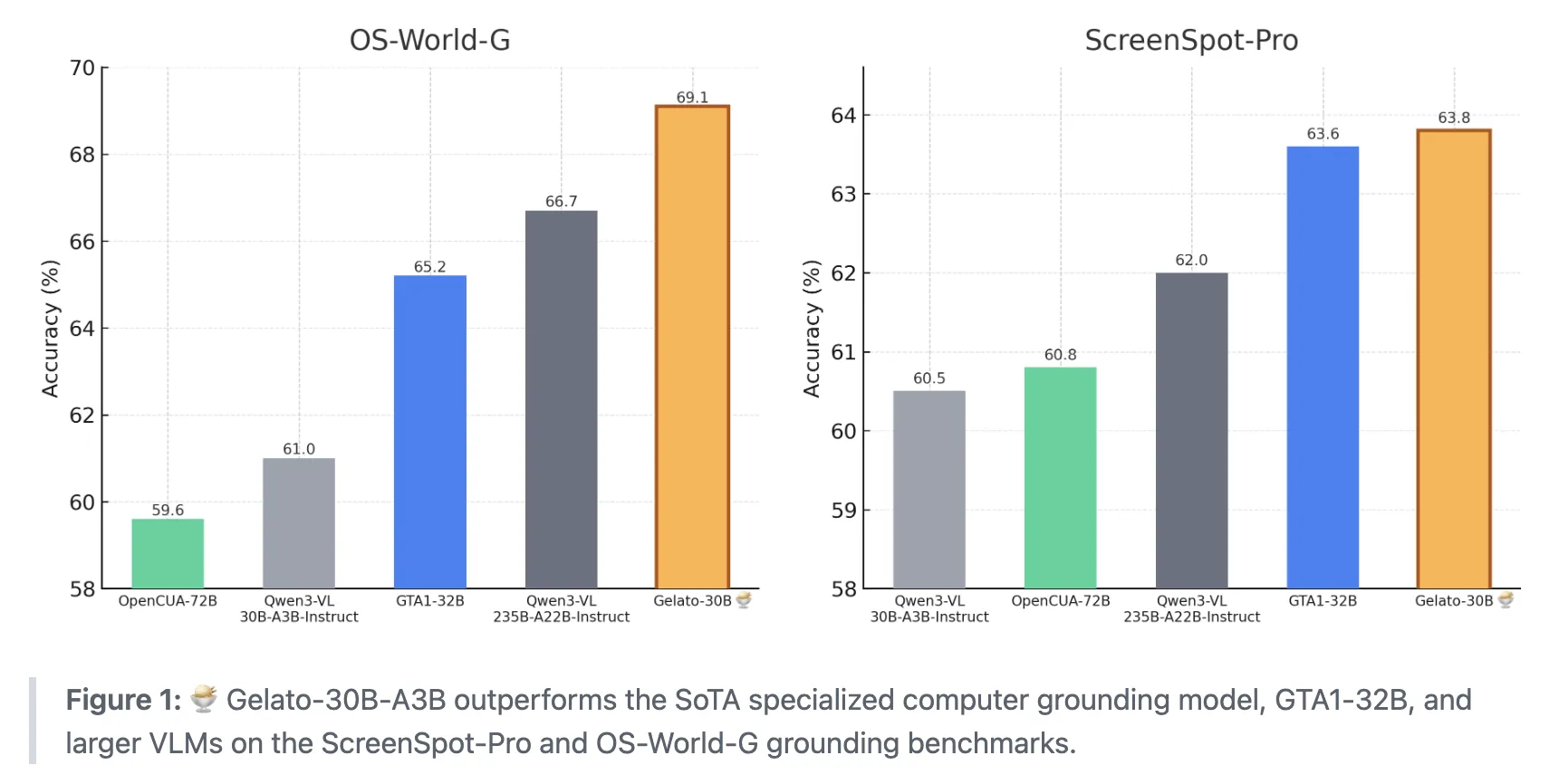
Gelato-30B-A3B: The most advanced ground model for GUI computer usage tasks, surpassing computer ground models such as GTA1-32B
When we give an AI agent a simple instruction, how do we teach them to reliably find and click on the exact element on the screen we’re pointing to? A team of researchers at ML Foundations has unveiled Gelato-30B-A3B, a state-of-the-art graphical user interface foundation model designed to plug into computer usage agents and convert natural language instructions into reliable click locations. The model was trained on the Click 100k dataset and achieved 63.88% accuracy on ScreenSpot Pro, 69.15% accuracy on OS-World-G, and 74.65% accuracy on OS-World-G Refined. It surpasses GTA1-32B and larger visual language models such as Qwen3-VL-235B-A22B-Instruct.
