Google AI unleashes Vaultgemma: the largest, most powerful open model (1B parameter), training from scratch with different privacy
Google AI Research and DeepMind have been released Vaultgemma 1Bthe largest open large language model is fully trained Differential Privacy (DP). This development is a major step towards building a strong and private AI model.
Why do we need differential privacy in LLMS?
Large language models trained on large network-scale datasets are easy Memory Attacksensitive or personally identifiable information can be extracted from the model. Research shows that word-by-word training data can reappear, especially in open versions.
Differential Privacy Provided Mathematical assurance This prevents any single training example from significantly affecting the model. Unlike the method of applying DP only during fine-tuning, Vaultgemma executes Complete private pre-processingensure privacy protection begins at the basic level.
What is the architecture of the section library?
Vaultgemma is architecturally similar to the earlier Gemma models, but optimized for private training.
- Model size: 1b parameters, 26 layers.
- Transformer type: Decode only.
- activation:geglu, the feedforward dimension is 13,824.
- attention: Multi-Legend Attention (MQA) with a global span of 1024 tokens.
- normalization:rmsnorm is in pre-total configuration.
- Token: Sentences with 256K vocabulary.
A significant change is Reduce the sequence length to 1024 tokens,This reduces computational costs and achieves larger batch sizes under DP constraints.
What data is used for training?
Vault dance trained The same 13 trillion data sets As Gemma 2, it consists mainly of English text in web documents, code and scientific articles.
This dataset undergoes multiple filtering stages to:
- Delete unsafe or sensitive content.
- Reduce exposure of personal information.
- Prevent assessment data contamination.
This ensures the safety and fairness of the benchmark test.
How to apply differential privacy?
Used vault gemma DP-SGD (differentiated private stochastic gradient descent) Gradient clips and Gass noise. Implementation is based on JAX Privacy and Scalability optimization is introduced:
- Vectorized every sample clip For parallel efficiency.
- Gradient accumulation Simulate large batches.
- Truncated Poisson’s Sampling Integrate into the data loader for efficient online sampling.
The model has achieved Formal DP guarantee (ε≤2.0, δ≤1.1E -10) at the sequence level (1024 token).
How does zoom law use for private training?
Training large models under DP constraints requires new scaling strategies. The Vaultgemma team developed DP-specific scaling law There are three innovations:
- Best learning rate modeling Use secondary fitting in training runs.
- Extrapolation of parameters of loss value Reduce dependence on intermediate checkpoints.
- Half-parameter fitting Overview across model size, training steps, and noise ratios.
This method enables accurate prediction of achievable losses and effective resource usage in TPUV6E training clusters.
What is training configuration?
Vault dance trained 2048 TPUV6E chip Use GSPMD partition and Megascale XLA assembly.
- Batch size: ~518K token.
- Training iteration: 100,000.
- Noise multiplier:0.614.
The achieved loss is within 1% predicted in the DP scaling law, thus verifying the method.
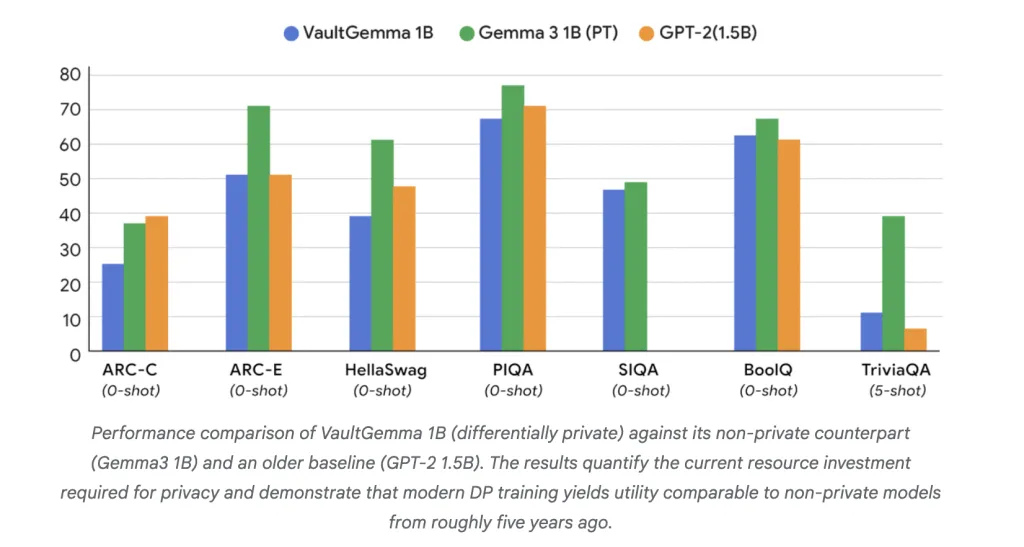
How does Vaultgemma perform compared to non-private models?
Under academic benchmarks, Vaultgemma delays its non-private rivals, but shows powerful utility:
- arc:26.45 vs. 38.31 (Gemma-3 1b).
- piqa: 68.0 vs. 70.51 (GPT-2 1.5B).
- Triviaqa (5 shots):11.24 vs. 39.75 (Gemma-3 1b).
These results show that the DP-trained model is currently in the same way as Non-private model about five years ago. Importantly, memory tests confirmed No training data leak Unlike the non-private Gemma model, it can be detected in vault dance.
Summary
All in all, Vaultgemma 1B demonstrates that large-scale language models can be trained with strict differential privacy guarantees without making them impractical to use. Although utility gaps remain in place compared to non-private relationships, the release of this model and its training approach provides a good foundation for the community to drive private AI. This work marks a shift towards a building model that is not only capable, but inherently secure, transparent and protected.
Check Paper, model hugging face and Technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
 course: Developers’ Guide to Building and Deploying Context Aware AI Agents and Applications")

