Google AI releases embedded game: 308m parameter embedded model with state-of-the-art MTEB results
Embedding instrument Google’s new open text embedding model has been optimized for device AI, aiming to balance efficiency with state-of-the-art retrieval performance.
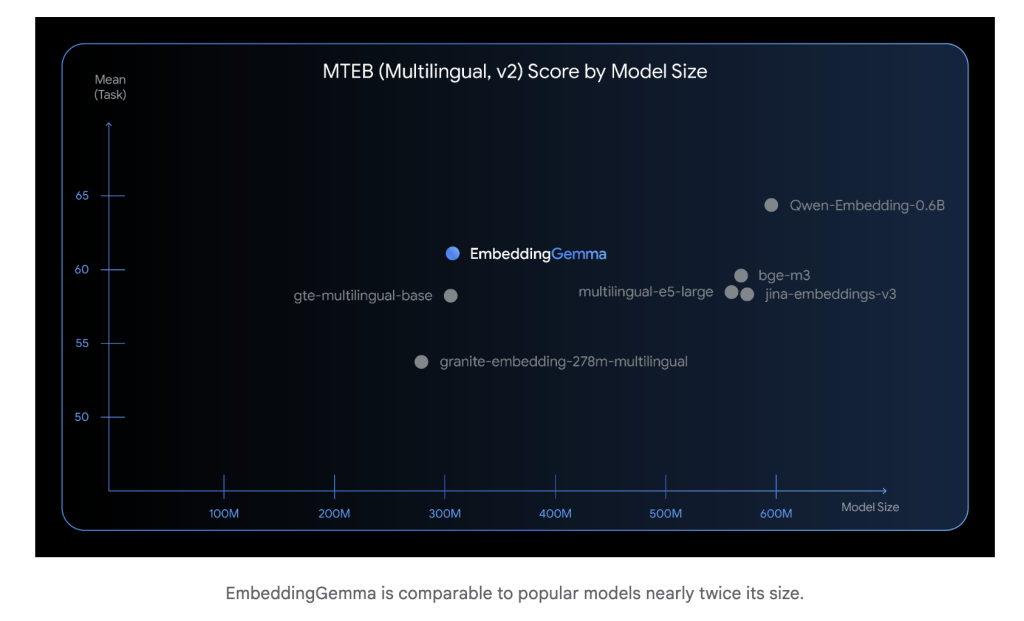
How compact is the embedding contact compared to other models?
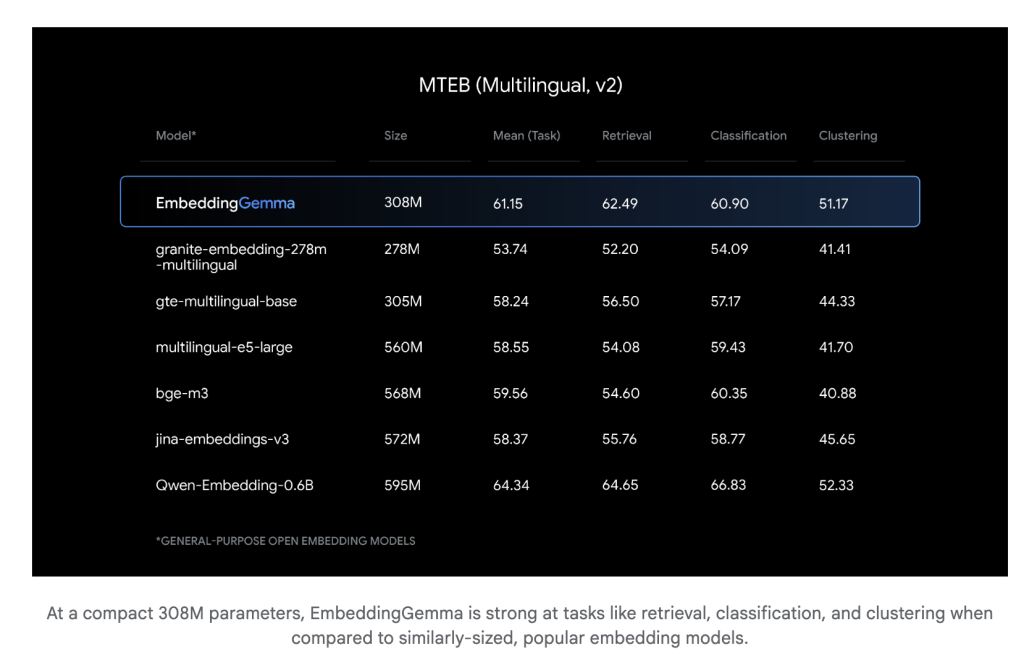
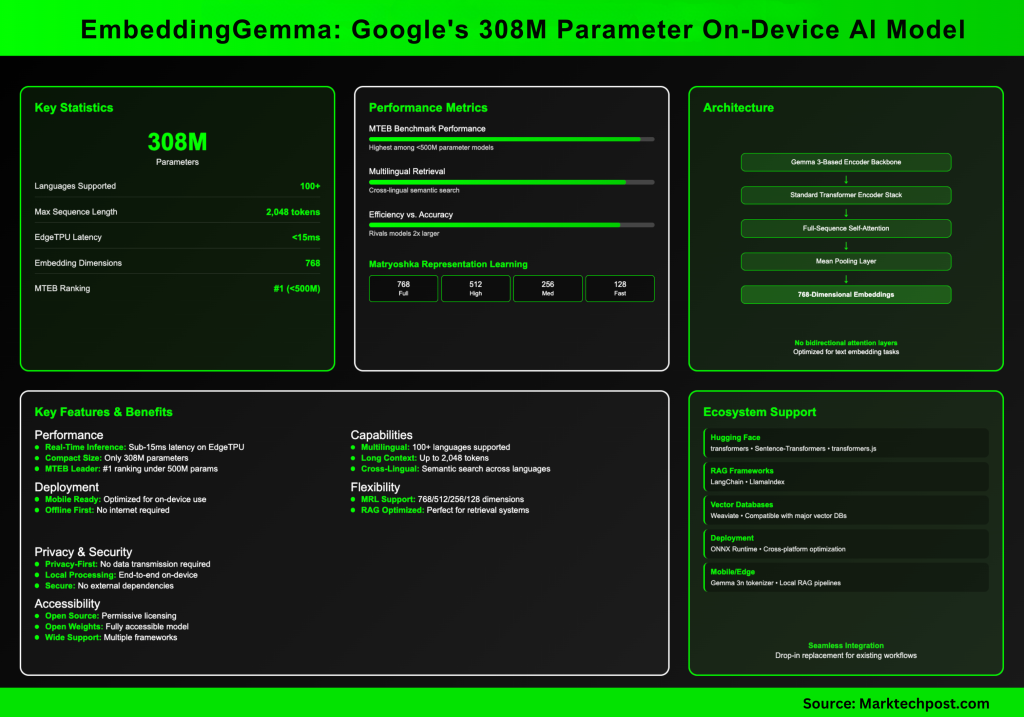
only 308 million parametersEmbeddingGemma is lightweight enough to run on mobile devices and offline environments. Despite its size, its embedded model is competitive. The reasoning latency is low (256 tokens under 15ms on EdgetPu), making it suitable for real-time applications.
How does it perform on multilingual benchmarks?
Embed training More than 100 languages And implemented Top ranking on Massive Text Embedding Benchmark (MTEB) In models below 500m. Its performance competitors may exceed the size of the embedded model almost twice, especially in cross-language retrieval and semantic search.
What is foundational building?
The embedded film is built on Gemma 3 encoder main chain based on mean merge. Importantly, this architecture does not use the multimodal specific bidirectional attention layer for Gemma 3 suitable for image input. Instead, embedded use Standard transformer encoder stack with complete self-attentionwhich is a typical feature of the text embedding model.
This encoder will produce 768-dimensional embedding And support sequences 2,048 tokensmaking it ideal for search results (RAG) and long-term searches. The average pooling step ensures that the fixed-length vector is represented regardless of the input size.
What makes it embedded flexible?
Using embedded Matryoshka stands for Learning (MRL). This allows the embedding to be truncated from 768 dimensions to 512, 256, or even 128 dimensions, with minimal mass loss. Developers can adjust the tradeoff between storage efficiency and retrieval accuracy without retraining.
