Google AI proposes new machine learning algorithms for differential private partition selection
Differential privacy (DP) is the gold standard for protecting user information in large-scale machine learning and data analytics. A key task in DP is Partition selection– The process of securely extracting the most possible unique items from large user-limited data sets such as queries or document tokens while maintaining strict privacy guarantees. A team of researchers from MIT and Google AI research proposes novel algorithms for differential private partition selection, a way to maximize the number of unique items selected from a group of data while strictly retaining differential privacy at the user level
Partition selection issues in differential privacy
Partition selection is centered on this: How do we reveal as many different items as possible from the dataset without risking any personal privacy? Only one user knows that the project must be kept secret; only those with sufficient “crowdsourcing” support can be disclosed safely. This question is the basis of key applications, such as:
- Private vocabulary and N-gram extraction for NLP tasks.
- Classified data analysis and histogram calculation.
- Privacy learning of embeddings for user-provided projects.
- Anonymous statistical queries (for example, search engines or databases).
Standard Methods and Limitations
Traditionally, the preferred solution (deployed in libraries like PYDP and Google’s Dinialial privacy kit) involves three steps:
- Weighted: Each project receives a “score”, usually between users, and the contribution of each user is strictly closed.
- Increased noise: To hide precise user activity, random noise (usually Gaussian) is added to the weight of each item.
- Threshold: Only the items of noise score are passed through the set threshold of release (calculated according to the privacy parameters (ε, δ)).
This approach is simple and highly feasible and can be scaled to huge datasets using systems like MapReduce, Hadoop, or Spark. However, it is inefficient: popular items accumulate too much weight, which does not contribute to privacy, while fewer and potentially valuable items are often missed because excessive weight is not redirected to help them cross the threshold.
Adaptive weighting and MaxadaptiveEgree (MAD) algorithm
Google’s research is introduced The first adaptive, feasible partition selection algorithm–Maxadaptivedegree (Crazy)– and a multi-round expansion MAD2R designed for truly huge data sets (ten billions of entries).
Key technical contributions
- Adaptive reweighting: MAD identifies items with weights that are much higher than the privacy threshold, rescheduling too much weight to enhance less representative items. This “adaptive weighting” increases the possibility of revealing rare but distributable items, thus maximizing the output utility.
- Strict privacy guarantee: Resettlement mechanism maintenance Exactly the same sensitivity and noise requirements As a classic uniform weighting, ensures user level (ε, δ) under the central DP model – differential privacy.
- Scalability: MAD and MAD2R only require linear work of dataset size and a constant number of parallel bombs to make them compatible with a large number of distributed data processing systems. They do not need to comply with all data in memory and support efficient multi-machine execution.
- Multi-round improvement (MAD2R): By separating the privacy budget in the first round and using noisy weights to the second round to the second round, the MAD2R further improves performance, allowing safely extracting more unique items, especially in a typical real-world long-tail distribution.
Crazy way of working – Algorithm details
- Initial uniform weight: Each user shares their items with uniform initial scores, ensuring sensitivity boundaries.
- Too much weight cuts off and rearranges: The item above the Adaptive Threshold trims its excessive weight and returns proportionally to the contributing user, which is then reassigned to other items.
- Final weight adjustment: Additional even weight was added to make up for small initial distribution errors.
- Increase noise and output: Gaussian noise was added; the item above the noisy threshold is the output.
In MAD2R, the first round output and noisy weights are used to refine which items should be focused on in the second round, weight bias ensures no privacy losses and further maximizes the output utility.
