Graph-R1: A proxy graph framework for structured, multi-turn reasoning and through enhanced learning
introduce
Large language models (LLMS) have set new benchmarks in natural language processing, but their hallucinatory trends (making outputs inaccurate) are a key issue for knowledge-intensive applications. The Retrieval Enhanced Generation (RAG) framework attempts to address this problem by incorporating external knowledge into language generation. However, traditional rag methods depend on block-based retrieval, which limits their ability to represent complex semantic relationships. GraphRag solves some structural limitations, but still faces high construction costs, rigidity of one-time search, and reliance on novel reasoning and elaborate tips.
Researchers at Nanyang Technical University, National University of Singapore, Beijing Institute of Computer Technology and Applications, and Beijing Anzhen Hospital have been presented Graph-R1a proxy GraphRag framework powered by end-to-end enhanced learning.
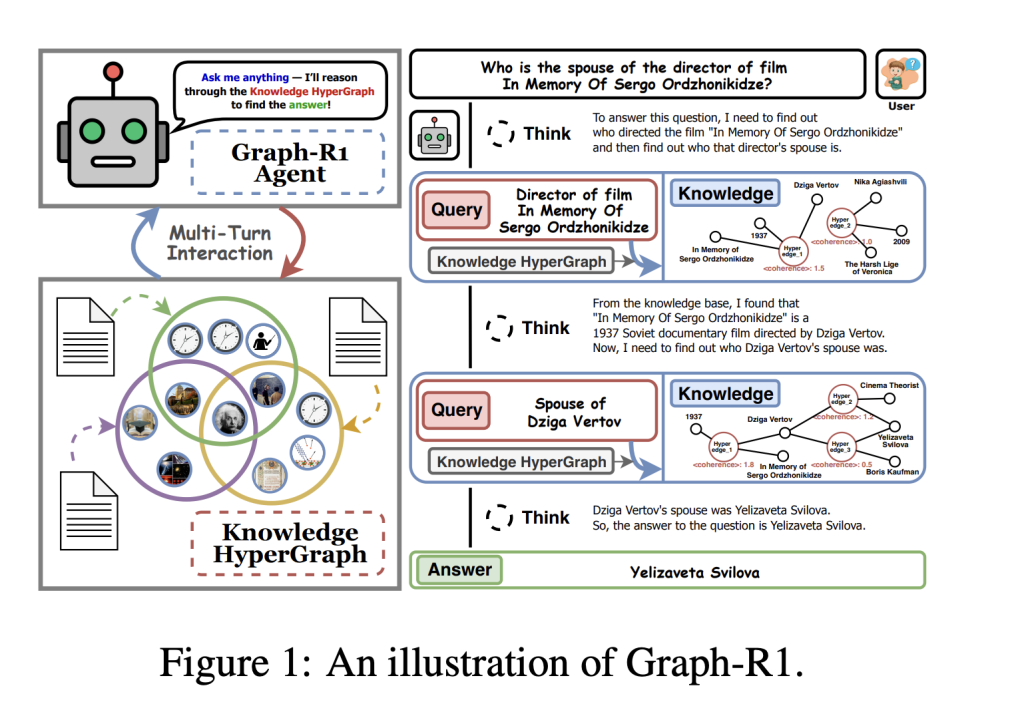
The core innovation of Graph-R1
1. Light knowledge superchart structure
Graph-R1 constructs knowledge as a hypergraph where each knowledge segment is extracted using LLM-driven N-ARY relationship extraction. This method encodes richer and semantically basic relationships, enhancing proxy reasoning capabilities while maintaining manageable costs and computational requirements.
- efficiency: Construction is only 5.69 seconds and $2.81 per 1,000 tokens ($3.35 for GraphRag, $4.14 for HyperGraphrag), while generating semantic rich graphs with 120,499 nodes and 98,073 edges.
2. Multi-turn agent search process
The Graph-R1 model uses retrieval as a multi-turn communication loop (“Think-Retrieve-ReThink-Generate”), allowing the agent to adapt to query and refine its knowledge paths, unlike the previous method of using one-tone search.
- Dynamic reasoning: The agent decides in each step whether to continue exploring or terminate the answer. Entity-based and direct HyperEdge searches are fused through mutual hierarchical aggregation, thereby improving the chances of retrieving the most relevant knowledge.
3. End-to-end reinforcement learning optimization
Graph-R1 uses Group Relative Policy Optimization (GRPO) for end-to-end RL, integrating rewards for format compliance, relevance and answer correctness. This unified reward guide allows agents to develop popular reasoning strategies that are closely aligned with knowledge structure and output quality.
- Result guidance reward mechanism: Combining format rewards (structural coherence) and answer rewards (semantic accuracy) to achieve effective optimization, only reward answers embedded in structurally effective inference trajectories.