Can it run completely offline?
Yes. The embedded device is specially designed On the device, offline first use case. Because it has Gemma 3nthe same embedding can directly power the compact retrieval pipeline of the local rag system and benefit from avoiding cloud inference.
Which tools and frameworks support embedded games?
It has:
- Hug the face (Transformers, sentence converters, Transformers. JS)
- Langchain and Llamaindex For rag pipes
- Weaving and other vector databases
- ONNX runtime For cross-platform optimization deployment
The ecosystem ensures that developers can plug it directly into existing workflows.
How to implement it in practice?
(1) Load and embed
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("google/embeddinggemma-300m")
emb = model.encode(["example text to embed"])
(2) Adjust the embedded size
Use the full 768 DIM for maximum accuracy, or truncate to 512/256/128 DIM for lower memory or faster retrieval speeds.
(3) Integrate into the rag
Run a similarity search locally (cosine similarity) and feed the highest result into Gemma 3n Represents a generation. This makes a full Offline rag pipe.
Why embed the game?
- Large-scale efficiency – Compact footprints with high multilingual retrieval accuracy.
- flexibility – Adjustable embed size via MRL.
- privacy – End-to-end offline pipes have no external dependencies.
- Accessibility – Open weights, loose licensing and strong ecosystem support.
The embedding device proves this Smaller embedding models enable first-class retrieval performance It is also enough to send offline deployments. It marks an important step towards efficient, privacy-conscious and scalable AI in device.
Check Model and technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