What role does Gelato 30B A3B play in the agent stack?
Gelato-30B-A3B is a 31B parameter model that can be fine-tuned to the Qwen3-VL-30B-A3B Instruct via a hybrid expert architecture. It takes screenshots and text instructions as input and generates click coordinates as output.
This model is positioned as a modular ground assembly. A planner model (such as GPT 5 in the Gelato experiment) determines the next high-level action and calls Gelato to parse that step into a specific click on the screen. The separation between planning and foundation is important when agents must operate across multiple operating systems and applications with different layouts.
Click 100k, GUI-based target dataset
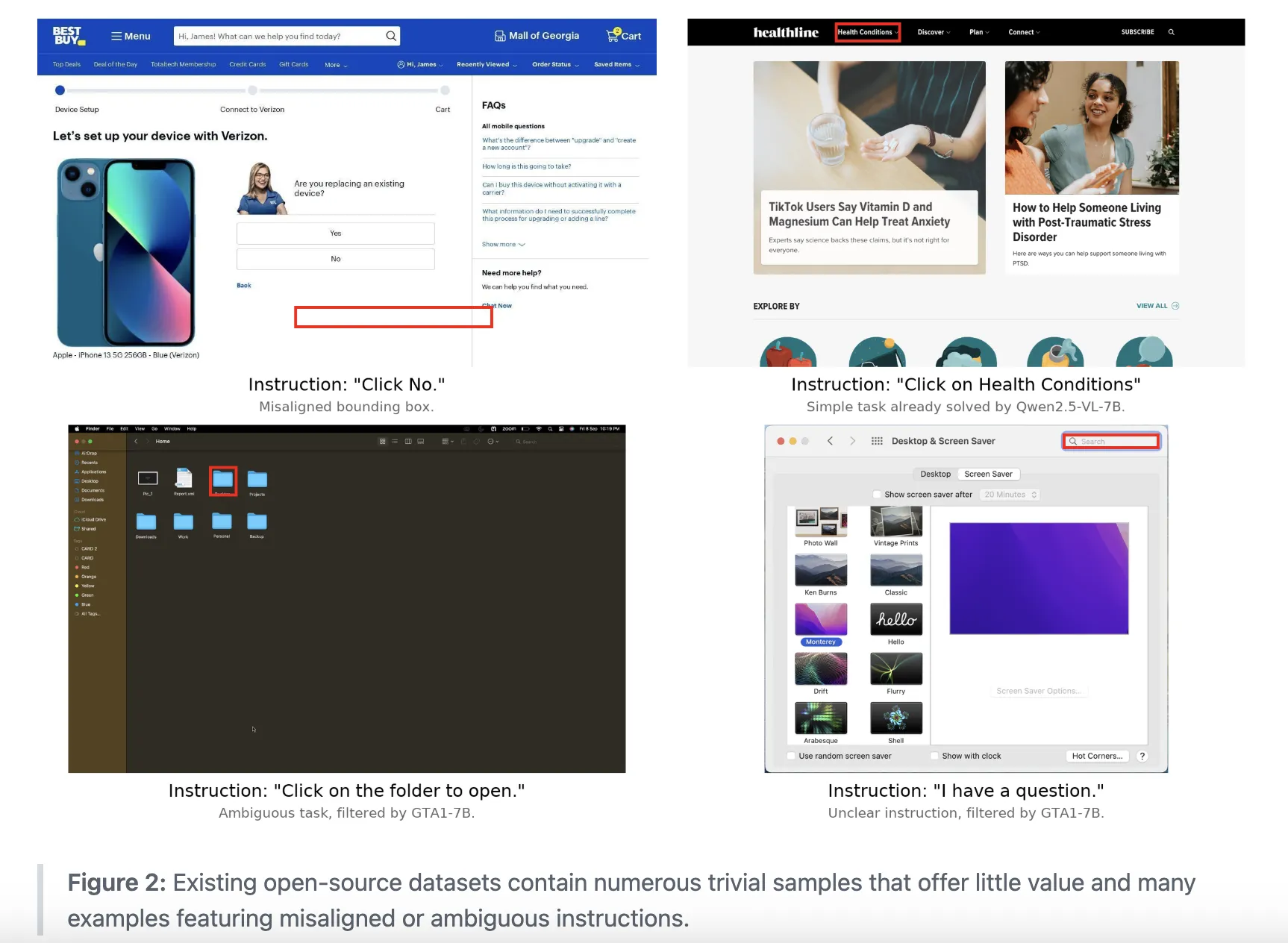
Click 100k is the data set behind Gelato. It pairs a computer screen image with natural language instructions, the bounding box of the target element, the image dimensions, and the normalized bounding box. Each example is set up as a low-level command, such as “Click an element between the background and notification options” with a precise area.
