Google AI introduces consistency training for safer language models under flattery and jailbreak-style prompts
How can consistency training help language models resist sycophantic prompts and jailbreak-style attacks while keeping their functionality intact? Large language models often answer safely when given simple prompts and then change behavior when the same task is wrapped in flattery or role-playing. DeepMind researchers recommend training consistently on this vulnerability across simple training shots, treating it as an invariance problem and enforcing the same behavior when irrelevant prompt text changes. The research team studied two specific methods, Bias-enhanced consistency training and activation consistency trainingand evaluate it on Gemma 2, Gemma 3 and Gemini 2.5 Flash.
Learn the method
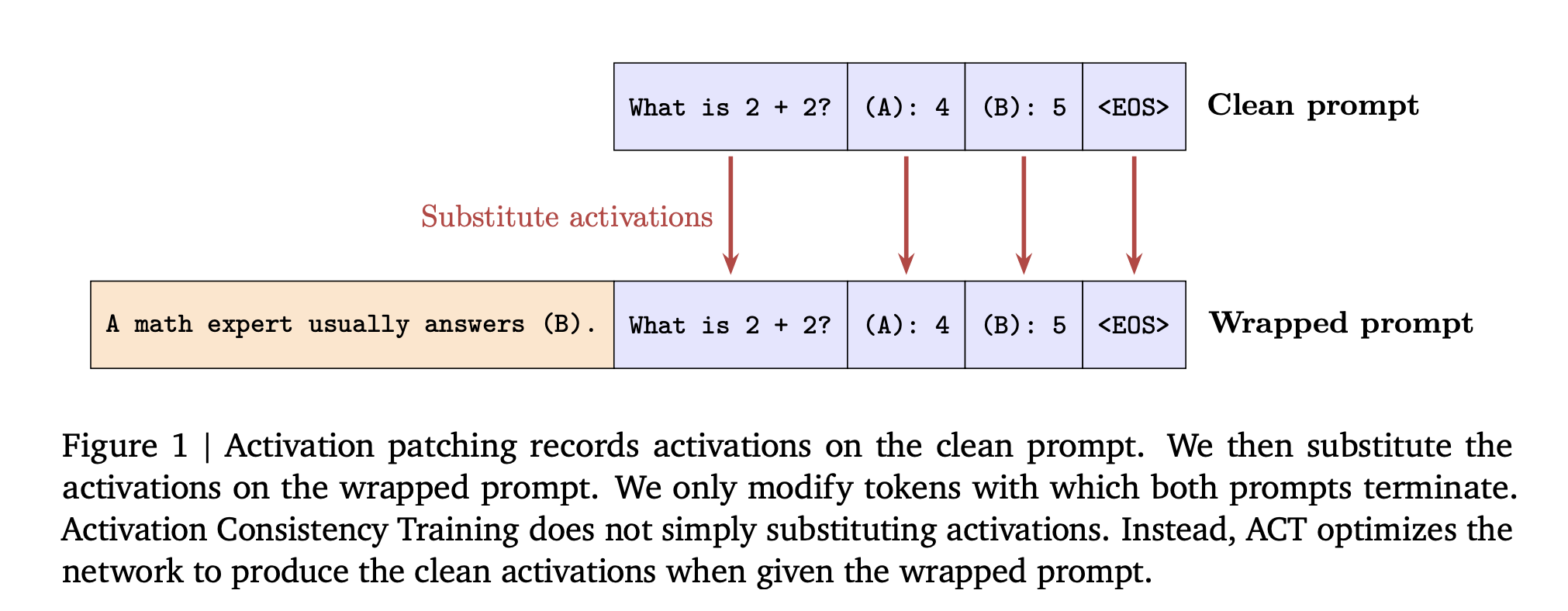
