GPZ: Next Generation GPU Acceleration Loss Compressor for Large-Scale Particle Data
Particle-based simulations and point cloud applications are driving massive expansion of size and complexity of scientific and commercial datasets, often jumping into the realm of billions or trillions of discrete points. Effectively reducing, storing and analyzing this data without bottled modern GPUs is one of the emerging challenges in areas such as cosmology, geology, molecular dynamics, and 3D imaging. Recently, a team of researchers from Florida State University, the University of Iowa, Argonne National Laboratory, the University of Chicago and several other institutions GPZa GPU-optimized, wrong loss compressor that fundamentally improves particle data throughput, compression ratio and data fidelity – with larger margins as five state-of-the-art alternatives.
Why compress particle data? Why is it so difficult?
Particle (or point cloud) data (unlike structural meshes) serve as an irregular set of discrete elements in a multidimensional space. This format is crucial to capture complex physical phenomena, but Low space-time coherence There is little redundancy, making it a nightmare for classical lossless or universal lossy compressors.
consider:
- The Peak Supercomputer generates a 70 TB single cosmological simulation snapshot using an NVIDIA V100 GPU.
- USGS 3D Elevation Plan has over 200 TB of storage space for US terrain point clouds.
Traditional methods (such as downsampling or direct processing) enter up to 90% of the raw data or foreclosure repeatability through the lack of storage. Furthermore, compressors with general-purpose grids take advantage of the non-existent correlation in particle data that does not exist at all, resulting in poor proportions and poor GPU throughput.
GPZ: Architecture and Innovation
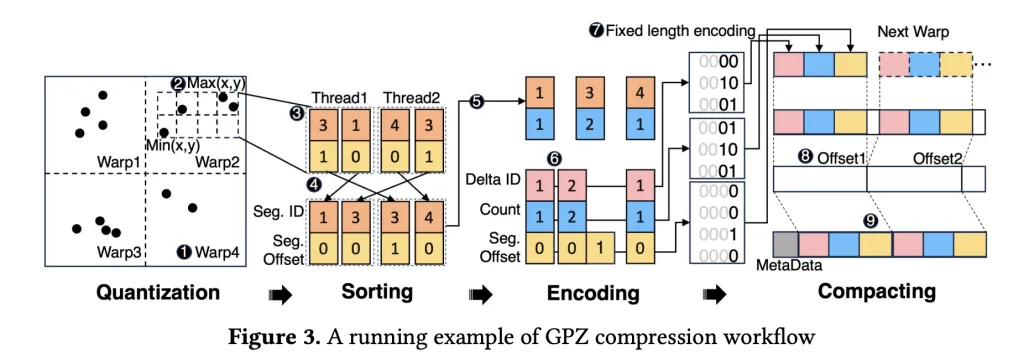
GPZ is equipped Four-stage parallel GPU pipeline– Especially designed for the quirks of particle data and the strict requirements of modern parallel hardware.
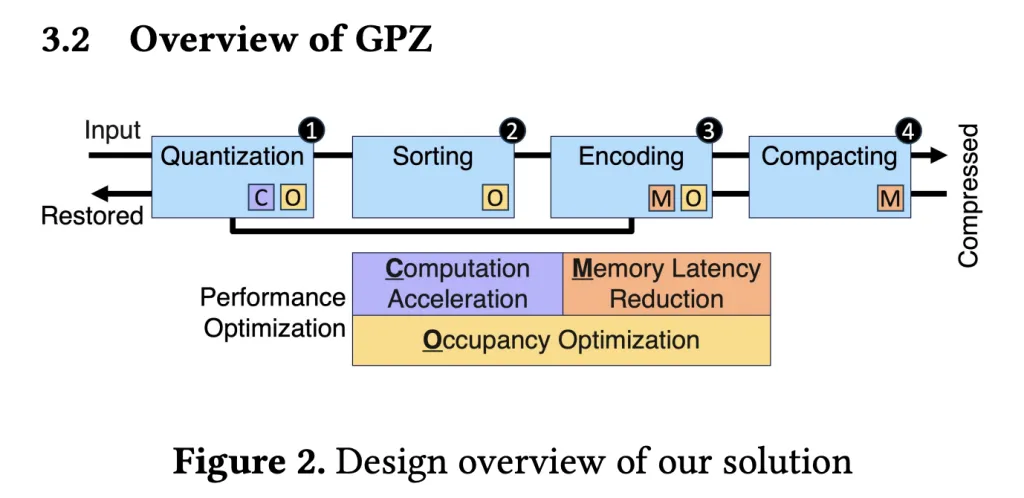
Pipeline stage:
- Space quantization
- The floating point position of the particle is mapped to integer segment ID and offset, respecting the error boundaries specified by the user, while utilizing fast FP32 operations to obtain maximum GPU arithmetic throughput.