The dataset was built by filtering and unifying multiple public sources. The list includes ShowUI, AutoGUI, PC Agent E, WaveUI, OS Atlas, UGround, PixMo Points, SeeClick, UI VISION, a JEDI subset focused on spreadsheet and text cell manipulation, and videos from 85 professional application tutorials annotated with Claude-4-Sonnet. Each source contributes up to 50k samples, and all sources are mapped to a shared schema containing images, instructions, bounding boxes, and normalized coordinates.
The research team then ran an active filtering pipeline. OmniParser discards clicks that do not land on detected interface elements. Qwen2.5-7B-VL and SE-GUI-3B removed simple examples such as simple hyperlink clicks. GTA1-7B-2507 and UI-Venus-7B deleted samples that did not match the command and click area. The Qwen2.5-7B-VL baseline trained on a balanced 10k subset shows that this combination provides a +9 pp accuracy gain on ScreenSpot Pro compared to training on unfiltered data.
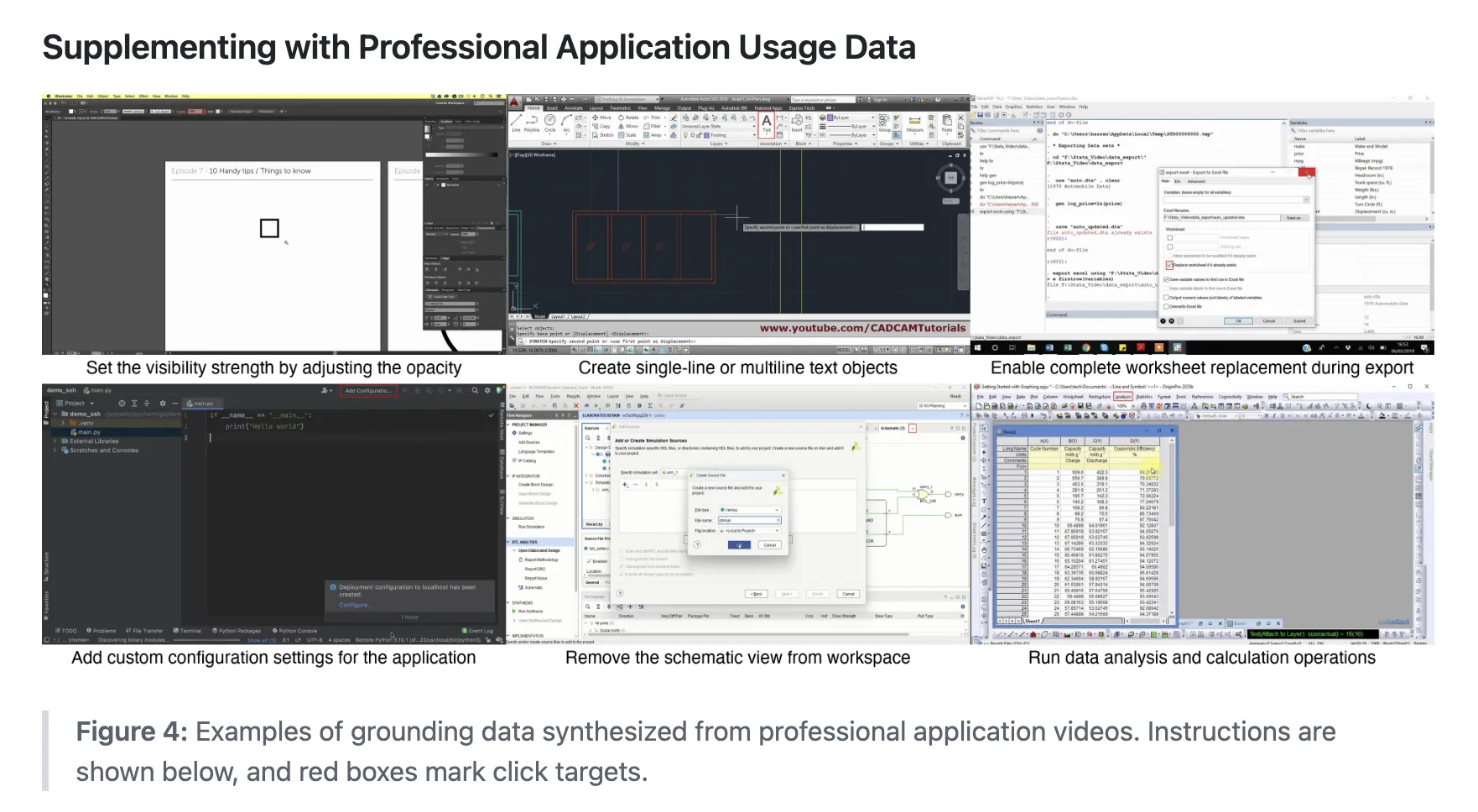
Professional application coverage is a specific focus. Click 100k adds data from UI VISION and JEDI subsets, then augments it with more than 80 tutorial videos of real desktop tools. Claude 4 Sonnet generates bounding boxes and low-level instructions for these videos, which are then manually inspected and corrected.
GRPO training based on Qwen3 VL
For training, the Gelato 30B A3B uses GRPO, a reinforcement learning algorithm derived from DeepSeekMath and similar systems. The research team followed the DAPO setup. They removed the KL divergence term from the target, set the clipping upper threshold to 0.28, and skipped the rollout with zero advantage. Rewards are small and are only given when the predicted click falls within the target bounding box, similar to GTA1’s recipe.