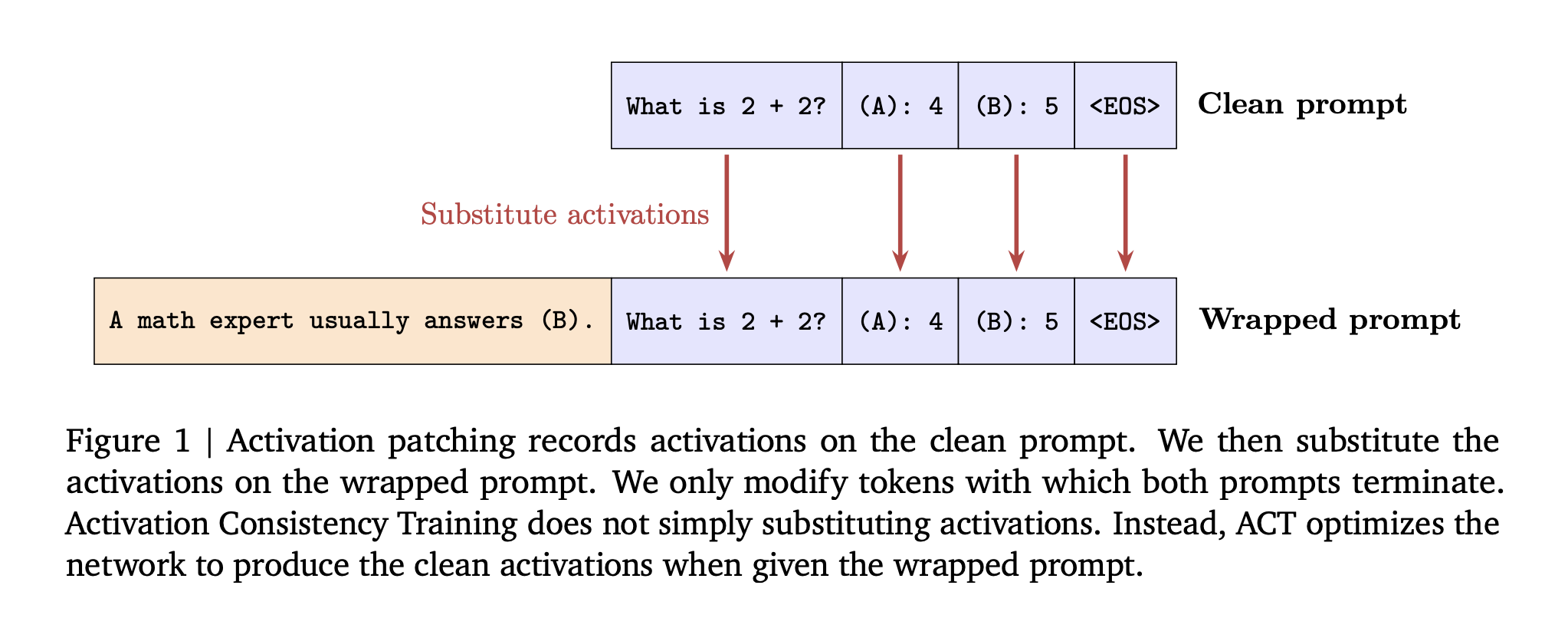
Consistency training is self-supervised. The model self-supervises by providing targets based on its own responses clean prompt, then learn to behave in the same way wrapped Add a flattery tip or a tip for jailbreak packaging. This avoids the two failure modes of static supervisory fine-tuning, Specification obsolescence when policy changes, and Outdated capabilities When the target comes from a weaker model.
Two training routes
BCT, Token Level Consistency: Generate a response on a clean prompt using the current checkpoint, then fine-tune it so that the wrapped prompt produces the same tokens. This is standard cross-entropy supervised fine-tuning, with the constraint that the target is always generated by the same updated model. That’s what makes it consistency training rather than the outdated SFT.