Experimental results: state-of-the-art performance
Extensive experiments were conducted across nine datasets (from Reddit, IMDB, Wikipedia, Twitter, Amazon, all the way to normal crawling, nearly trillion entries) showing:
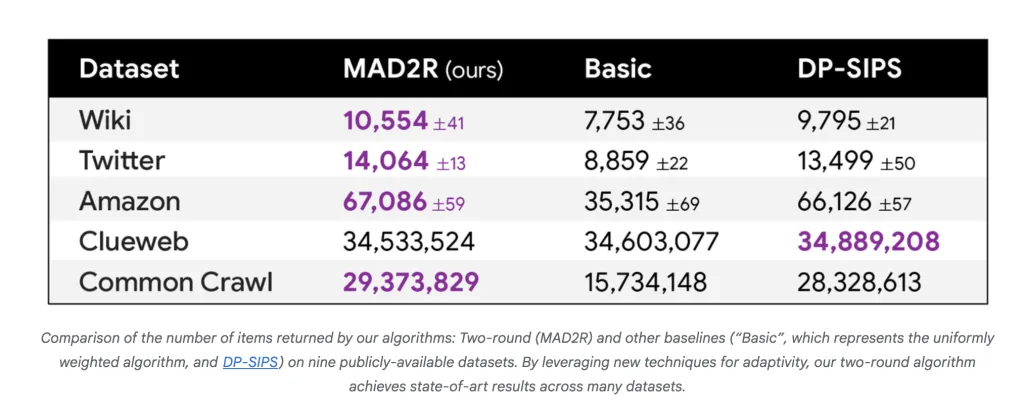
- MAD2R is better than all parallel baselines (Basic, dp-sips) out of the number of items output under fixed privacy parameters, there are seven in nine datasets.
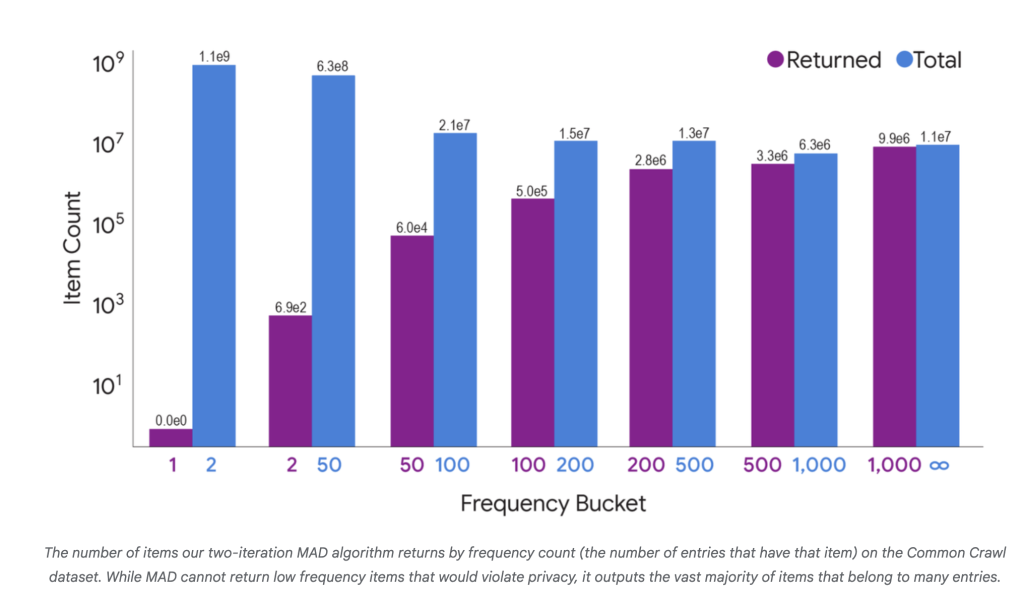
- exist Common crawling Dataset, MAD2R extracted 16.6 million of 1.8 billion unique items, but covered 99.9% Users and 97% In the data, all user items are in the same way as holding the privacy line, significant utility is shown.
- For smaller datasets, MAD is close to the performance of a continuous, non-easy algorithm, and for large datasets it obviously wins both in speed and in utility.
Specific example: Utilities Gap
Consider a scheme with a “heavy” project (usually shared) and many “light” projects (few users share). Basic DP Choice Overweight Make heavy items overweight without lifting enough light to pass the threshold. Crazy repositioning from a strategic perspective increases the output probability of light projects, with as many as 10% unique projects found compared to the standard method.
Summary
Through adaptive weighting and parallel design, the research team brought DP partition selection to new heights of scalability and utilities. These advances ensure that researchers and engineers can make full use of private data and extract more signals without compromising the privacy of individual users.
Check blog and Technical documents are here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