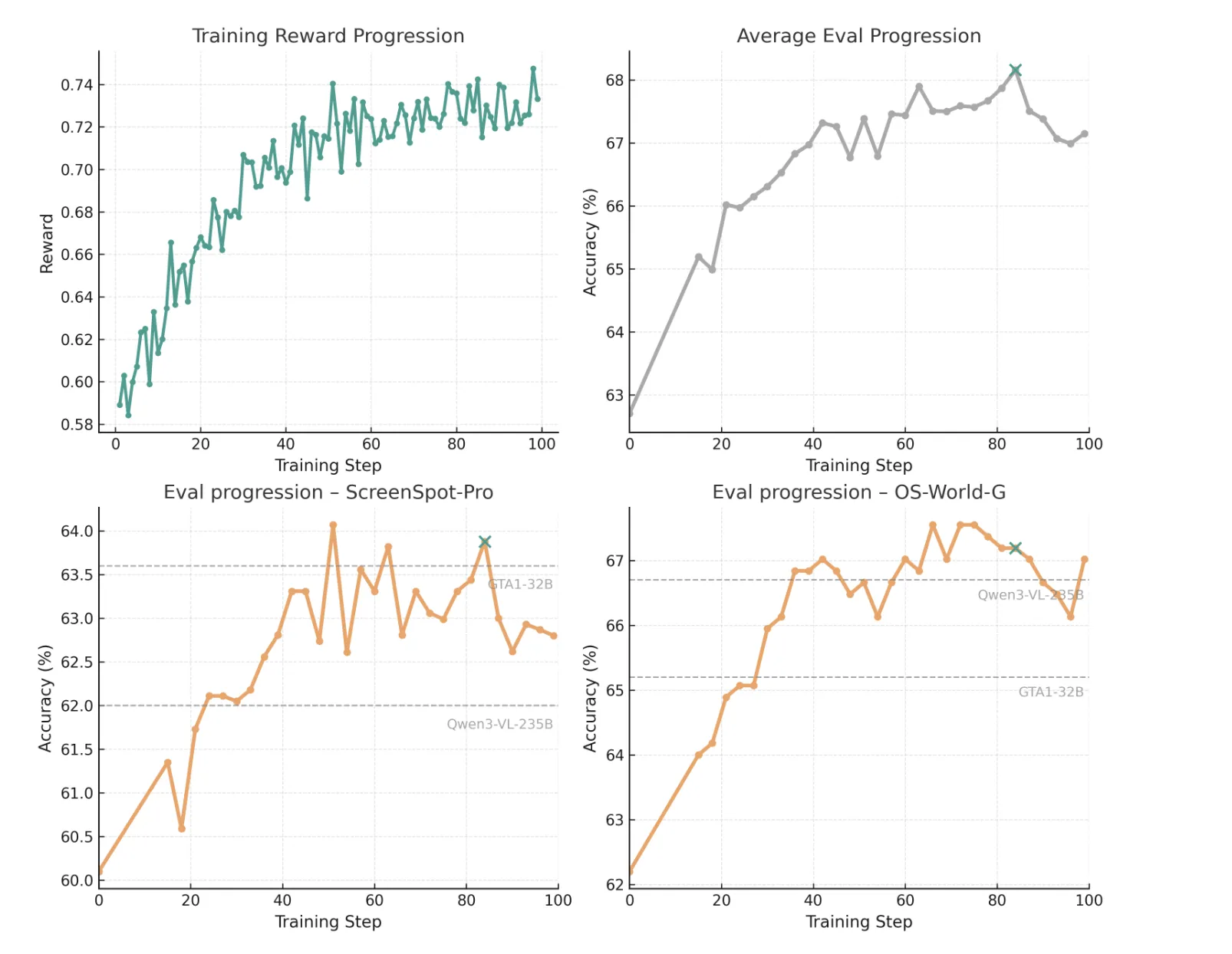
They are initialized from Qwen3 VL 30B A3B and run for 100 RL steps on 32 A100 GPUs with 40 GB of memory. The best checkpoint occurs at step 84 (marked with a green cross in the image above), chosen based on the average performance of ScreenSpot Pro, OS World G, and OS World G Refined. At this time, the model achieved 63.88% on ScreenSpot-Pro, 67.19% on OS World G and 73.40% on OS World G Refined. A simple reject-prompt strategy, which appends a reject-answer instruction when an element is not found, increases the OS-World-G scores to 69.15% and 74.65%.
End-to-end proxy results on OS World
To test Gelato beyond a static grounded baseline, the research team plugged it into the GTA 1.5 agent framework and ran a full computer usage agent in the OS World environment. In this setup, GPT 5 acts as the planner. Gelato 30B A3B provides grounding, agent has up to 50 steps and waits 3 seconds between operations.
The study reports that each model was run three times on a fixed operating system world snapshot. The automation success rate of Gelato-30B-A3B reaches 58.71% with a small standard deviation, while the automation success rate of GTA1 32B in the same harness is 56.97%. Because the automated OS World evaluation missed some valid solutions, they also conducted a manual evaluation of 20 problematic tasks. Under human ratings, Gelato’s success rate reached 61.85%, while GTA1-32B achieved 59.47%.