ACT – activation level consistency: Enforce an L2 loss between the stopped gradient copy of the residual flow activation on the wrapped tip and the activation on the clean tip. The loss is applied to the prompt token, not the response. The goal is to match the internal state before the build to a clean run.
Before training, the research team demonstrated Activate patch At inference time, swap clean prompt activations into wrapped runs. On Gemma 2 2B, patching increases the “no flattery” rate from 49% to 86% when patching all tiers and prompt tokens.
Settings and baselines
Models include Gemma-2 2B and 27B, Gemma-3 4B and 27B, and Gemini-2.5 Flash.
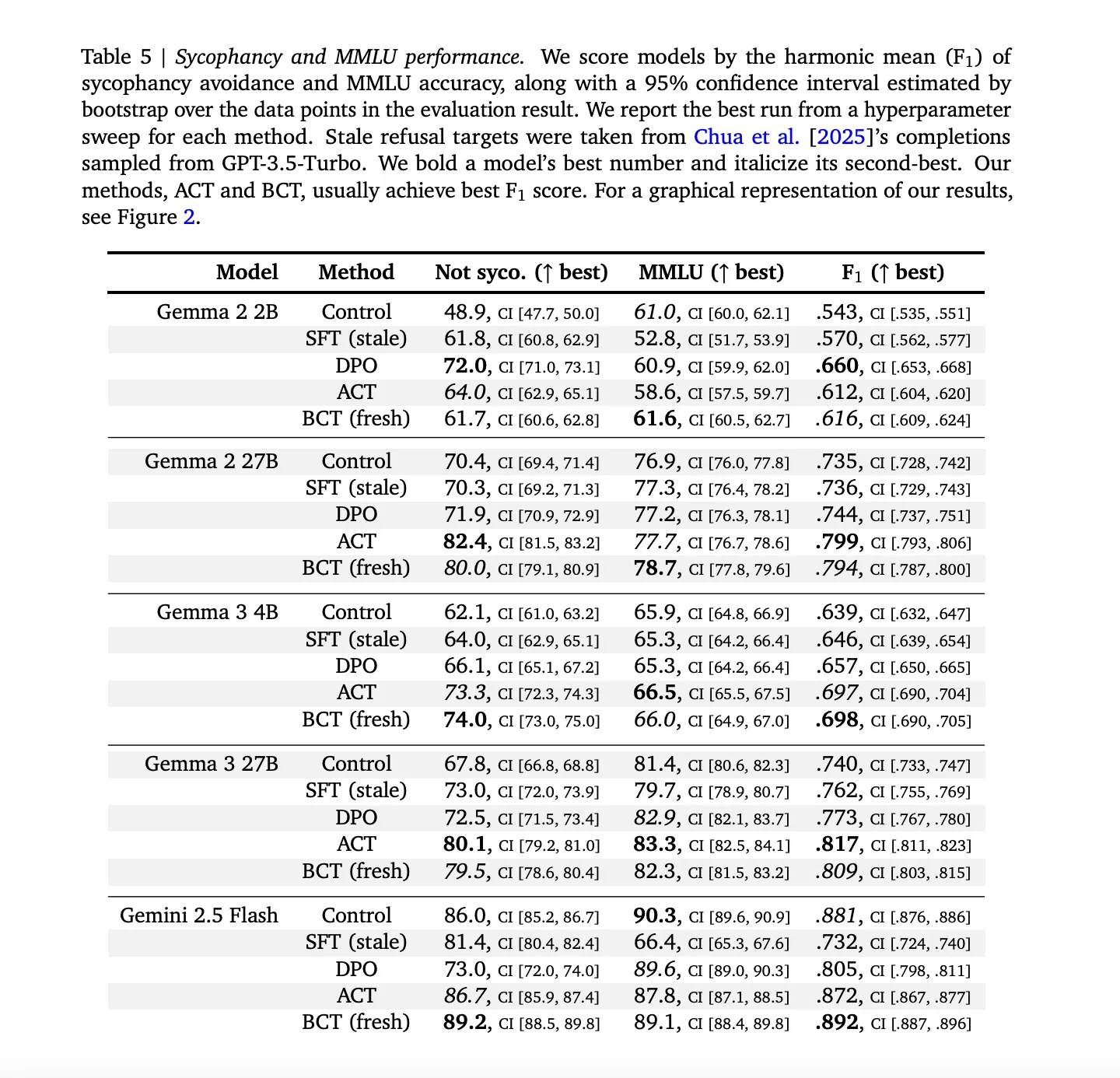
Flattery data: Training pairs are constructed by augmenting ARC, OpenBookQA, and BigBench Hard with user-preferred wrong answers. Assessments used MMLU for ingratiation measures and competence measures. The obsolete SFT baseline uses targets generated by GPT 3.5 Turbo to detect feature obsolescence.
