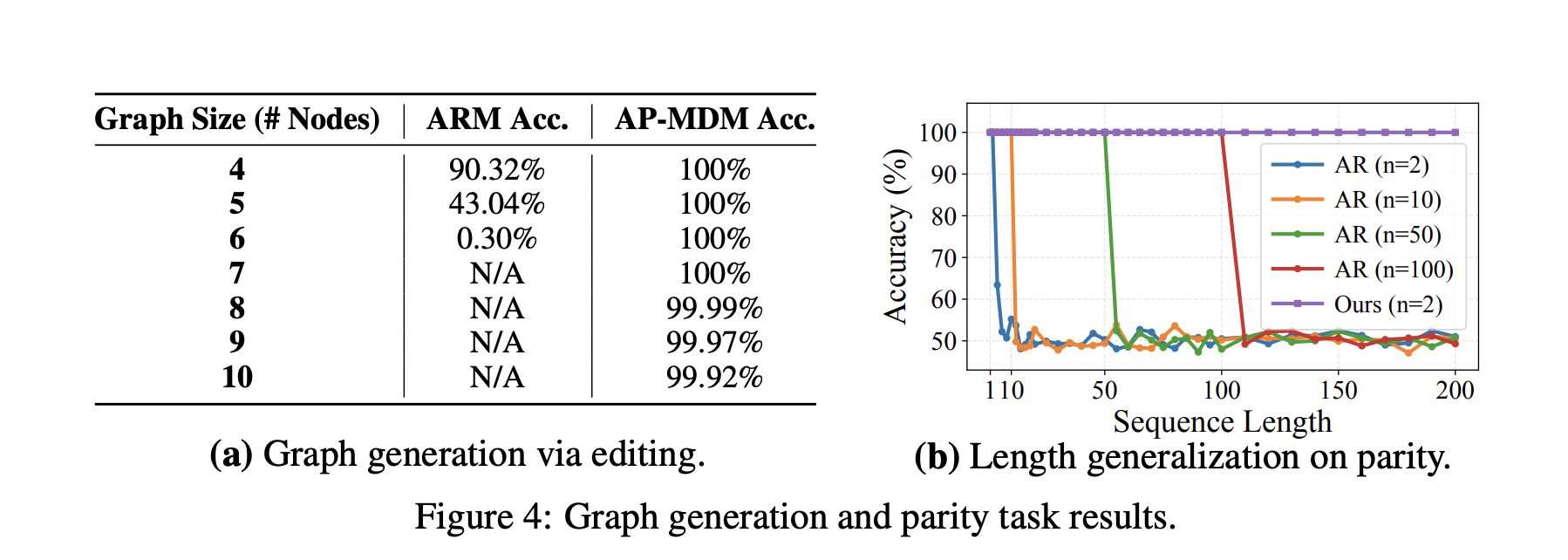
Graphic generation and structure editing
For graph editing tasks under global constraints, AP-MDM uses insertion, deletion, and remasking to implement a series of structured edits on the graph representation. As the graph size increases, the accuracy of the reports remains near perfect, while ARM decreases as the graph gets larger.
Parity and length generalization
On parity, AP-MDM learns partial elimination rule By deleting bit pairs, driven by remasking and deletion. It trains only on sequences of length 2 and then implements 100% Generalizes to any length. Even with longer training sequences, the ARM baseline struggles to achieve similar generalization capabilities.
Main points
- Once the architecture and parallelism are fixed, mask diffusion models of any order are as expressive as autoregressive models, and they mainly provide parallel efficiency rather than new computational power.
- Masked diffusion models can simulate the PRAM algorithm and achieve exponential speedup on parallelizable tasks in NC, but in a polynomial context they are still effectively limited to P-type problems, similar to autoregressive models.
- Any Process MDM extends diffusion LLM by remasking, inserting and deleting operations, implemented through three-bit control vectors per token, and can simulate PRAM with optimal parallel time and optimal space, reaching PSPACE level expressiveness in polynomial context.
- In hard reasoning tasks such as generalized Sudoku, Dyck language, graph editing, and parity checking, AP MDM shows strong empirical advantages, such as achieving approximately 99.28% Sudoku accuracy with only 100 training instances, and with a much smaller parameter budget than autoregressive and arbitrary-order MDM baselines.
- For domains such as coding, mathematics, and AI4Science that involve structured edits and revision histories, AP MDM is more consistent with the underlying generation process than next tag prediction, and its editing operations have proven difficult to simulate with constant depth autoregressive models.
Any-Process MDM is an important step because it treats generation as a complete algorithm, not just a decoding sequence. Research work shows that the mask diffusion model has been time-matched to PRAM parallelism but remains in P on a polynomial background, similar to the autoregressive model. By adding remasking, insertion, and deletion, AP-MDM reaches PSPACE-level expressiveness in polynomial contexts and achieves strong empirical gains in Sudoku, Dyck, graph editing, and parity checking. Overall, AP-MDM makes a strong case that future cutting-edge LL.M.s should adopt edit-based Any-Process Generation rather than just faster autoregression.
Check Paper and repurchase agreement. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