- Segmentation is adjusted to the optimal GPU occupancy.
- Spatial classification
- In each block (map to CUDA warp), particles are sorted by their segment IDs to enhance subsequent lossless encoding – using warp-level operations to avoid expensive synchronization.
- Block-level sorting balances compression rates with shared memory footprints for optimal parallelism.
- Lossless encoding
- Innovative parallel run length and delta encoding band redundancy with classification segment ID and quantized offset.
- Bitplane encoding eliminates zero bits, and all steps are heavily optimized for GPU memory access mode.
- compact
- Use a three-step device-level strategy to effectively assemble the compression block into continuous output, which cuts synchronization overhead and maximizes memory throughput (809 GB/s on the RTX 4090, near the theoretical peak).
Decompression is the opposite – extracting, decoding and reconstructing positions within the error range, thus achieving high-fidelity post hoc analysis.
Hardware-aware performance optimization
GPZ and a set Hardware-centric optimization:
- Memory merge: Read and write carefully aligned with 4 byte boundaries (up to 1.6x access permissions) that maximize DRAM bandwidth.
- Register and shared memory management: The algorithm is designed to maintain a high occupancy rate. Drop the accuracy to the FP32 as much as possible and avoid using too many registrations to prevent overflow.
- Calculate Scheduling: Each block map, explicitly use CUDA intrinsic mappings such as FMA operations and loop unfold in beneficial places.
- Partition/Simulation Elimination: Replace slow partition/modulus operations with pre-calculated reciprocal and bit masks whenever possible.
Benchmark: GPZ with state-of-the-art
GPZ was evaluated on six real-world datasets (from cosmology, geology, plasma physics, and molecular dynamics), spanning three GPU architectures:
- Consumer: RTX 4090,
- Data Center: H100 SXM,
- Edge: NVIDIA L4.
Benchmarks include:
- cuszp2
- pfpl
- fz-gpu
- cusz
- cusz-i
Most of these tools are optimized for general science mesh, fail on particle datasets over 2 GB on particle datasets or show severe performance/mass degradation; GPZ remains strong throughout the process.
result:
- speed: GPZ pass compression throughput 8 times higher The second best competitor. The average throughput reached 169 GB/S (L4), 598 GB/S (RTX 4090) and 616 GB/S (H100). The pressure reduction scale is even higher.
- Compression ratio: GPZ always outperforms all baselines, with a 600% increase in the ratio in a challenging environment. Even if the runner-up is slightly ahead, the GPZ has a 3x-6x speed advantage.
- Data quality: Rate extension diagrams confirm the excellent preservation of scientific features (lower bitrates), and visual inspections (especially in 10x enlarged views) reveal that the reconstruction of GPZ is almost indistinguishable from the original work, while other compressions produce visible artifacts.
Key Points and Meanings
GPZ lowers the new gold standard for real-time large-scale particle data for modern GPUs. Its design recognizes the basic limitations of a universal compressor and offers tailored solutions that leverage every ounce of GPU-parallelism and precise adjustment.
For researchers and practitioners who study large amounts of scientific data sets, GPZ provides:
- Strong differential compression for in situ and post-clinical analysis
- Practical throughput and ratios for consumer and HPC-grade hardware
- Close perfect reconstruction of downstream analysis, visualization and modeling tasks
As data size continues to expand, solutions such as GPZ will increasingly define the next era of scientific computing and large-scale data management for GPUs.
Check The paper is here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.

")