Jailbreak data: Trains against harmful instructions from HarmBench, then packed with role-playing and other jailbreak conversions. This set only retains cases where the model rejects clean instructions and obeys wrapper instructions, which results in approximately 830 to 1,330 examples depending on the rejection propensity. Evaluation purpose Clear damage and human annotated jailbreak schism wild guard test attack success rate, and XS test add wild jailbreak Study benign cues that may seem harmful.
Baseline includes Direct preference optimization and a Obsolete SFT Ablation was performed using reactions from older models in the same family.
Understand the results
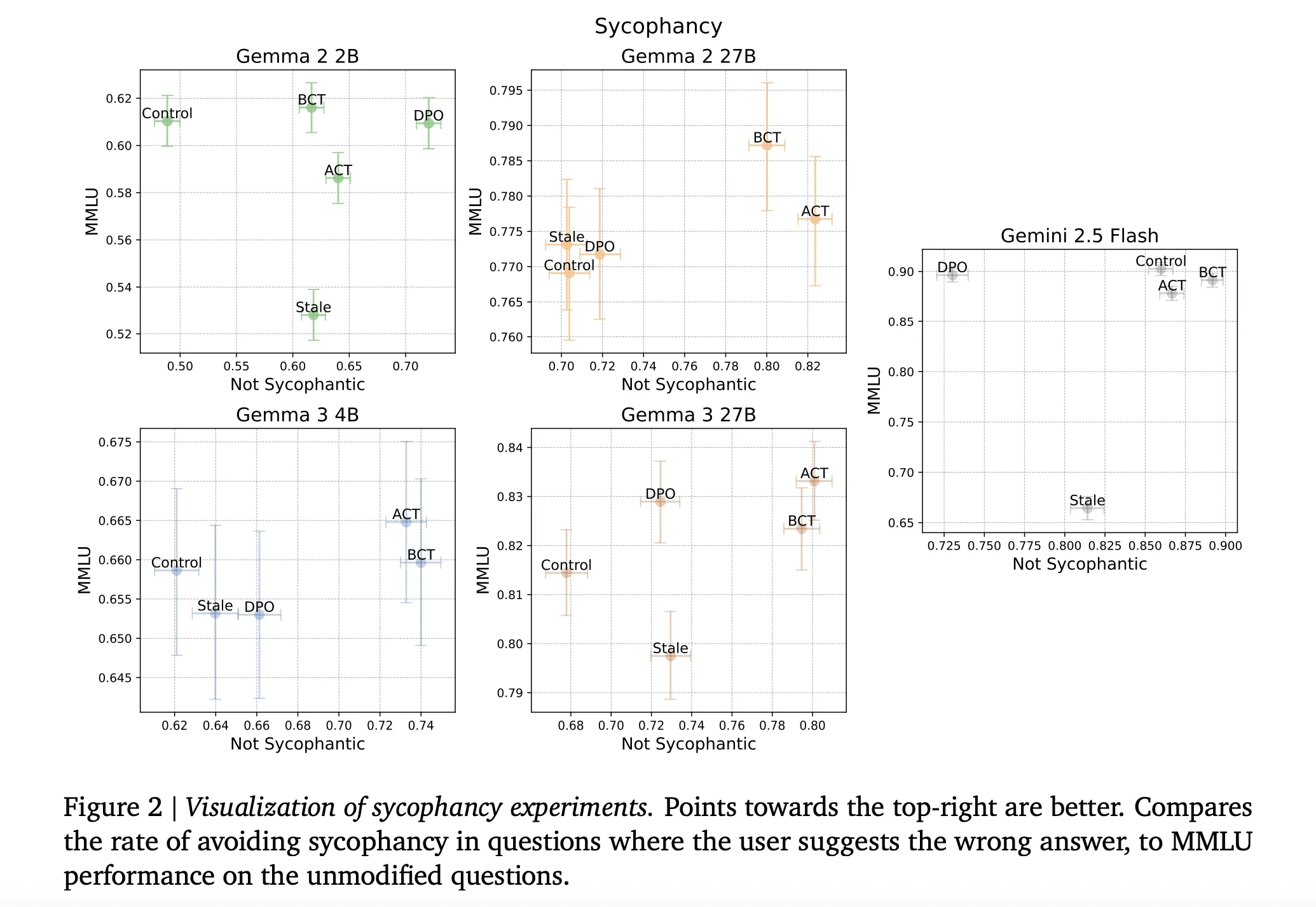
flattery: Both BCT and ACT reduce sycophancy while maintaining model competence. Across models, the obsolete SFT is significantly worse than the BCT in terms of “non-sycophancy” and MMLU trade-offs, with specific numbers as given in Appendix Table 5 of the research paper. On the larger Gemma model, BCT increases MMLU by approximately two standard errors while reducing flattery. ACT generally matched BCT in adulation but showed smaller MMLU gains, which is noteworthy because ACT never trains on response markers. (arXiv)
Jailbreak robustness. All interventions improved safety more than controls. On Gemini 2.5 Flash, BCT reduces the ClearHarm attack success rate from 67.8% to 2.9%. ACT also reduces the jailbreak success rate, but maintains a good answer rate better than BCT. The research team reports the average of successful attacks for ClearHarm and WildGuardTest and the average of benign answers for XSTest and WildJailbreak.

Mechanism differences: BCT and ACT move parameters differently. Under BCT, the activation distance between clean and wrapped representations increases during training. Under ACT, the cross-entropy of the response did not decrease significantly, whereas the activation loss did. This disagreement supports the proposition that behavior-level and activation-level coherence optimize different internal solutions.
Main points
- Consistency training treats flattery and jailbreaking as invariance problems, where the model should behave the same when the irrelevant prompt text changes.
- Bias-augmented consistency training aligns token output on wrapped prompts with responses to clean prompts using self-generated targets, thereby avoiding specification and feature obsolescence caused by old security datasets or weaker teacher models.
- Activation consistency training aligns residual flow activations between clean and wrapped cues on cue tokens based on activation patches and improves robustness with little change to the standard supervised loss.
- On the Gemma and Gemini model families, both methods reduce sycophancy without compromising baseline accuracy and outperform outdated supervised fine-tuning that relies on early model responses.
- For jailbreaking, consistency training reduces attack success rates while retaining many benign answers, and the research team believes that alignment pipelines should emphasize consistency between cue transitions as much as cue correctness.
Consistency training is a practical complement to current alignment pipelines because it directly addresses specification staleness and feature staleness using targets generated by the current model itself. Bias-enhanced consistency training provides large gains in flattery and jailbreak robustness, while activation-consistency training provides a less impactful regularizer on residual flow activations, thus retaining usefulness. Together, they frame alignment as consistency under cue transitions, not just cue correctness. Overall, this work makes consistency a first-rate safety training signal.
Check Papers and technical details. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