Main points
- Gelato-30B-A3B is an expert hybrid model based on the Qwen3-VL-30B-A3B Instruct that performs state-of-the-art GUI fundamentals on ScreenSpot Pro and OS World G benchmarks, surpassing GTA1-32B and larger VLMs such as the Qwen3-VL-235B-A22B-Instruct.
- The model is trained on Click 100k, a curated base dataset that merges and filters multiple public GUI datasets and specialized application traces to pair real screens with low-level natural language commands and precise click coordinates.
- Gelato-30B-A3B uses the GRPO reinforcement learning formulation on top of Qwen3-VL, with sparse rewards only triggered when the predicted click is within the ground-truth bounding box, which significantly improves the grounding accuracy of the supervised baseline.
- When integrated into an agent framework with GPT-5 as the planner, Gelato-30B-A3B improved the success rate of OS World computer usage tasks compared to GTA1-32B, demonstrating that a better foundation can directly translate into stronger end-to-end agent performance.
Gelato-30B-A3B is an important step forward for grounded computer use, as it shows that Qwen3-VL-based MoE models, trained on the carefully filtered Click 100k dataset, can beat GTA1-32B and larger VLMs (such as ScreenSpot Pro and Qwen3-VL-235B-A22B Instruct on OS-World-G) while maintaining through Hugging Face accessibility. Overall, the Gelato-30B-A3B sets a clear new benchmark for open computer grounding models.
Check repurchase agreement and Model weight. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


