Google AI proposes an inference library: a policy-level I proxy storage framework that enables LLM proxy to evolve itself at test time
How do you make LLM agents actually learn from their own runs – Success and Failed – No retraining? Google Research propose reasoning bank, An AI proxy storage framework that converts the proxy’s own interaction trajectory –Success and failure– Reusable, advanced Reasoning strategy. These strategies were retrieved to guide future decisions and repeated cycles Self-development. Plus Memory Aware Test Time Scaling (Matt)method provided Relative effectiveness growth of up to 34.2% and –Reduce interactive steps by 16% Cross network and software engineering benchmarks compared to previous memory designs that store raw trajectories or only successful workflows.
So, what’s the problem?
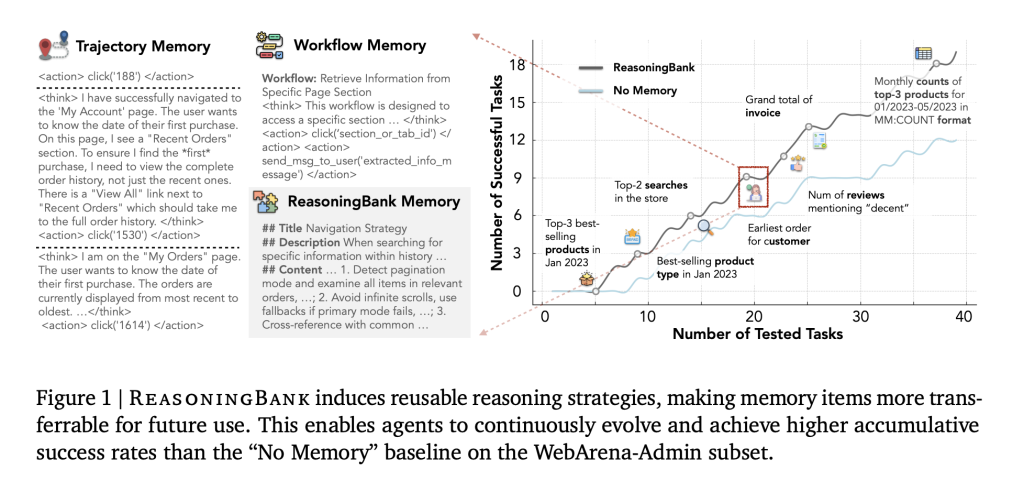
LLM Agent handles multi-step tasks (web browsing, computer usage, reply-level bug fixes), but usually Unable to accumulate and reuse experience. Regular “memory” tends to hoard logs or rigid workflows. These are fragile across environments and are often ignored from fail– Many viable knowledge life. The inference library reframes the memory into Compact, readable strategy project It is easier to transfer between tasks and domains.
Then how to shovel?
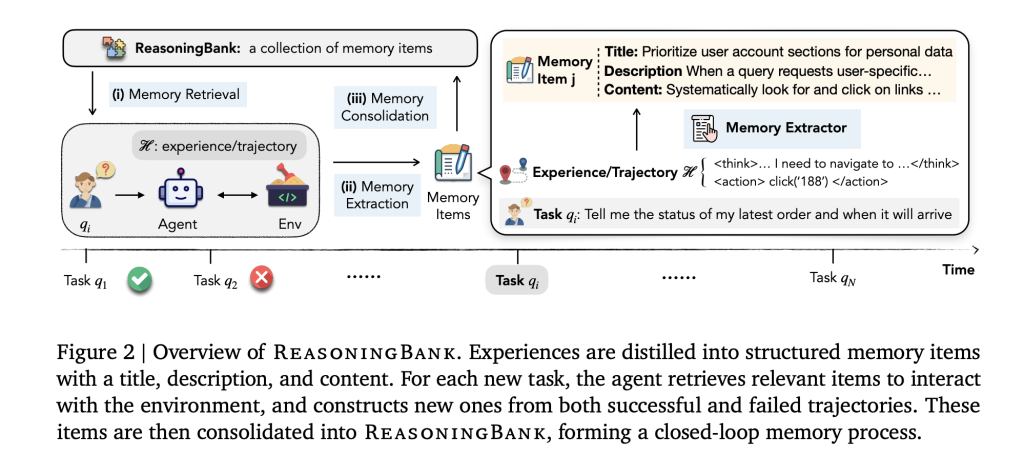
Each experience is distilled into one Memory entry Have a title, a line of description and content included The principle of feasibility (heuristics, checks, constraints). Search is Embed based: For a new task, inject TOP-K related projects into System guidance;After execution, extract the new project and merge Back. The cycle is intentionally simple – retrieve → injection → judge → evaporation → add – therefore, the improvement can be attributed to Abstraction of strategynot heavy memory management.