Key Discovery
Benchmarking on rag quality inspection tasks
Graph-R1 was evaluated in six standard QA datasets (2wikimultihopqa, hotpotqa, musique, natural problem, popqa, triviaqa).
| method | avg. F1 (QWEN2.5-7B) |
|---|---|
| Innocent | 13.87 |
| Standardrag | 15.89 |
| GraphRag | 24.87 |
| Hypergraphrag | 29.40 |
| Search for r1 | 46.19 |
| R1-Searcher | 42.29 |
| Graph-R1 | 57.82 |
- Graph-R1 using QWEN2.5-7B reached an average F1 of 57.82, exceeding all previous baselines. Larger basic models amplify their performance growth.
Ablation analysis
Component ablation shows that deleting hypergraph structures, multi-transformation reasoning, or RL optimization greatly reduces performance, thus verifying the necessity of each module in Graph-R1.
Search and efficiency
- Graph-R1 search is more concise and effective. It gets high F1 scores with a medium average content length (~1200-1500 tokens) and supports more interactive turns (average 2.3-2.5), facilitating stable and accurate knowledge extraction. 2507.21892V1.pdf
- The cost of power generation is very small: Despite being more representative, Graph-R1 has better response time per query (7.0s) and cost per problem ($0) than graph-based competitors such as HyperGraphRag (9.6s, $8.76, $8.76).2507.21892V1.pdf
Power generation quality
The generation quality of Graph-R1 is evaluated on seven dimensions, namely goodness, knowledge, correctness, correlation, diversity, logical coherence, factuality – and always outperforms all RL-based RL-based baselines, thus achieving the highest score (88.5) in correctness (86.9), correlation (95.2) and CORECERICE (95.2) and CORECERCE (88.5).
Generalization
Cross-validation of Out-of-Distribution (OOD) settings indicate Graph-R1 maintains robust performance in the dataset, with OOD/IID ratios typically exceeding 85%, Prove powerful domain generalization features.
Theoretical assurance
Graph-R1 is supported by information theory analysis:
- Knowledge of graphical structure Compared with block-based searches, each search and faster convergence provide higher information density.
- Multi-transfer interaction By dynamically focusing on high-impact map areas, agents can achieve higher retrieval efficiency.
- End-to-end RL optimization The evidence and language generation of bridged graphical structures reduces output entropy and error rates.
Algorithm Workflow (Advanced)
- Knowledge hypergraph extraction: LLM extracts N-ARY relationships to build entities and beyond collections.
- Multi-turn proxy reasoning: Agents alternate between reflective thinking, query, hypergraph retrieval (entity and hypersided dual paths) and synthesis.
- GRPO optimization: Update RL policies using sampling trajectory and reward normalization, perform structures and answer correctness.
in conclusion
Graph-R1 shows that integrated knowledge representation based on hypergraphs, agent multi-transformation reasoning, and end-to-end RL can provide unprecedented benefits in terms of fact-quality quality quality performance, retrieval efficiency and power generation quality, drawing paths for next generation agent-driven LLM systems.
FAQ 1: What are the key innovations in Graph-R1 compared to the early Graprag and rag systems?
Graph-R1 introduces a proxy framework in which retrieval is modeled as multi-turn interactions rather than a single-shot process. Its main innovations are:
- Super-graphic knowledge representation: Graph-R1 is not a simple entity relationship graph or text block, but rather a semantic hypergraph that can make a more expressive N-ARY relationship between entities.
- Multi-turn reasoning cycle: The agent runs in a loop of repeated “think-rethink-generate” on the hypergraph, focusing on the query dynamically instead of retrieving everything at once.
- End-to-end enhanced learning (RL): Agents are trained on rewards, which simultaneously optimizes step-by-step logical reasoning and final answer correctness, thus making the alignment between structured knowledge and natural language answers closer.
FAQ 2: How is the search and power generation efficiency of Graph-R1 compared to previous methods?
Graph-R1 is significantly efficient and effective in both retrieval and answer generation:
- Lower construction and search costs: To build a knowledge hypergraph, Graph-R1 takes only 5.69 seconds and costs better than a similar graph-based approach per 1,000 tokens (on the 2Wiki dataset).
- Faster, cheaper generation: Query response time (7 seconds per query) and power generation cost ($0 per query) outperform previous graphical rag systems such as HyperGraphRag.
- Simplicity and robustness: Graph-R1’s answer is both more concise (usually 1,200-1,500 tokens) and more accurate due to the interaction of multiple turns, with state-of-the-art F1 scores in six QA datasets.
FAQ 3: What are the most suitable solutions or domains for the Graph-R1 framework?
Graph-R1 is ideal for complex knowledge-intensive applications that require factual accuracy and inference transparency, such as:
- Healthcare and Medical AI: Multi-hop reasoning, traceability and reliability are crucial.
- Legal and regulatory areas: This requires precise grounding answers and explainable multi-step reasoning.
- Enterprise knowledge automation: For tasks that require scalable, dynamic query and retrieval in large documents or data corpus.
The architecture of the model can also easily adapt to other fields of agents anchored from structured representations, multi-turn knowledge search.
Check Paper and github pages. Check out ours anytime Tutorials, codes and notebooks for github pages.
Sana Hassan, a consulting intern at Marktechpost and a dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. He is very interested in solving practical problems, and he brings a new perspective to the intersection of AI and real-life solutions.
 course: Developers’ Guide to Building and Deploying Context Aware AI Agents and Applications")

