Google DeepMind found basic error in rags: large-scale search of embed restrictions
Retrieval-enhanced generation (RAG) systems often rely on dense embedding models that map queries and documents into vector spaces of fixed dimensions. Although this approach has become the default value for many AI applications, the latest research from Google DeepMind Team explains Basic building restrictions This cannot be solved by a larger model or by just better training.
What is the theoretical limit of embedded dimensions?
The core of the problem is the representative ability of fixed-size embedding. Embedding of dimensions d Once the database grows beyond the critical size, it is impossible to represent all possible combinations of related documents. This depends on the communication complexity and the results of symbolic theory.
- For embedding of size 512, search for decomposition 500k file.
- For 1024 dimensions, the limit extends to approximately 4 million files.
- For 4096 dimensions, the theoretical upper limit is 250 million files.
These values are based on Free embed optimizationwhere it is optimized directly for the test label. The constrained embedding in the real world fails even earlier.

How does the limit benchmark expose this problem?
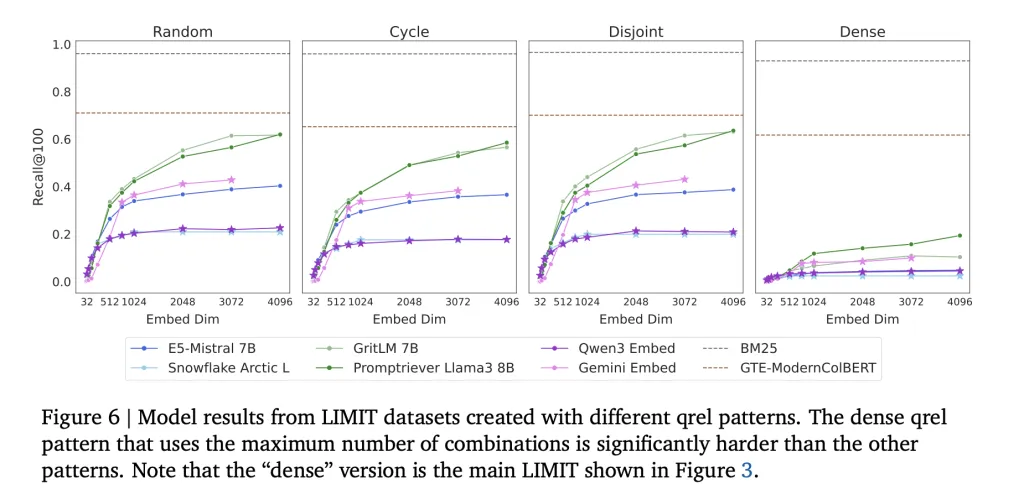
To test this limitation empirically, the Google DeepMind team introduced the limit (embedding limit for embedding in information retrieval), a benchmark dataset designed specifically for stress testing embedders. There are two configurations limited:
- Limit complete (50k files): In this massive setup, even a strong embedded crash, recall @100 often drops Less than 20%.
- Little limit (46 files): Although the toy size setting is simple, the model still doesn’t solve the task. Performance varies greatly, but far from reliable:
- PROMPTRIEVER LLAMA3 8B: 54.3% recall @2 (4096D)
- GRITLM 7B: 38.4% recall @2 (4096D)
- E5-Judicial 7B: 29.5% recall @2 (4096D)
- Gemini Embedding: 33.7% of memories @2 (3072d)
Even with only 46 documents, no embedder is fully recalled, which emphasizes that the limitation is not the dataset size, but the single-vector embedding architecture itself.
By comparison, BM25This is a classic sparse vocabulary model that does not suffer from this ceiling. Sparse models run in efficient unbounded dimensional spaces, allowing them to capture combinations that are not possible with dense embeddings.
Why is this important for rags?
CCURRENT RAG implementations usually assume that embeddings can be expanded indefinitely with more data. The Google DeepMind research team explained that this assumption is incorrect: Embed size inherently constrains retrieval capabilities. This will affect:
- Enterprise Search Engine Process millions of files.
- Agent system Rely on complex logical queries.
- Guide the search taskquery dynamically defines the correlation.
Even MTEB (MTEB) cannot capture these limitations because they only test the narrow parts/parts of querying the document combination.
What is the alternative to single-vector embedding?
The research team suggests that scalable retrieval will require going beyond single-vector embedding:
- Cross encoder: Perfect memories of achieving the limit by querying documents through direct scores, but at the cost of high inference latency.
- Multivector model (e.g., Colbert): By allocating multiple vectors for each sequence, improving the performance of the limiting task, providing more expressive retrieval.
- Sparse Model (BM25, TF-IDF, Sparse-Nerve Hound): Better scaling in high-dimensional search, but lacks semantic generalization.
The key insight is Need for architectural innovationnot just a larger embedded type.

What are the key points?
The team’s analysis shows that despite their success, intensive embeddings are still affected Mathematical limitations: Once the corpus size exceeds the limits associated with the embed dimension, they cannot capture all possible combinations of correlations. The limit benchmark specifically proves this failure:
- exist Limit Full (50k documentation): Recall @100 drops below 20%.
- exist Little limit (46 documents): Even the best model max ~54% memory @2.
Classical technologies such as BM25 or newer architectures such as multi-vector searchers and cross encoders are critical to building reliable search engines at scale.
Check The paper is here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