🚨 [Recommended Read] Vipe (Video Pose Engine): A powerful and universal 3D video annotation tool for space AI
Why transfer: Project code Reasoning mode (“Preferring priority to using account pages for specific user data; Verifying paging mode; Avoiding unlimited scrolling traps; Cross-checking status with task specifications”) rather than the DOM steps for a specific website. Failed to be Negative constraints (“Do not rely on search when the website disables indexing; confirm the save status before navigation”), this prevents duplicate errors.
Test time scaling of memory consciousness is also proposed (Matt)Woolen cloth
Test time scaling (more rollouts or refinements per task) is only valid if the system can Learn from extra trajectories. The research team also proposed Memory Aware Test Time Scaling (Matt) Integrate scaling with inference library:
- Parallel matte: Generate (k) in parallel, then Self-comparison They optimize strategy memory.
- Sequence matte: Iteration Self refine Single track, mining intermediate notes as memory signals.
Synergy is two-way: richer exploration produces better memories; better memories turn to exploration of promising branches. From an empirical point of view, fat people produce Stronger, more monotonous growth The best n than vanilla without memory.
So, how good are these proposed research frameworks?
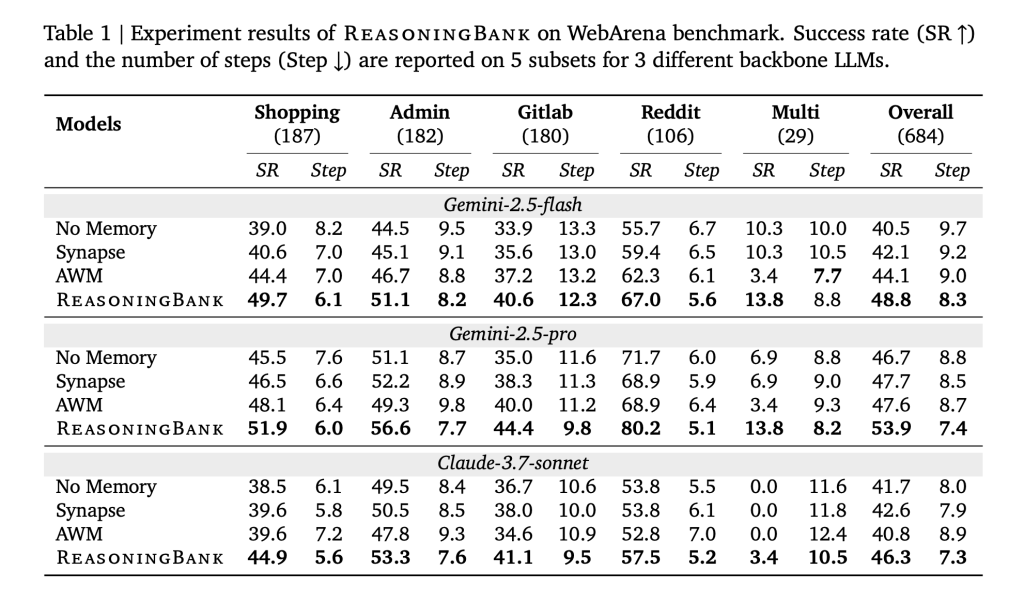
- Effective: Reasoning Bank + Matz improves mission success Up to 34.2% (relative) In the absence of memory, it is better than a prior memory design that reuses original traces or only successful routines.
- efficiency: Interactive steps fall 16% Comprehensive; further analysis shows Maximum reduction in successful trialsindicating less redundant actions than premature interruptions.
This applies to the location of the proxy stack?
The reasoning library is a Plugin memory layer For interactive agents that have used reactive decision loops or optimal N test time scaling. It will not replace validators/planners; enlarge By Prompt/System grade. On web tasks, it supplements browsergym/webarena/mind2web; on software tasks, it layer by layer on SWE-Bench verification settings.
Check The paper is here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter. wait! Are you on the telegram? Now, you can also join us on Telegram.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


